Multi-Site RonDB#
RonDB is designed for Local Area Network (LAN) environments. It is possible to have nodes a few kilometers away from each other and still get a good user experience as is the case within a cloud region.
There are several reasons to make use of multiple clusters that contain the same data. Each cluster uses synchronous replication between nodes in the cluster. Global Replication uses asynchronous replication between the clusters.
A few reasons to use Global Replication are:
-
Surviving natural disasters
The application must be able to survive earthquakes and other drastic problems that can impact a large area, including local conflicts and disruptions that affect larger areas than a LAN or cloud region covers.
For the highest availability, it is of utmost importance to have availability beyond what a single cluster can provide.
This is the reason many of the high-profile users of NDB use Global Replication. A telecom operator cannot accept that the phone service or mobile internet service is disrupted completely by one catastrophic event. The application has to be built to handle such catastrophic events.
-
Supporting advanced cluster changes
The application needs 100% uptime in all types of software upgrades. Many applications upgrade not only the DBMS when upgrading, they might decide to upgrade their application and they might even decide to move one data center from one place to another. A fail-over cluster can be very useful in all of those cases.
RonDB is designed to handle most software changes without downtime. But there are still some things we don’t support that might be needed such as an online drop column. In this case, another cluster can be used to perform an online upgrade. Next, the clusters are swapped and the first cluster is brought online. At last, the second cluster can be brought down to upgrade that as well.
-
Low latencies for global applications
Global Replication can be used to build a true globally distributed database where updates can be performed in any cluster anywhere in the world. Given the latency between systems on a global scale, it is not possible to wait for commits until all clusters have accepted the transaction. Instead, we use a conflict detection scheme. RonDB supports several different conflict detection schemes.
The globally distributed database setup can be used in companies that operate over multiple continents and need a cluster on each continent that can act as a primary cluster.
Even with a single primary cluster, one can use conflict detection to ensure that failover to a new primary cluster can be done without downtime. In this case, the conflicts only occur in the short time that two clusters are both primary clusters.
-
Replication to a different storage engine of MySQL
We will not cover this explicitly here. It should however be straightforward to do with the descriptions in this chapter.
MySQL Replication#
The asynchronous replication between clusters is built on top of MySQL Replication. It reuses most of the basic things about MySQL Replication such as a binlog, a relay log, source MySQL Servers and replica MySQL Servers. There is a set of differences as well.
First of all, RonDB only supports row-based replication. The meta data changes are replicated using statements, but all data changes are replicated using row changes.
The row changes are not generated in the MySQL Server (remember that RonDB can be accessed also from NDB API applications), rather they are generated inside the data nodes. The data node generates events for row changes and transports them to a specific MySQL Server that handles replication between clusters.
RonDB uses a concept called epochs to transport changes over to the backup cluster. Epochs are a sort of group commit, they group all changes to the cluster committed in the last period (100 milliseconds by default) into one epoch. This epoch is transported to the backup cluster and applied there as one transaction.
MySQL using InnoDB relies on GTIDs to handle replication consistency. RonDB gets its replication consistency from its use of epochs.
In research papers about database replication, there are two main themes on how to replicate. One is the epoch style, which requires only sending over the epochs and applying them to the backup cluster. The actual replication is simpler in this case. The problem with this approach is that one needs to create epochs, this puts a burden on the primary cluster. In RonDB this isn’t a problem since we already have an architecture to generate epochs efficiently through our global checkpoint protocol. Thus using epochs is a natural choice for RonDB.
The other approach has a smaller impact on the source, it instead requires that one keep track of the read and write sets and ensures that the replica applier has access to this information. This is a natural architecture for a DBMS where it is harder to change the transaction architecture to create epochs.
Both architectures have merits and disadvantages. For RonDB, epochs was a very natural choice. For MySQL using InnoDB the approach using GTIDs to serially order transactions (still lacks the read sets) was the more natural approach.
Global Replication supports more features compared to MySQL Replication. The features we support in this area are very advanced. The lead developer in this area took his Ph.D in this area about 20 years ago and presented a distributed replication architecture at the VLDB conference in Rome more than 23 years ago.
This is an area that we have developed in close cooperation with our telecom users. These all require this feature and have built a lot of support functionality around it.
Architecture of Global Replication#
As a first step, we will describe the nodes required to set up replication between clusters. Given that almost all applications of RonDB are high-availability applications, we will only consider setups that have a primary and a backup replication channel. The replication channel will be set up between two RonDB Clusters.
A replication channel connects a source and a replica MySQL Server. Thus having a primary and backup replication channel means that we need at least two source and two replica MySQL Servers.
In active-active architectures, replication goes in both directions. This can be accomplished with the same set of MySQL Servers or it can be accomplished with additional MySQL Servers. There is no difference in this choice. Thus active-active replication can be achieved with four or eight MySQL Servers for two RonDB Clusters. Circular replication (more than two active clusters) however requires four MySQL Servers per RonDB Cluster.
In the optimal design, the MySQL Servers used for replication are only used for replication and schema changes.
Base architecture#
The base architecture is replicating from one RonDB cluster to another RonDB cluster. Here we have a set of data nodes, "normal" MySQL Servers and replication MySQL Servers in each cluster. The following diagram shows the setup.
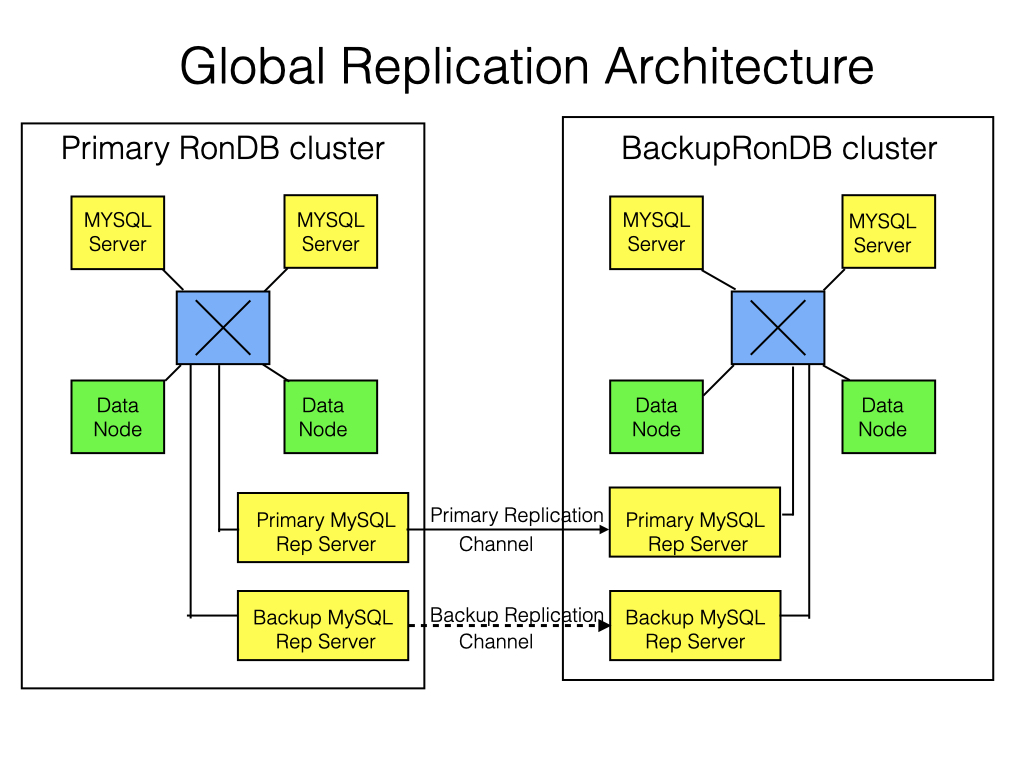
The two replication MySQL Servers in the backup cluster receive events from the primary cluster and store these in their binlog. However, only one of them applies the events to the cluster. The events are sent by one of the MySQL Replication Servers in the primary cluster.
Failover between the primary replication MySQL Server happens on epoch boundaries. Thus if one replication channel fails, the other can deduce which epoch has been applied and start from the next epoch after that.
If the primary cluster fails or if both replication channels fail, we will fail over to the backup cluster. Using epochs this is straightforward. We discover which is the last epoch we received in its entirety and continue from there. The application must also be redirected toward the new primary cluster before the failover is completed.
Active-Standby Clusters#
Active-standby clusters are the most basic configuration used primarily for high availability, complex software upgrades, hardware upgrades and so forth. No conflict detection is required since there is only one active cluster at a time.
Read-Replica Clusters#
In this case, there is no failover handling. The replication is done to increase read throughput. We could have more than one backup cluster.
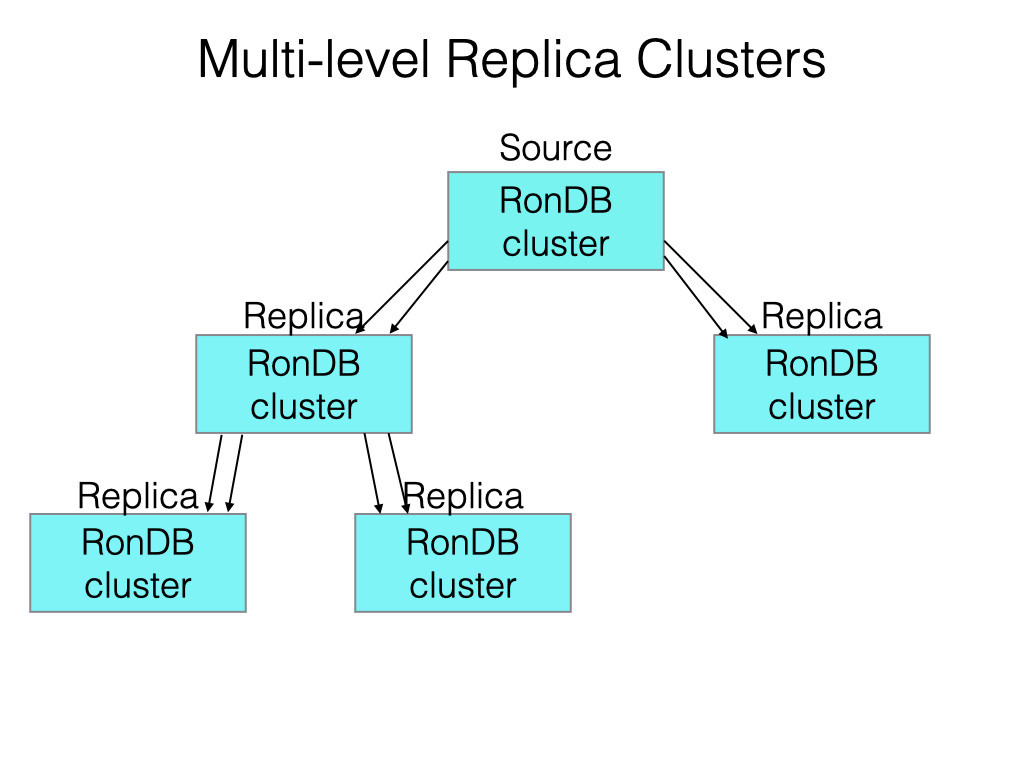
Multi-level Read-Replica Clusters#
With high throughput of writes it can be hard for one primary cluster to replicate to all other backup clusters. In this case, one might have multiple levels of replication.
Thus the primary cluster replicates to a set of clusters, each of those clusters in its turn can replicate onto another set of RonDB Clusters.
Active-Active Clusters#
Active-active clusters replicate in both directions. This means that we can get conflicts. Thus it is important to decide how to handle those conflicts, we will go through the options available in the chapter on globally distributed databases using RonDB and in the chapter on extremely available solutions with RonDB.
A special case of this architecture is when we normally run in Active-Standby mode, but during the failover we run in Active-Active mode. To support this is one of the reasons we support conflict detection in the Active-Active setup.
Circular Active-Active Clusters#
With more than two active clusters, the replication becomes circular. This still requires conflict detection handling. We will cover this in the chapter on globally distributed databases.
Configuration basics#
Each MySQL replication server must have its unique server ID. The
responsibility to make it unique and set up the replication
configuration lies on the DBA. The server ID is set when you start up
the MySQL replication server using the --server-id parameter. The
server ID is a number that must be unique among all the MySQL
Replication servers in a global replication setup. This number is in no
way related to any other number and thus, not related to node IDs. These
numbers can be selected in any fashion.
Tables used by Global Replication#
Global Replication uses a set of internal tables to provide information about replication status. These tables are created when installing a MySQL Server.
The ndb_binlog_index table is an InnoDB table that is local to each MySQL Server used to replicate cluster tables to another cluster or another storage engine.
The ndb_apply_status, ndb_schema and ndb_replication tables are RonDB tables.
All those tables belong to the mysql database.
ndb_binlog_index#
The ndb_binlog_index table contains an index on what has been written in the local binlog in a MySQL Server handling Global Replication. By default, it will contain one row for each epoch that performed changes and has been written to the binlog. This table is created by the MySQL installation program.
The table looks as follows:
CREATE TABLE ndb_binlog_index
(
Position bigint unsigned NOT NULL,
File varchar(255) NOT NULL,
epoch bigint unsigned NOT NULL,
inserts int unsigned NOT NULL,
updates int unsigned NOT NULL,
deletes int unsigned NOT NULL,
schemaops int unsigned NOT NULL,
orig_server_id int unsigned NOT NULL,
orig_epoch bigint unsigned NOT NULL,
gci int unsigned NOT NULL,
next_position bigint unsigned NOT NULL,
next_file varchar(255) NOT NULL,
PRIMARY KEY (`epoch`, `orig_server_id`,`orig_epoch`)
) ENGINE=InnoDB DEFAULT CHARSET=latin1;
The following assumes knowledge of the Global Checkpoint Index (GCI). More on the GCI can be found in the chapter on the Global Checkpoint Protocol.
-
Position: specifies the start position of the epoch in the binlog -
File: the filename of the file where the start position is placed -
epoch: lists the 64-bit id of the epoch number consisting of the 32-bit GCI and a 32-bit micro-GCI. The GCI is also reported in the columngci. -
inserts,updates,deletesandschemaops: count count how many of those operations the epoch consists of -
next_fileandnext_position: point to the position and file of the next epoch after this one -
orig_server_id: updated when the MySQL server variablendb-log-origis set to 1 (defaults to 0). In this case, it is set to the originating server id of this epoch andorig_epochcontains the epoch number in the originating cluster.
When circular replication is used, each epoch will generate as many
entries in this table as there are clusters in the circle. Assume we
have cluster A with MySQL server with server_id=1 and cluster B with
MySQL server with server_id=2. Further, assume that epoch 13 is
originated in cluster A and is now applied to cluster B in epoch 209.
This epoch 209 will thereby generate two rows in this table:
-
(
epoch=209,orig_epoch=13,server_id=1) -
(
epoch=209,orig_epoch=209,server_id=2)
These multiple entries in the ndb_binlog_index table are used by the conflict detection code as we will later discuss.
If one generally wishes to also log epochs that did not perform any
changes, one can apply the MySQL server configuration parameter
--ndb-log-empty-update. We do not recommend using this feature
since it produces a lot of rows in this table. One should rather have a
failover solution that has a regularly updated heartbeat table (we will
discuss this in some detail in later chapters). This ensures that we
minimize the overhead of keeping the replication channel active such
that we know when to fail over to the backup replication channel.
ndb_apply_status#
The ndb_apply_status table contains rows that describe epochs that are written into the cluster by a replica applier. Updates to this table are not generated by events in the cluster - they are generated by a MySQL replication server acting as a binlog server. Thus in the primary cluster, this table will be empty. The table will be filled in the backup cluster when applying the epoch in the replica applier. This table has a primary key that is the server id, thus each epoch will overwrite the values in this table. Only the latest applied epoch is represented in this table for each server id.
Each epoch with changes contains one write into this table.
CREATE TABLE ndb_apply_status
(
server_id int unsigned NOT NULL,
epoch bigint unsigned NOT NULL,
log_name varchar(255) binary NOT NULL,
start_pos bigint unsigned NOT NULL,
end_pos bigint unsigned NOT NUL
PRIMARY KEY (server_id) USING HASH
) ENGINE=NDB DEFAULT CHARSET=latin1;
-
server_id: contains the server id from the MySQL Server generating the binlog entry for the epoch. Thus it is the server id of the MySQL replication server in the primary cluster. -
epoch: the epoch number in the primary cluster -
log_name: the file name of the start position of the epoch -
start_pos,end_pos: the start and end position in the binlog of the epoch.
Given that transactions are applied atomically and this write is part of the epoch transaction, it is possible to deduce if an epoch has been applied in the backup cluster by looking at this table.
Normally the writes to this table are not replicated from the backup
cluster. But for globally distributed database implementations using
multi-primary it is necessary to also replicate these changes towards
the next cluster to ensure that conflict detection can work correctly.
This is controlled by the ndb-log-apply-status parameter. If the
server id is the same as written it will be ignored to avoid replication
loops.
ndb_schema#
Schema changes (CREATE TABLE, RENAME TABLE, DROP TABLE,
ALTER TABLE, etc.) are replicated as well. They are replicated through
the aid of the ndb_schema table. When a schema change is executed, a
row is inserted into the ndb_schema table. This table is never
replicated to the replicas.
Each MySQL Server listens to events on this table. Thus each MySQL Server will hear about any schema modifications as part of the schema change process. In addition, each MySQL Server listens to events that provide detailed information about the resulting table(s) from the event.
The schema change is not necessarily executed in the same MySQL Server as where the binlog is written. By writing a row in the ndb_schema table we transport information to the MySQL replication server(s) about the schema change. We also ensure that the schema change is executed in a specific epoch.
CREATE TABLE ndb_schema (
db varbinary(63) NOT NULL,
name varbinary(63) NOT NULL,
slock binary(32) NOT NULL,
query blob NOT NULL,
node_id int unsigned NOT NULL,
epoch bigint unsigned NOT NULL,
id int unsigned NOT NULL,
version int unsigned NOT NULL,
type int unsigned NOT NULL,
PRIMARY KEY USING HASH (db,name)
) ENGINE=NDB DEFAULT CHARSET=latin1;
-
db: the database name -
name: the table name -
slock: a bitmap that is updated by each MySQL Server when they hear about the schema change. Thus through this table, we ensure that all MySQL servers are informed of all metadata changes. If a MySQL Server is down when the schema modifications occur, it can find about this schema change in the recovery phase by looking into this table. -
query: the executed query. This might be a bit rewritten for multi-table schema changes since ndb_schema will only contain single-table schema changes. -
node_id: contains the node id of the MySQL Server that executed the schema change -
id: the table id -
version: the table version -
type: the table type -
epoch: the epoch number of the schema change
ndb_replication#
The ndb_replication table has two major use cases. The first is that it can be used in normal replication setups to control which tables and what data should be replicated. The table doesn’t exist by default, thus the user must create the table and fill it with data for it to be used. If the table doesn’t exist the MySQL server settings through the options control what to replicate and by default, no conflict detection is used.
The table should be placed in the mysql database and below is the
CREATE TABLE command used to create it:
CREATE TABLE ndb_replication (
db varbinary(63),
table_name varbinary(63),
server_id int unsigned,
binlog_type int unsigned,
conflict_fn varbinary(128),
PRIMARY KEY USING HASH (db, table_name, server_id)
) ENGINE=NDB PARTITION BY KEY(db,table_name);
-
db: the database name which can contain%and?such that the database name becomes a regular expression. In this case, the columns will apply to all tables that have a database that matches the regular expression. -
table_name: the table name, which can also contain regular expressions -
server_id: if this is set to 0 it applies to all MySQL replication servers in the cluster. If set to a non-zero value it only applies to the server id listed in the table. -
binlog_type: how we binlog the specified table(s). The values used here are defined in sql/ndb_share.h. The default settings for all tables are specified using the MySQL configuration parametersndb-log-update-as-write,ndb-log-updated-only, andndb-log-update-as-minimal.ndb-log-update-as-minimal=OFFfor all options except 8 and 9. The 8 and 9 settings can however only be used in conjunction with the conflict detection functionsNDB$EPOCH2andNDB$EPOCH2_TRANS. -
conflict_fn: the conflict function, which is covered in the chapter on the globally distributed database
The following describes the different values for binlog_type in more
detail:
-
0 (
NBT_DEFAULT): server defaults rules. This is the default if no row for a table exists or if the entire ndb_replication table is missing. -
1 (
NBT_NO_LOGGING): the table or set of tables will not be logged in the binary log. -
2 (
NBT_UPDATED_ONLY): the same thing as whenndb-log-updated-onlyandndb-log-update-as-writeare set. Thus only changed values are sent in events to MySQL replication servers and thus only changed columns are written into binlog. This is the recommended value for tables that are replicated using RonDB without conflict detection. Using the default settings of the configuration options will use this binlog type. -
3 (
NBT_FULL): leads to the full row being sent in an event from the data node and written into binlog. We will still only write the after image. Same behavior as whenndb-log-updated-only=OFFand no other changes to default settings. -
4 or 6 (
NBT_USE_UPDATEorNBT_UPDATED_ONLY_USE_UPDATE): leads to that updates are logged as updates and inserts as writes. This is the setting one gets by settingndb-log-update-as-write=OFFandndb-log-updated-only=ON. These settings are the ones to use for replication to another storage engine. -
7 (
NBT_FULL_USE_UPDATE): leads to the same as setting 6 but withndb-log-updated-only=OFF. This is the setting when using conflict detection with either of the functionsNDB$OLD(column_name)andNDB$MAX_DELETE_WIN(column_name). -
8 (
NBT_UPDATED_ONLY_MINIMAL): used for replication with conflict detection using either of the conflict detection functionsndb$EPOCH2orNDB$EPOCH2_TRANS. It writes updates as updates and writes only the changed columns in the after image and only the primary key columns of the before image. -
9 (
NBT_UPDATED_FULL_MINIMAL): the same as 8 except that all non-primary key columns are written in the after image. This can be used to replicate to older versions of RonDB.
Epochs#
RonDB uses a concept called epochs to replicate transactions. An epoch is a group of transactions that are serialized to execute before the next epoch and after the previous epoch as described in earlier chapters.
We achieve these transaction groups by blocking transactions from starting to commit. When we receive a prepare message from the source node, after it has received a response from all nodes, it will send a message that transactions are allowed to start committing again.
Transactions can be in three states. They can be running operations such as read, insert, update and delete, but haven’t yet reached the commit point. The second state is when they have reached the commit point and the third state is when they are executing the commit. Transactions can continue committing if they have passed the commit point and they can continue executing in the prepare phases. The performance isn’t affected a lot by creating these transaction groups that are the epochs used for replicating to a backup cluster.
Epochs are created at a configurable interval. By default, this
interval is 100 milliseconds. By setting the cluster configuration
parameter TimeBetweenEpochs we can decrease or increase the interval
for the creation of epochs.
Some of the epochs are also used to create a global checkpoint that
the cluster can restore from in the case of a complete cluster crash.
This is configurable by the cluster configuration parameter
TimeBetweenGlobalCheckpoints. This is set to 2000 milliseconds by
default.
As mentioned before the epoch is executed as one transaction in the backup cluster.
Setting up a replication channel between two clusters#
To handle the more complex replication scenarios we will first show the basic building block of setting up a single replication channel. To make it even easier this channel is brought up before starting any operations on the primary cluster.
At first, it is highly recommended to set the MySQL server parameter
replica-allow-batching=1 in the MySQL Server in the backup cluster
where the binlog is applied. This allows the replica thread to execute
many operations in parallel and is very important to keep up with the
update rates in the primary cluster.
Starting up the MySQL replication servers#
The source MySQL replication server must activate the binlog by setting
the log-bin option to the base filename of the binlog files.
The NDB storage engine must also be activated by setting the option
ndbcluster. Since RonDB only supports row-based replication, it is
necessary to set the option binlog-format to ROW. This will
automatically use row-based replication for normal operations.
To activate replication from the NDB storage engine it is also necessary
to set the configuration parameter ndb-log-bin to 1. This is by
default set to 0 and log-bin is set by default. Thus to not enable
binlog in a MySQL Server it is necessary to set disable-log-bin.
Without the ndb-log-bin set to 1, the only actions that will be in the
binlog are the metadata statements.
The ndb-log-updated-only option is important to have ON (which it is
by default), this will ensure that the RonDB data nodes will only send
changed columns to the MySQL replication servers after a write
transaction is completed.
ndb-log-update-as-write converts updates to writes to ensure that
execution of the binlog is idempotent. This is on by default and should
be kept on.
So the default behavior is to record all updates as writes with only the
changed columns recorded. This setting is good unless you are using any
of the conflict detection setups, this will be covered in a later
chapter. If you replicate to another storage engine it is important to
set ndb-log-update-as-write to 0.
Setting ndb-extra-logging to 99 might be useful if you want more
understanding of what goes on in the MySQL replication server.
In the source MySQL server we should ensure that file writes are
synchronized to disk to ensure that the epochs are written to disk as
soon as they are completed. This means we need to set sync-binlog to
1.
Thus starting up the MySQL replication server in the primary cluster should at least contain the following options.
mysqld --server-id=$id \
--log-bin=mysql-bin \
--ndb-log-bin=1 \
--sync-binlog=1 \
--ndbcluster \
--binlog-format=ROW \
--binlog-cache-size=1M
The MySQL replication server in the backup cluster must also set a
unique server-id, it must set the ndbcluster option. If it only
operates as a replica it doesn’t need to configure the binlog. To avoid
that the replica replication starts before we are ready it is important
to add the option skip-replica-start. The replica applier should use
batching to increase speed of the applier, setting the
replica-allow-batching to 1 means that we can use batching of
operations at the replica.
In RonDB 21.04 one still have to use --skip-slave-start since RonDB
21.04 is based on MySQL Cluster 8.0.24. RonDB 22.10 is based on MySQL
Cluster 8.0.34 and thus will accept --skip-replica-start. Similarly,
RonDB 21.04 requires the use of --slave-allow-batching.
Thus starting up the MySQL replication server in the backup cluster should at least contain the following options.
Creating a user on the source MySQL Server#
Given that the replica server needs to connect to the source MySQL server, it is necessary to set a special replication user on the source MySQL Server. This is recommended for security reasons.
Set the replication channel starting point on the replica side#
Before the replica applier can start it needs to know the following things:
-
Hostname of source MySQL Server
-
Port number of the source MySQL Server
-
Username that the replica will use on the source MySQL Server
-
Password of this user on the source MySQL Server
-
The starting binlog file on the source MySQL Server
-
The starting position on the source MySQL Server.
When starting replication from a new cluster an empty file name means the starting binlog file and this file starts at position 4. The command executed in the replica MySQL Server now is the following.
CHANGE REPLICATION SOURCE TO
SOURCE_HOST='source_host',
SOURCE_PORT=source_port,
SOURCE_USER='replica_user',
SOURCE_PASSWORD='replica_password',
SOURCE_LOG_FILE='mysql-bin.000001',
SOURCE_LOG_POS=4;
There is also a set of options in the CHANGE REPLICATION SOURCE TO
command to set up a secure communication between the replica and the
source using SSL options.
Start replica applier#
Now we are prepared to start our replication channel. We execute the command
in the replica MySQL Server. Now the replication channel has started and any transactions executed in the primary cluster will be applied in the backup cluster through the replica MySQL Server.
Importing a backup from the primary cluster#
Bringing up a replication channel in a live cluster is not that much more complex. All the preparations are identical the same except for one thing. We must first import the entire data set from the primary cluster followed by catching up with the binlog in the primary cluster.
Eight steps are required here:
-
Ensure that the binlog has been started on the source MySQL Server
-
Execute a backup in the source cluster
-
Create any databases needed in the replica cluster not yet present there
-
Reset the replica in the replica MySQL Server
-
Restore the backup in the replica cluster
-
Discover the last epoch that was in the backup
-
Discover the start position in the binlog for the first epoch not in backup
-
Set this position in the
CHANGE REPLICATION SOURCE TO command -
Start the replica applier
The binlog is started immediately when the MySQL Server is started with log-bin set.
To execute a backup in RonDB is very simple, we provide more details on
this in the chapter on backups in RonDB. It is enough to connect to the
RonDB management server using a management client and issue the command
START BACKUP. After some time the command is completed.
Now before restoring the backup ensure that any CREATE DATABASE
commands are issued on a MySQL Server connected to the backup cluster.
Databases are not stored in RonDB backups. If metadata was restored
using data from mysqldump that also restored databases this is not
necessary.
To restore the backup in the backup cluster is covered in detail in the chapter on Restore in RonDB. Essentially we install a backup from the primary cluster, we ensure that the ndb_apply_status table is up to date and we ensure that the restore is not logged to any binlogs.
Now ensure that the replica is reset before we set up the replication channel to ensure that the old replica settings aren’t interfering. This is performed through the following command in the replica MySQL Server.
Now to discover the last epoch in the backup we use the command in replica MySQL Server (or any other MySQL Server connected to the replica cluster).
We have now read the last epoch number that have been restored in the replica cluster.
Equipped with this information we can now use the ndb_binlog_index table in the source MySQL Server to discover the binlog position where to start the replica applier.
We execute the following query in the source MySQL Server where
@latest comes from the previous command and @file and @pos is what
we are looking for.
The epoch number written into the backup isn’t necessarily a real epoch number, this means that we need to start the replication from the position of the next binlog entry after the epoch which is the highest epoch which is equal to the epoch in the ndb_apply_status table or smaller than that.
SELECT @file:=SUBSTRING_INDEX(next_file, '/', -1),
@pos:=next_position
FROM mysql.ndb_binlog_index
WHERE epoch <= @latest
ORDER BY epoch DESC LIMIT 1;
Now we take those two parameters back to the replica MySQL Server and use those to set the binlog file and binlog position from where the replica MySQL Server should start applying the binlog.
CHANGE REPLICATION SOURCE TO
SOURCE_HOST='source_host',
SOURCE_PORT=source_port,
SOURCE_USER='replica_user',
SOURCE_PASSWORD='replica_password',
SOURCE_LOG_FILE='@file',
SOURCE_LOG_POS=@pos;
Note that the above is pseudo-code for how to set up the replication channel. In reality, these commands are executed on different MySQL Servers and thus one needs to use shell script, Python, Perl or some other manner of executing those commands.
Now we are now ready to start the replica applier.
After starting the replica applier it will take some time before the backup cluster has caught up with the primary cluster. The backup cluster will never entirely catch up since replication is asynchronous. But the replication lag will start with as long time as it takes to restore the backup and this could potentially take a fairly long time, definitely minutes and potentially even hours in larger clusters. The replication lag should be possible to get down to seconds.
The MySQL manual contains an example script written in Perl called reset-replica.pl that automates parts of this process.
Point-in-Time backups#
Normally the second cluster is used for fail-over cases. If the primary cluster can sustain a high load and the backup cluster can only survive the update load, in this case, it could be interesting to use the backup cluster to provide a point-in-time backup solution for RonDB.
To install such a point-in-time backup at the primary cluster one starts with a backup, next one uses the replica cluster to catch up unto the point in time that should be restored.
The MySQL manual has a detailed description of how to handle this.
Read Replica Clusters#
The above setup could be directly used for Read Replica Cluster setups. In this case, it might even be ok to avoid a fail-over replication channel between the primary cluster and the backup cluster. Loss of the replication channel means that the backup cluster cannot be used until it has been restarted and come back again.
For a backup cluster used only for extra read capacity, this can be agreeable. The primary cluster can thus sustain more clusters instead of sustaining fail-over replication channels.
Characteristics of replica applier for RonDB#
The replica applier is the replica applier used by MySQL Replication. This applier is single-threaded. At the same time, this single thread works on very large batches where transactions spanning the last 100 milliseconds are applied in one large transaction.
Given that the NDB API can sustain very high levels of batching, the performance of this single thread is extremely good. More than a hundred thousand operations per second can be handled through this single thread.
Global Replication can be used for most applications using RonDB. The exception is applications requiring many hundreds of thousands of write operations per second or even going into millions of write operations per second. Those cases are still possible to handle but will require setting up parallel replication channels for each database as described in later chapters.
Purging MySQL Replication files#
MySQL Replication uses binlog files that have a specific size, after completing the write of one binlog file, the file is closed and a new one is written to instead. It goes on like this as long as the replication continues. A binlog file can also be closed and a new one created by restarting the MySQL Server.
MySQL will never delete any binlog files automatically, it can delete them on command, but the command must be executed by the DBA. Thus the DBA must always have a strategy for how to delete the binlog files.
In case the backup clusters are not used for fail-over scenarios it would be sufficient to keep the binlog files until all backup clusters have applied the binlog file.
Thus to calculate which files to delete at any point in time one would issue the following query towards the ndb_apply_status table in each backup cluster to deduce what epoch have been applied in the backup cluster.
Now take the minimum of all the latest from all backup clusters. Next, use the following query on the ndb_binlog_index table in the primary cluster.
SELECT @file:=SUBSTRING_INDEX(next_file, '/', -1),
@pos:=next_position
FROM mysql.ndb_binlog_index
WHERE epoch <= @minimum_latest
ORDER BY epoch DESC LIMIT 1;
Now the file variable contains the last file that needs to be
retained. All files before this one can be deleted.
Now if we have a fail-over scenario it is essential to be able to fail-over after a complete crash of the primary cluster. It is important to be able to handle simultaneous crash of the primary cluster and the backup cluster used for fail-over. In this case, we can restart one of the clusters using a backup from the primary cluster followed by applying the binlog up to the end of the binlog.
To ensure that the binlog can be used together with a backup one checks
the StopGCP number output from the backup at completion. In the
example below the StopGCP is 3845.
ndb_mgm> START BACKUP
Waiting for completed, this may take several minutes
Node 2: Backup 1 started from node 1
Node 2: Backup 1 started from node 1 completed
StartGCP: 3839 StopGCP: 3845
#Records: 193234 #LogRecords: 12349
Data: 20519789 bytes Log: 1334560 bytes
An epoch number is formed by using the StopGCP as the 32 most
significant bits of a 64-bit number and 0 as the 32 least significant
numbers. Use this epoch number in the same manner as above to
calculate the binlog file that can be deleted using the above query on
the ndb_binlog_index table.
In the fail-over case, we have to ensure that all backup clusters can survive a primary cluster failure and we need to be able to handle a restore from backup, thus we need to retain the files needed for both of the above cases.
When we are deleting a binlog file it is important to also delete all
entries in the ndb_binlog_index table for this file as well. Running
the PURGE BINARY LOGS will ensure that this is done correctly.
Thus an important script in the DBA toolbox for Global Replication is a script that automates the above to ensure that we purge binlog files in the MySQL replication servers in the primary cluster.