Communication architecture in RonDB virtual machine#
RonDB is a distributed DBMS and thus needs efficient communication between nodes. Internally RonDB implements a functionally distributed thread architecture. This means that each request will be executed using multiple threads. Thus it is vital for RonDB performance that the communication between threads is also very efficient.
In the part on Research using RonDB we show that the thread pipeline model used in RonDB is very efficient compared to executing everything in one thread. The performance improvement can be as high as 30-40%.
Communication between threads#
In the figure below we show how communication between threads in RonDB is handled.
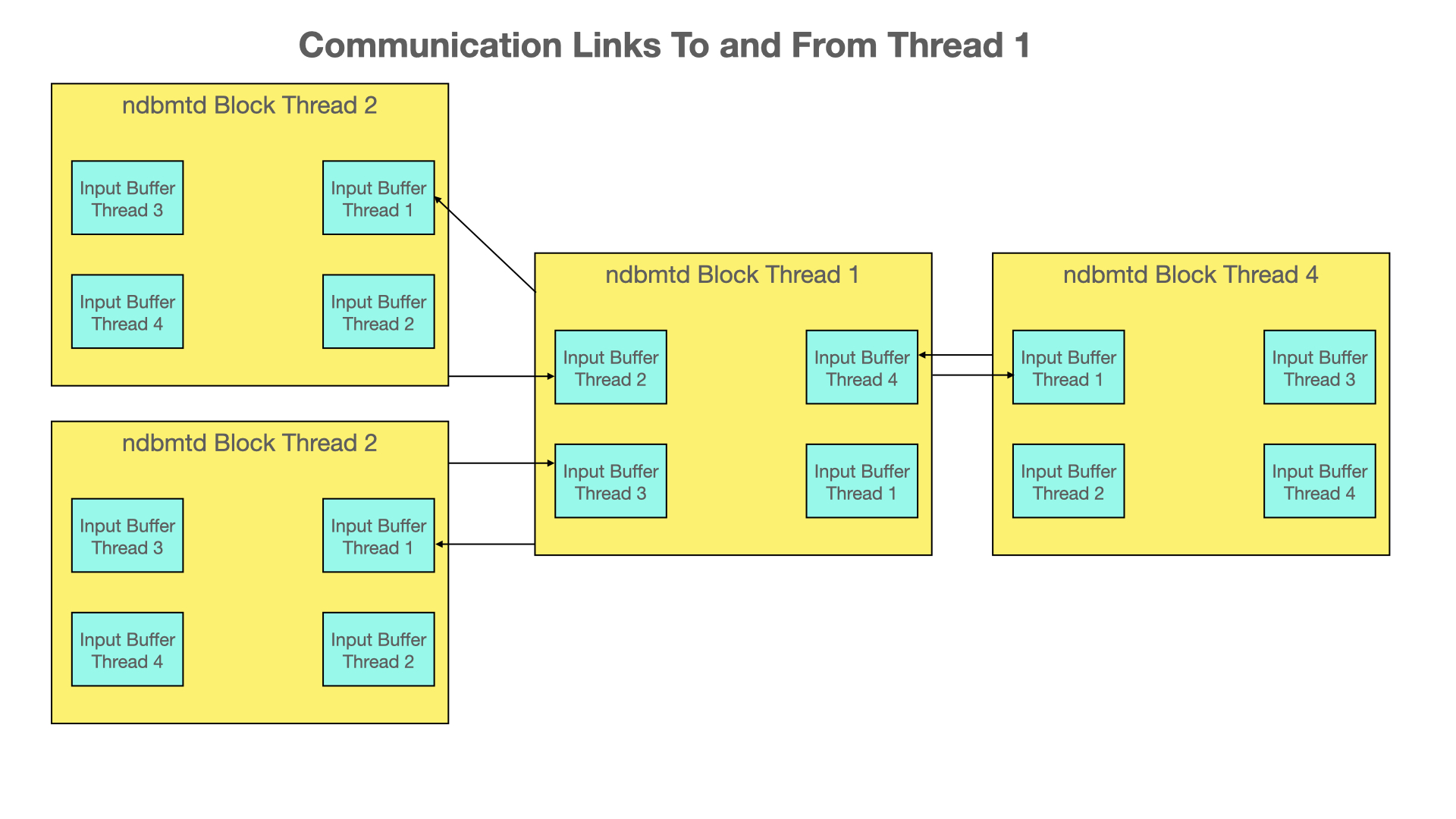
Each thread has its input buffer to each other thread. This means that each input buffer has a single reader thread and a single writer. In this model, there is no need to use mutexes to implement the communication mechanism.
It is however important to use memory barriers in the correct places. The reason for this is that one needs to communicate head and tail information separate from the actual data of the messages. This means that the writer must ensure that the reader sees all data in the message after it has seen an update of the head information.
The implementation of this means that the writer must write the data of the message first. Next, the writer must issue a write memory barrier that ensures that the writers CPU have flushed all the writes in its buffers such that the reader CPU can see those writes. After this, the writer can update the head information.
When the reader sees the head information it needs to issue a read memory barrier to ensure that it can see all the data written by the writer CPU. Thus a memory barrier must be imposed on both the writer CPU and on the reader CPU.
This model works fine in a moderate amount of threads. The problem with this model in larger nodes is that the number of input buffers grows exponentially. In addition, the reader must scan through more and more input buffers.
To avoid this exponential growth we use a limited amount of input buffers in larger nodes. This means that we have multiple writers and a single reader. This requires a mutex to protect the input buffer.
The extra overhead through mutexes is around 1.5%. Obviously in larger nodes this loss is regained by scanning fewer input buffers.
Message information in input buffers#
The input buffers are 1 MByte in size. These input buffers contain the message headers and a part of the message. The messages for database communication require key information and attribute information. This information is transferred in a separate memory part that we call long message buffer.
Design choices#
How many messages should be sent before we update the Head information. If this number is too low we will execute too many memory barriers, If it is too high the latency in sending messages to other threads will be too high.
In our case, we set this constant to 2 for communication from all threads except from receive threads. Receive threads set the constant to 20 instead. Receive is mostly about communicating with other threads and not executing so much on their own, thus it is natural that they have a higher constant.
Another very important constant is the number of messages to execute from one input buffer before moving to the next input buffer. If this is too high the delay in handling messages from other threads can be blocked by some thread that sends a lot of messages. We set this constant to 75. The input buffer rarely contains that many messages. Thus it is mainly used in extreme load situations.
The number 75 is based on that our design requirement is that one message should be executed in no more than 1-2 microseconds.
Wakeup problem#
When we send a message to another thread we need to ensure that the thread is either awake already or that we send a wakeup signal to it. We use an implementation based on futexes on Linux (integrates assembler instructions in the wakeup handling) and mutexes with condition variables on all other platforms.
Here is another constant to consider, how many signals should we send to another thread before we check whether the receiving threads are awake or not. This constant is configurable and the lower it is set, the lower the efficiency, but with a better latency.
We have the same wakeup problem when sending to another node that uses the shared memory transporter. In this case, we use mutexes that are designed for interprocess communication.
Waking up a thread can be costly, it can take up to 25 microseconds and can cost a bit of CPU usage also on the thread performing the wakeup.
With this in mind, we implemented the possibility to perform CPU spinning before we go to sleep. Previously this used a static CPU spinning where we spun independently of whether it was a good idea or not.
In RonDB we use an adaptive spinning. This means that we collect statistics on the expected wait time. With this information, we can calculate the expected cost of gaining latency. We calculate at startup the time it takes to wake up. So for example, if we discover that it takes 20 microseconds to wake up, then if the expected time to the next wakeup call is 80 microseconds, it means that for each microsecond of spinning we are expected to gain 250 nanoseconds of latency.
We can configure the adaptive CPU spinning on three levels. The lowest level is cost-based spinning. In this, we allow up to 70% of overhead for gaining latency. Thus in the case above an expected wakeup time of 20 microseconds will start spinning if the expected wait time is less than 34 microseconds.
The next level which is the latency optimized level allows for 1000% overhead to gain latency, this means in this case that we start spinning if the expected wait time to the next wakeup signal is below 220 microseconds.
The final level is the database machine level. In this case, we allow for 10000% overhead. This means more or less that if there is any chance to gain latency we will spin. There is however a limit on the spinning time, we will never spin for more than 500 microseconds.
The CPU spinning uses special CPU instructions that ensure that the CPU is not very active during the spin. In particular, it means that in hyperthreaded CPUs such as AMD Epyc and Intel Xeon, we will be able to execute more or less full speed in one of the CPU threads and be spinning in the other CPU thread. The impact of CPU spinning on the other CPU thread will be very minimal.
The CPU spinning makes top a bit less useful, but ndb_top will report
time for spinning separately from normal user time. Similarly in Grafana
graphs generated by ndbinfo tables in RonDB.
Communication between nodes#
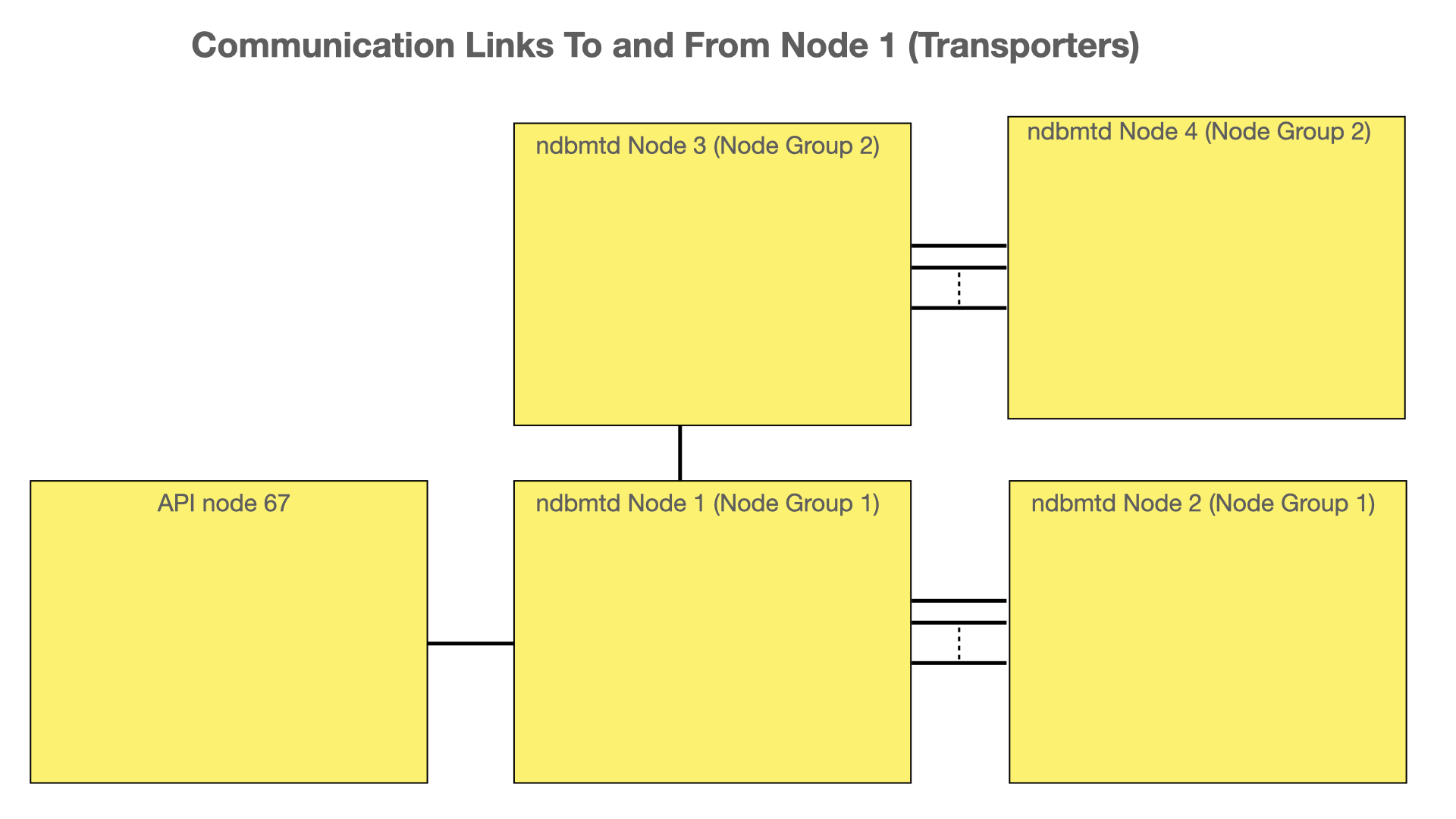
In the figure below we see the communication links used between nodes in RonDB. Each API node and MySQL Server has one transporter to every one of the data nodes. Data nodes also communicate using a transporter in the same fashion. However, communication between data nodes in the same node group is a bit special. In this case, there are multiple transporters between those data nodes.
The reason for the multitransporter setup is that nodes in the same node group can have very high communication requirements in situations where there is a massive amount of updates. One transporter scales to around 100-200 MBytes per second. With a multitransporter setup, RonDB has been shown to scale beyond 1 GByte per second of writes per node group.
It is possible to use multiple transporters between a process implementing the NDB API and the data nodes as well. But in this case, the API process will use multiple node IDs. Thus from the data nodes’ point of view, these transporters come from different API nodes.
A transporter is implemented either using a TCP/IP socket or using a shared memory transporter. Shared memory transporter can be used if the nodes are on the same machine.
Historically there have been other transporters as well such as a Dolphin SCI transporter, an OSE/Delta transporter and an experimental RDMA transporter.
Receive threads#
The transporters are divided onto the receive threads using a Round Robin. First, there is a round robin of all transporters that are not assigned to data nodes in the same node group (neighbor transporters). Next after assigning all of those we make another round robin assignment of all transporters to neighbor transporters.
In this manner, the load on receive threads is distributed in a fair manner.
Message routing#
Each message is sent to an address that is 32 bits similar to an IP address. The lowest 16 bits is the node id, next there are 6 bits indicating the block id and finally, there are 10 bits used as thread id.
Most messages are using the address to a physical destination that maps exactly to a thread and a block in this thread.
However, in RonDB we also support Query threads. These threads can execute signals on behalf of ldm threads. In RonDB 21.04 they can handle all Read Committed messages except those that involve disk columns. In RonDB 22.01, they can also be used for key read lookups that require locking with some limitations when used in the context of batching and disk columns.
A Query thread will only assist ldm threads that it shares L3 cache with and the number of query threads that can assist an ldm thread is limited to a maximum of 8.
When a message can be sent to a query thread the receiving block is the virtual block V_QUERY.
When a signal arrives at V_QUERY, the receive thread will use adaptive routing based on CPU usage information that is frequently updated. In addition, the receive thread can look at queue information that gives even newer real-time information about CPU usage in various receivers.
Send handling#
It is possible to define send threads in the configuration and it is done in the automatic thread configuration if the number of CPUs is sufficiently many. If no send threads are used the sending is handled by each thread on its own.
Each block thread will call a method called do_send now and then. In this method, a set of signals will be sent to other nodes if no send thread is in the configuration.
With send threads configured we will ensure that the send thread is awake to handle sending. However, the block thread can also assist send threads. The decision on whether to assist send threads is based on CPU usage information. The higher the CPU usage, the less assistance will be provided.
In the configuration, a parameter called ThreadConfig can be used to specify quite a few details of how the threads should behave. One possibility here is to state that a specific thread is never going to assist send threads.
Send buffer handling#
Send buffers are a global resource, they are allocated by the sending thread. The release of them however happens in the send thread or in a thread assisting the send thread.
In the figure below one can see that send buffers are allocated when the signal is sent in the block thread. A bit later we move the send buffers to the queue of send buffers for that node. This requires a mutex to protect this move. This move happens when the thread calls do_flush. Both do_flush and do_send calls are controlled by configuration parameters that can be affected by setting parameters in the ThreadConfig or by special management commands in the NDB management client. In our experiments we haven’t seen very much impact on setting those parameters differently, but lower values improve latency at the expense of throughput and vice versa if one increases the values.
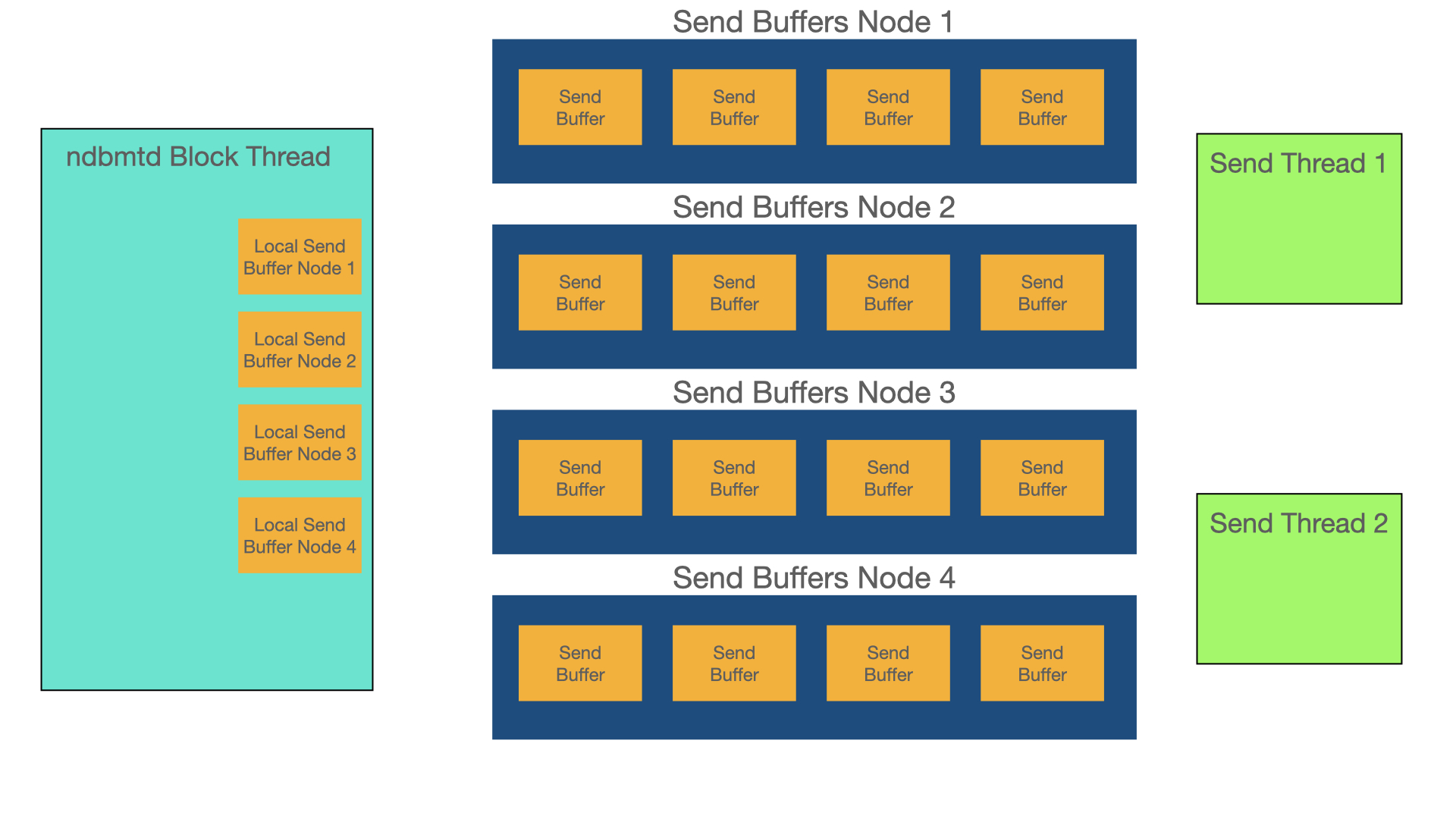
Finally, the send buffers are used to send to the other node using a transporters send method by a send thread or a block thread assisting a send thread.
Send buffers are a set of 32 kByte pages. Sometimes we need to pack those send buffers when we have a lot of pages with only a small portion of the 32 kBytes used. There are a lot of checks in the code for places to pack the send buffers.
Send frequency#
We have some controls in place to avoid that we send to another node too often. Sending too often leads to a higher load on the communication and can lead to cyclical increases and decreases of throughput. In an experiment with 32 nodes pushing many millions of operations per second, we saw performance go up and down by a factor of 2. By ensuring that there was always at least around 100 microseconds between sends to the same node we removed this cyclical behavior and performance was stable at 3 times the lower dips previously.
This behavior is adaptively handled in the send threads.
Send mutexes#
Previously there was a global mutex protecting lists of nodes ready to be sent to. This list was handled by multiple threads and assisted by a lot of other threads.
This mechanism didn’t scale as well as desired. In RonDB each send thread handles communication with a subset of the other nodes. Each such send thread maintains a list of ready nodes to send to. Block threads can only assist one of the send threads, thus the responsibility to assist send threads is distributed among the block threads.
This mechanism scales to very large data nodes.
In addition, each transporter has a mutex on the send buffer that has been moved to it. It also has a mutex used when performing the send operations.