Concurrency Control#

Concurrency control is vital in DBMSs to allow for multiple transactions to operate on data at the same time. This chapter will describe RonDB’s approach moving from requirements to implementation details.
TLDR; RonDB Specs#
Architecture:
-
Strict two-phase row locking (pessimistic approach)
-
Time-out-based deadlock detection
-
No range locks supported
Properties:
-
Default isolation level is read committed
-
Repeatable reads are supported application-level
Isolation Levels#
DBMSs are used for querying, analyzing and many other things. Since queries in particular can easily run for seconds, minutes or even hours, it can make sense to loosen the level of isolation for reads to allow more concurrency. From the point of view of the client, a loosened isolation level can however affect its perception of consistency.
The following is a simplified list of various isolation levels applicable in a DBMS:
-
Read Uncommitted: This is the lowest isolation level, where transactions can read uncommitted data from other transactions. This allows dirty reads. RonDB does not support this.
-
Read Committed: This level prevents dirty reads, but not non-repeatable reads or phantom reads. Non-repeatable reads happen when a transaction repeats a read, but the data has been updated or deleted in between. Phantom reads happen when a transaction repeats a read, but new rows have been inserted in-between.
When scanning data you see the latest committed data. However, the data isn’t locked, so it might be concurrently updated. This model will always provide you with the most up-to-date version of the data. The returned data is however not necessarily consistent with what the database contained at any specific point in time.
This is the model used in RonDB, DB2 and normally in Microsoft SQL Server.
-
Repeatable Read: This level disallows dirty reads and non-repeatable reads, but not phantom reads. Once a transaction reads data, other transactions cannot modify that data until the first transaction completes. Here, transactions are protected from updates made by other transactions, but not from insertions or deletions.
Implementation options:
1. Holding read locks
**Advantage**: Lower memory overhead2. Snapshot read: Creating a copy of each queried row during the transaction
**Advantage**: Higher read/write concurrencyIn both cases, either the lock or the copy is run on the row level. Since phantom rows did not exist at the time of reading, they cannot be locked or copied. This can cause phantom reads.
This mode is used in MySQL InnoDB and is used by the Oracle DBMS. It can be applied on an application level in RonDB using locks.
-
Serializable: This is the highest standard isolation level and prevents dirty reads, non-repeatable reads, and phantom reads.
Phantom reads are prevented by holding a broader table or range-based locks, depending on the database’s locking mechanism. Transactions can thereby not insert new rows that would match the queries of another transaction until it is complete.
If any two transactions operate on the same data, they will be executed serially in some order, not concurrently.
Serializability is not the same as serial execution, which is not supported by DBMSs. A serializable transaction can also see commits from transactions that started after it. Any transaction that committed before is viewed as it happened before it, even if it started afterward.
This isolation level is not supported by RonDB, unless one uses row locks as representative range locks.
Most relational databases implement at least a subset of the requirements of serializable transactions. The following lists the pros and cons of implementing high isolation levels.
Pros:
-
Higher read consistency; easier to reason about the correctness of changes & data
-
Easier to develop applications
Cons:
-
Less concurrency; easily a performance bottleneck
-
More expensive to implement
-
Less suitable for analyzing data in real-time
RonDB’s Choice#
RonDB uses the isolation level read committed. This means that long-running queries may not return consistent data, but the latest proportion of it will be up-to-date.
The implementation options for repeatable reads caused it to be a less attractive default mode. Being primarily an in-memory database, the memory overhead for snapshot reads is a concern. Using read locks on the other hand could cause spiking latencies in writes. To support read consistency for long-running queries is not a priority in RonDB. However, the NDB API allows for the use of repeatable reads using locks if needed, as described further below.
Optimistic vs. Pessimistic#
Broadly, there are two approaches to concurrency control: optimistic and pessimistic. Each approach has a plethora of variations, primarily based on locking mechanisms or timestamp methods, making this one of the most thoroughly explored areas in DBMS research.
The optimistic approach proceeds with updates without immediate conflict checks. Conflicts are only assessed at commit time, necessitating the abortion of one of the conflicting transactions if they occur. This approach often uses timestamps.
Conversely, the pessimistic approach proactively avoids conflicts before committing. This is often achieved through two-phase locking (2PL). In the first "growing" phase, the necessary locks are acquired. In the second "shrinking" phase, they are released. After a lock is released, no further locks can be acquired in that transaction. Different strictness levels of the 2PL define how gradual the two phases can be.
The following lists the pros and cons of the pessimistic approach. It assumes that it uses locks over timestamps, even though one can also use a combination of both.
Pros:
-
Fewer transaction aborts
-
Easier application development (due to less aborts)
-
Consistent performance during conflicts; no wasted CPU costs due to aborts
-
Suitable for long transactions
-
Less memory overhead avoiding timestamps
-
Recovery algorithms become more straightforward with locking mechanisms
Cons:
-
Higher latency due to waiting for locks
-
Performance overhead to acquire/release locks, especially in distributed systems
-
Locks can create deadlocks (can also increase latency)
Examining the main use case for the database is therefore key. The optimistic approach is typically used in systems where conflicts are rare.
RonDB’s Choice#
RonDB uses the pessimistic approach. The prime reasons for this are to support predictable latency in the face of conflicts, reduce memory overhead and simplify recovery algorithms.
Since RonDB is primarily an in-memory database, memory overhead is generally a concern. Simple and speedy recovery algorithms are on the other hand key to ensure high availability. For instance, the ability to briefly lock a row is instrumental in our Copy Fragment Protocol for node restart, simplifying the synchronization process between live and starting nodes.
RonDB however has a manifold of other protocols that use locking. These are in particular online algorithms that change metadata. This includes the mechanisms to reorganize partitions and to create ordered and unique indexes.
RonDB’s Row Locking#
The approach in RonDB is to use row locking. We access records using a hash index when any type of lock is needed. Scanning is done in range index order per partition or row order (not in hash index order). The latter case means we have to ask the hash index for a lock on the row for each row we scan when a lock is needed.
In the hash index, we implemented our row locks. If a scan comes from an ordered index and needs to lock the row it will use the hash index to get the lock. Most DBMS use a hash index to implement the lock data structure. In our case, this hash index is also used as an access data structure, not just to handle locks.
Supporting Read Committed#
For read committed reads, committed rows in DataMemory are scanned without taking a lock. Running writes concurrently is possible since they are stored in TransactionMemory. In the Two-Phase Commit Protocol, the updated data is moved to the DataMemory simultaneously with the locks being removed. For the primary replica, this is during the commit phase and for backup replicas during the complete phase.
The TransactionMemory may contain multiple versions of the same row - one for each update during the transaction. Here, the row is locked, which means that we are exercising WORM locking (Write Once Read Many).
Application-Level Locking#
RonDB supports the following locking modes, which can also be used via the NDB API directly:
| SQL Statement | Isolation Level | Lock Type | Behaviour | Implementation | |
|---|---|---|---|---|---|
SELECT ... (default) |
Read committed | Write-Once Read-Many Lock (WORM) | Multiple reads AND one write | No locks on reads; multi-version rows during updates | |
SELECT ... LOCK IN SHARED MODE |
Repeatable read | Read-Write Lock | Multiple reads OR one write | Upgradeable read-lock | |
SELECT ... LOCK IN EXCLUSIVE MODE |
Repeatable read | Write Lock | One read OR one write | Same lock for both reads & writes |
Use-case Exclusive Locks#
Using locks in EXCLUSIVE MODE hurts read performance, but avoids
deadlocks caused by lock upgrades using the SHARED MODE lock.
A transaction may run reads and writes in sequence. When using a
SHARED MODE lock, this may also mean that it will first acquire a read
lock of a row and then later upgrade it to a write lock.
The issue is that another transaction may also want to upgrade its
SHARED MODE lock of the same row at the same time. Both transactions
will however not give up their read lock until it can be replaced by a
write lock. This means that both transactions will wait for each other,
causing a deadlock.
Range Locks#
RonDB has no support for range locks. Range locks are required to fully support serializability. Thus we support serializability on everything except range queries. Our analysis of RonDB’s main use cases suggests that a serializable mode for range queries is of limited use.
RonDB uses hash partitioning to distribute data. Therefore, if we want to lock a range, we may have to place a lock on all nodes in the cluster. Since RonDB supports up to 72 node groups using 2 replicas (i.e. 144 data nodes), this would impose a serious scalability issue. This issue is why most classic SQL DBMSs use a shared-disk implementation. RonDB implements a shared-nothing architecture to ensure high availability.
The alternative to hash partitioning is to use range partitioning. The benefit would be that one would only have to lock the range in one node group. However, this would only apply if the range was taken on the columns in the partition key. A further downside of range partitioning is that it inhibits even distribution of data.
The easiest implementation for RonDB to apply range locks would be to use a table lock. This would however be highly inefficient and drastically reduce concurrency. Table locks are not implemented in RonDB.
Range Lock Workarounds#
It is possible to implement range locks application-side. One can create a row that symbolically represents the range and always place a shared lock on it before reading a range.
An example of a RonDB application using application-side range locks is HopsFS. When creating a directory, it will also lock the parent directory. This will then prevent phantom reads.
Locking Unique Indexes#
Unique indexes are table constraints that are created using the UNIQUE
keyword:
CREATE TABLE employees (
employee_id INT,
username VARCHAR(20) UNIQUE,
address VARCHAR(30),
PRIMARY KEY (employee_id)
);
In RonDB’s "backend", unique indexes are special tables. Their primary key consists of the unique key columns and the remaining columns are the primary key of the main table. Thus one can translate the unique key to the primary key with one key lookup. This essentially enables quick row lookups on the main table using the unique key.
When writing to the main table, a synchronous trigger is run to update the unique index table if necessary. This is the case for inserting and deleting rows and updating a row’s unique key column(s). An insert will cause an insert in the unique index table, a delete will cause a delete and an update will cause both.
A tricky situation is when there are two consecutive operations on the main table: first deleting a row and then inserting one with the same primary key. Another transaction may have started a row lookup using the unique key shortly before the delete operation. It will find the primary key of the main table in the unique index table and then proceed to read the main table. Now, there is a risk that it will read the new row that was inserted by the other transaction. This is shown in the following figure.
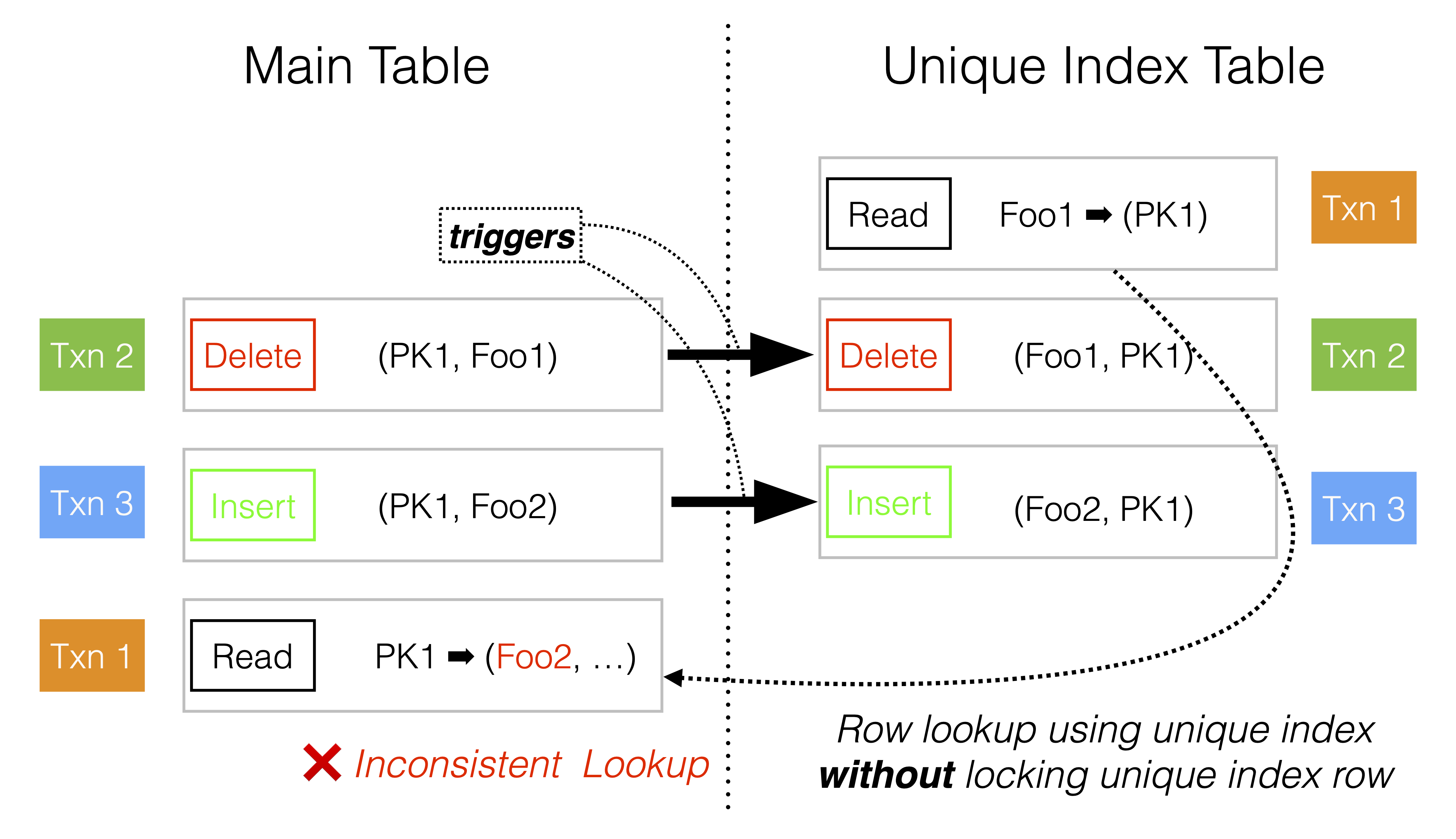
To mitigate this, row lookups using the unique index will place a shared lock on the unique index row until the main table row has been read. In the case of the default read committed, there will not be any lock placed on the main table row. Furthermore, as soon as the main table row has been read, the lock on the unique index row can be released. This reproduces the behavior of read committed as best as possible.
An issue with this approach is that it can cause deadlocks. This is when the lookup using the unique index uses a shared/exclusive lock for the transaction or also performs a write on the row. In this case, the main row will also be locked. This is an issue if there is another transaction writing to the row using the primary key. The following shows two transactions that could cause a deadlock.
-- transaction 0
INSERT employees (employee_id, username, address) VALUES (1, 'kernelmaker', 'Stockholm');
-- transaction 1
UPDATE employees SET username = 'coffeemaker' WHERE employee_id = 1;
-- transaction 2
UPDATE employees SET address = 'New York' WHERE username = 'kernelmaker';
Whilst transaction 1 will first lock the main table row and then the
unique index row, transaction 2 will lock in the opposite order. They
may therefore wait for one another, causing a deadlock.
The best use of unique keys is to primarily use them for constraint checks during inserts and updates. This ensures that only rows with a given unique key exist. This also means that we avoid using them as filters for lookups. One thereby escapes the deadlock scenario just described.
Locking BLOBs#
In RonDB, each BLOB column in a table will create a separate BLOB table. Here, each BLOB will be stored in multiple rows of 2 KiB. Only the first 256 bytes of the BLOB are stored in the row of the original table. A simple row lookup with a BLOB column must therefore potentially access multiple rows in the BLOB table. The BLOB tables themselves are not accessible to users.
Read Committed#
Usually, reads using the read committed mode will not take any locks and thereby also be oblivious to other locks. Since a BLOB consists of multiple rows, this does not work. If there is a write (using an exclusive lock) during our lockless read, we have a race condition, since each operation will read/write one BLOB row at a time. We would risk reading an inconsistent BLOB.
To avoid inconsistent reads, we take a shared lock on the row in the original table. This disallows any updates to the BLOB parts while we are reading them. To nonetheless adhere to the read committed behavior, the lock is released immediately after all BLOB parts have been read. Since these locks are very short-lived, there should be little contention on concurrent reads.
However, this architecture also means that reads will wait for updates. The default WORM (Write Once Read Many) locking behavior of read committed does not hold. A read’s shared lock can only be taken once the write’s exclusive lock has been released. On the plus side, this means that reading a row with BLOB columns will always have read-after-write consistency, regardless of which replica is read. Disabling the Read Backup table option does not affect this.
Enabling the Read Backup table option means sending a transaction acknowledgment to the application after the complete phase and allowing reads on all replicas. Disabling it means already sending the acknowledgment after the commit phase, but only allowing reads on the primary replica. The latter is a measure to uphold read-after-write consistency.
After the commit phase, only the primary replica has both committed and released its locks. The backup replicas will only have committed. Updated data is only moved from TransactionMemory to DataMemory when releasing the locks. In DataMemory, it is available to read for other transactions.
The transaction phases are explained in detail in the Two-Phase Commit Protocol.
Writes & Application-Level Locks#
Any changes to a BLOB require holding an exclusive lock on both the row in the original table and all related rows in the BLOB table. The reason why all BLOB part rows need to be locked is due to interaction with other RonDB-native operations like the Copy Fragment Process. These may not have any notion of BLOB tables and will therefore expect any presently updating BLOB row to be locked.
If a transaction updates a BLOB or uses an application-side shared/exclusive lock, the lock will be kept until the end of the transaction. This is also consistent with the behavior for normal rows.
Strict Two-phase Locking (S2PL)#
RonDB employs the strict two-phase locking method. Strict means that all write locks are held until the transaction ends. Read locks can however be released gradually. In contrast to the conservative 2PL, the locks do not have to be taken all at once, but also gradually.
Given the following simplified transaction:
START TRANSACTION;
SELECT A LOCK IN SHARED MODE;
UPDATE B;
SELECT C LOCK IN SHARED MODE;
UPDATE D;
COMMIT;
The MySQL server will send one operation at a time to the NDB API. Each operation will take the lock that it needs. The following figure shows how this works with RonDB’s Two-Phase Commit Protocol which contains a prepare phase, a commit phase and a complete phase.
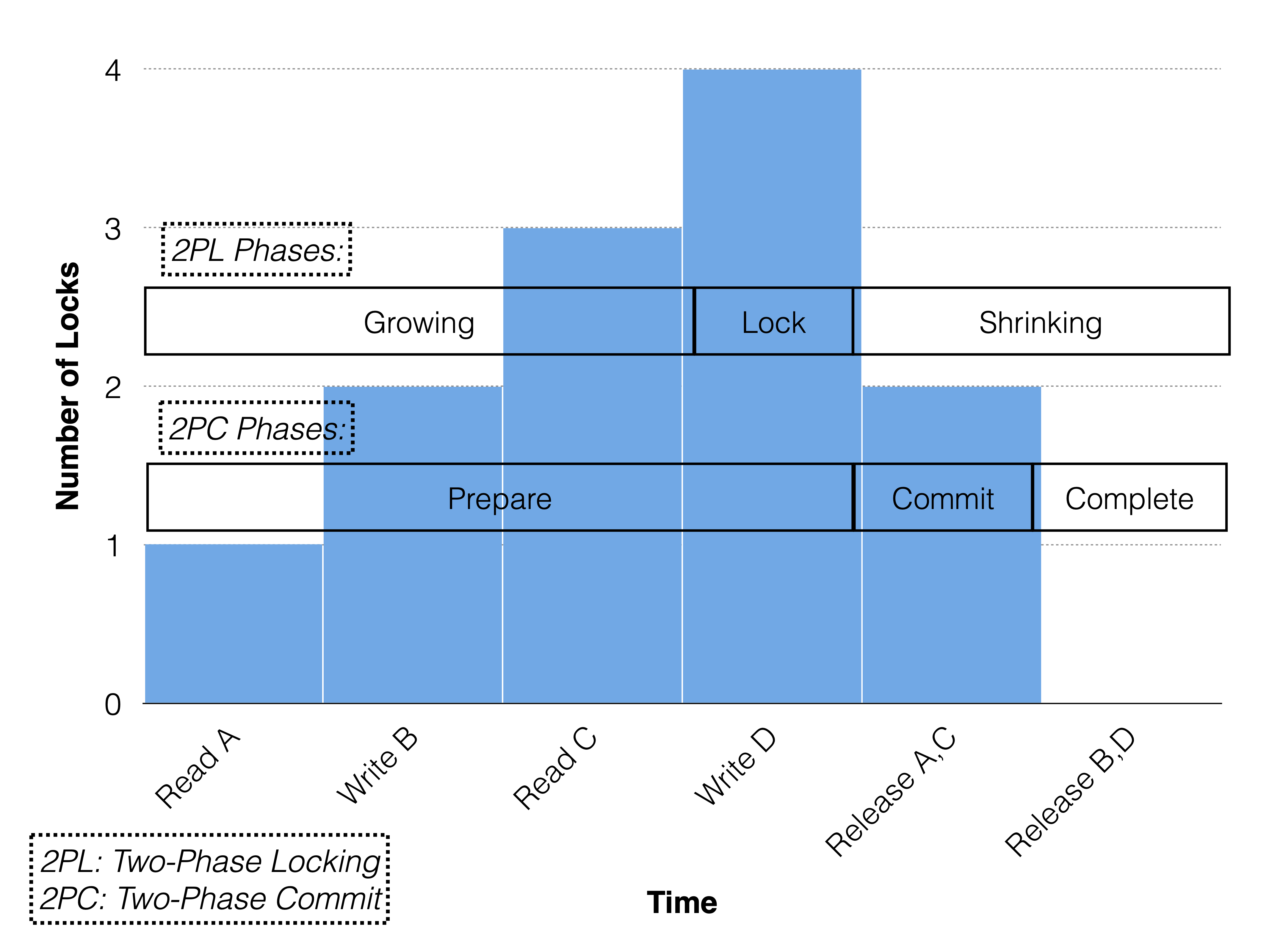
Note that all reads and writes are performed in the prepare phase and that the number of locks gradually increases. Read locks are already released in the commit phase and write locks are released in the complete phase. If the read locks were also released in the complete phase, the transaction would be strong strict or rigorous. If the locks were acquired all at once in the prepare phase, the transaction would be conservative.
Handling Deadlocks#
When using locks for transactions, it is possible to create deadlocks. A deadlock occurs when a set of transactions cannot proceed because there is a circular dependency of locks.
Example#
In the following, we will reason about deadlocks using a dependency graph.
The dependency graph below shows four transactions and two circular dependencies (= deadlocks). First, there is a cycle where T1 waits for T2, T2 waits for T3, T3 waits for T4 and T4 waits for T1. Additionally, we see that T1 waits for T3, creating another shorter cycle.
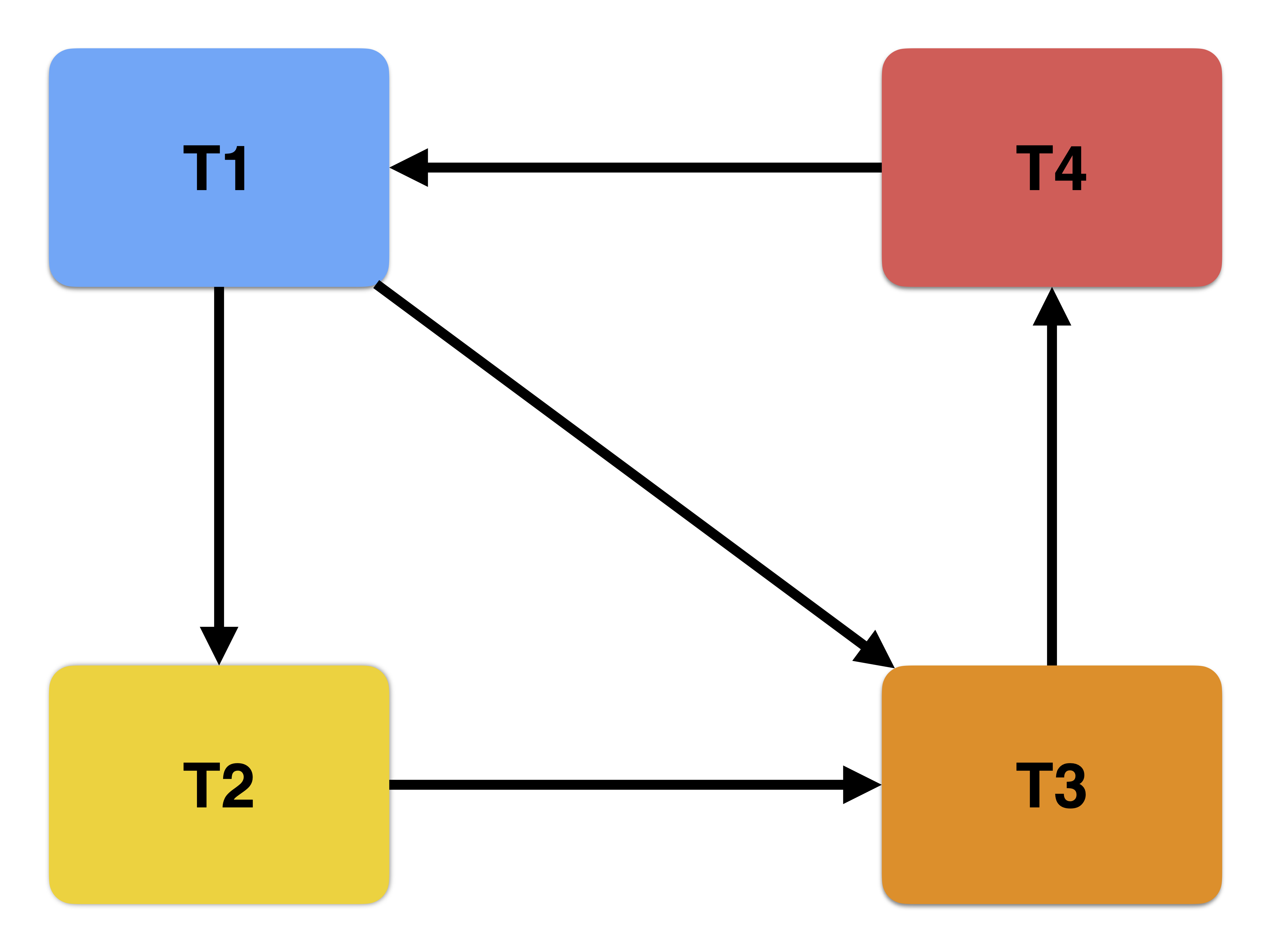
The only method to get out of a deadlock is to abort one or more transactions. In this case, we can abort T1, T3 or T4 to be able to proceed again. Aborting T2 is not sufficient since it does not break the cycle between T1, T3 and T4.
Strategies#
Handling deadlocks can either be done by avoiding (A) or detecting (D) them. The following lists a few strategies:
-
A: Locks in order
If every transaction takes all locks in the same order, no deadlocks can occur. Each level of organization that is given a total order reduces the chances of deadlocks. For example, an order can be placed on a table level, on a row level or even on a replica level in a distributed system. All levels are important.
An important "level" is however the application level. A transaction can consist of multiple sequential user-defined operations - e.g. update row A, then update row B. If the system uses non-conservative 2PL and takes locks for one operation at a time, a large responsibility is placed on the application developer. Two transactions writing to rows A and B as separate operations in opposite order can then cause a deadlock.
-
A: Pre-claiming all locks (Conservative 2PL)
This method helps if there is already an order of locks in place (see previous strategy). Claiming all operations’ locks at once will remove deadlocks induced by the order of operations within a transaction, which is defined by the application developer. However, it will also harm concurrency.
-
D: Deadlock resolution
This means creating the dependency graph and finding the cycles. The cycles can then be broken by aborting one or more transactions. Algorithms to detect deadlocks are however NP-complete. This means that the cost of detecting deadlocks increases exponentially as the number of potential deadlocks increases. It is not possible to construct an algorithm with a cost that is linear to the problem size.
In practice, it is a good idea to discover the simplest deadlocks. The most common ones only have 2 participants. Resolving these removes guesswork done by other more fallible approaches.
-
D: Timeouts
Here, deadlocks are not detected per se, but the progress stop of a transaction. This then also leads to an abort of the transaction. It is a safe and easy method of handling deadlocks. However, it means that some transactions will be aborted that were never involved in deadlocks. In a distributed database this can be used to detect transactions that have stopped progressing due to a node failure.
RonDB’s Strategy#
Generally, it can be useful to deploy a range of solutions to handle deadlocks. RonDB currently implements a time-out based deadlock detection algorithm and locks rows in replica order. The latter is called primary copy locking. RonDB also takes locks for one operation at a time according to the S2PL protocol, so there is a likelihood of application-induced deadlocks.
Distributed transactions#
Since RonDB is a distributed database any transactions must be implemented as distributed transactions. The most common method to implement distributed transactions is the two-phase commit protocol. This means that first all participants are prepared, and if all participants decide to accept the coordinator, they will decide to commit. How RonDB implements its own non-blocking two-phase commit protocol which is described here.