Basic SQL statements#
Create a table#
Simplest form of table#
Creating a table happens in a normal CREATE TABLE statement in MySQL. What makes the table become a table in RonDB is that we add that ENGINE=NDB (NDBCLUSTER is a synonym of this and both are case insensitive). Here is a very simple table created in SQL.
This table is about as simple as a table can be in RonDB. It contains one column which is a 32-bit integer attribute. Here is the first distinction of tables in RonDB, all tables in RonDB must have a primary key. So when this table is created it is created with two attributes, the first is the column a and the second column is the hidden primary key which is an 8-byte unique key.
Simple table with primary key#
Moving on to a bit more sophistication we create a table with a primary key.
This table contains only one column a and this has a distributed hash index which is the primary access method that all tables use. Here is now the second distinction of tables in RonDB, a table that defines a primary key index defines two indexes on the table, the first is the distributed hash index and the second is an ordered index (a T-tree index data structure) which is local to each fragment replica.
By definition a primary key cannot have any columns that can have NULL values.
Simple table with only primary key hash index#
Moving to the next level of sophistication we define a table with only a primary key index, one column a and nothing more.
By adding USING HASH to the index definition we clearly specify that the index will only be a hash index. The reason that normal primary key indexes are also containing an ordered index is that almost everyone using a database expects an index to be an ordered index always. Since the base primary key index in RonDB is a distributed hash index it means that we add another index to ensure that newcomers to RonDB get what they expect from an index.
Simple table with primary key hash index and an index#
Now we move on to a table with also an additional index and an additional column.
This adds a new column b and an ordered index on this column. This is a pure ordered index and there is no hash index involved in normal indexes.
Simple table with primary key hash index and a unique index#
Now we move to a unqiue index and a primary key index.
Unique indexes is the third sophistication of RonDB tables. Unique indexes are implemented as a special unique index table that have the unique index as primary key and the primary key is the field in this table. In addition the unique key definition adds an extra ordered index on the table in the same fashion as the primary key. The reason is that the unique key index is the normal distributed hash index used for all tables. Thus it isn’t an ordered index and we add this to make life easier for newbies to RonDB.
The above definition adds the following: a table t1 with a column a and a column b, also the distributed hash index on the column a and an ordered index on the column b.
In addition another table t1_unique (it is not its real name, we simply use it here as a possible name) that have the column b as primary key using a distributed hash index and another column a.
We add an internal trigger from table t1 to table t1_unique, this trigger fires every time we perform an insert to insert into the unique table and every time there is a delete a trigger is fired to perform a delete in the t1_unique table. At updates two triggers are fired that performs an insert of the new value in the unique index table and a delete of the old value in the unique index table.
Behind this fairly simple definition of a simple table using a primary key and a unique key we have a fairly complex index structure and trigger handling to ensure that all indexes are kept in synch with each other. The unique index is updated transactionally within the same transaction as the update of the base table.
A simple table with a generated primary key#
In MySQL a concept called auto_increment is used to generate unique keys in increasing value. For InnoDB tables the step is 1 between inserted rows always. In RonDB we can have multiple APIs and multiple MySQL Servers hitting the table at the same time. We have implemented auto_increment as one row in a special system table. When we get the next key from this table we get a range of keys. By default this range is set to 1 key. This is a configurable item in the MySQL Server configuration option ndb-autoincrement-prefetch-sz.
The default here is set to 512 which should be able to handle any insert load. For any real RonDB application it is quite likely that this value should be set to at least 32 to ensure that the updates of the rows to get a new unique key isn’t becoming a bottleneck. If insert rates on the table is beyond a thousand inserts per second and even smaller than that if latency is high between nodes in the cluster this value must be increased to avoid running into a bottleneck when creating unique keys. Setting the value to 1024 means that millions of inserts per second can be sustained on the table. It can be set to at most 65535.
Here is the syntax used to create a table with autoincrement on the primary key. It is highly recommended to use BIGINT (64-bit integer) for auto increment columns to avoid running out of unique keys.
More complex tables#
Using the simple examples we can move on to very complex tables. The limit is that we can have at most 511 columns in a table and the sum of the column sizes must be less than 8052 bytes for the fixed size columns, 30000 Bytes for the maximum row size of all columns. BLOB tables are treated a bit special, we’ll cover those later in this chapter. We can have up to 64 indexes per table as well.
RonDB can store any field type available in MySQL and using any character set available in MySQL. A word of caution here is to remember that complex character sets use more than one byte per character. The default behaviour in RonDB is to use UTF8MB4 which uses up to 4 bytes per character. If another character set is desired one can set the character set both on table level and on column level.
The syntax used is the same syntax used for any tables in MySQL. We will describe later some specialisation available to RonDB tables.
Tables in RonDB can have GIS columns, but cannot have GIS indexes, they cannot have fulltext indexes. RonDB tables can have JSON attributes, it is possible to have stored generated columns that are indexed in RonDB, it is not possible to have an index on a virtual generated column in RonDB tables.
Altering a table#
Once a table have been created we can use ALTER TABLE to modify the
table. Some of the changes to the table can be done using a copying
alter table statement and some can be done as online alter table
statements.
Online alter table statements#
Our aim for RonDB is that tables should always be available for read and write after its creation.
There is one caveat to this. Due to the internal software structure in
the MySQL Server it isn’t possible to write to a table in the same MySQL
Server as the change is happening within. What this means is that in
order to create a highly available cluster it is a good idea to have a
special MySQL Server used to execute online ALTER TABLE statements.
The fact is that the RonDB data nodes allows for writes to be performed
on a table where indexes are added, columns are added or the table
partitioning is changed. However the actual MySQL Server where this
change is performed only allows reads of this table. This is due to
internal locking in the MySQL Server that is hard to get around. The
MySQL Server assumes that even online operations are not truly online.
To execute truly online ALTER TABLE statements these should be
executed from a MySQL Server purely used for metadata statements.
RonDB is actually more online than what one MySQL Server can be. Other MySQL Servers can thus continue to operate on the table using reads and writes since these MySQL Servers are not aware of the locks inside the MySQL Server that performs the change.
The following operations can be changed as online alter table statements.
-
Add an ordered index
-
Add a unique index
-
Drop an ordered index
-
Drop a unique index
-
Add a new column
-
Add a foreign key
-
Drop a foreign key
-
Reorganise table to use new node groups
-
Add partitions to a table and reorganise
-
Set/Reset the Read Backup feature on the table
-
Rename table
Operations that are not supported as online alter table statements are:
-
Remove a primary key
-
Change primary key columns
-
Change columns
-
Drop column
Primary keys are the vehicle we use to control all online changes to a table. Changing the primary key of an existing table is not possible. Drop column could be implemented, but it would require tables to use a very dynamic data structure that have a high CPU overhead.
It is likely that even more ALTER TABLE statements will be possible to
perform as online alter table statements as development of RonDB moves
on.
The syntax used to ensure that we only allow an online alter table statement performed is the following:
In this case we want to add a new column c to a table t1. By adding the algorithm=inplace syntax we ensure that the operation will only be successful if we can perform it as an online alter table statement.
Another method is to set the configuration option
ndb-allow-copying-alter-table to 0, this has the effect of not
allowing copying alter table and failing any ALTER TABLE that attempts
to use a copying alter table. By default this option is set to 1.
Copying alter table statements#
In some cases we want the table recreated as a new table and the old table data to be moved to the new table. In this case the syntax used is the following:
In this case the change will be performed as a copying alter table statement even if an online alter table statement is possible.
It is possible to set the configuration option ndb-use-copying-alter-table to 1 to get the same effect as providing the syntax algorithm=copy. By default this option is set to 0.
Querying a table#
Querying an RonDB table is using normal SELECT statements. Here we focus on the syntactical parts of SELECT queries and there is nothing special about SELECT queries for RonDB. They are using the same syntax as any other table in MySQL.
SELECT COUNT(*) queries#
One specific variant of queries have a special treatment in RonDB. This is the SELECT COUNT(*) from table query. In this case we want to know the number of records in the table. Actually there is no method to get the exact count of this since we cannot lock the entire table in the entire cluster. It is possible to lock a table in one MySQL Server but this doesn’t prevent other MySQL Servers or API nodes to update the table.
There are two methods to get the approximate row count in the table. The first one is the optimised one that uses a local counter in each fragment to keep track of the number of rows in a partition of the table. This method is quick and provides a good estimate. The other method is to scan the entire table and count the rows in the table. This method is comparably very slow.
The optimised method is default, to use the slow method one can set the MySQL Server configuration option ndb-use-exact-count to 1.
Configuration options that affect SELECT queries#
The configuration option ndb-join-pushdown set to 1 means that we will attempt to push joins down to the RonDB data nodes for execution and setting it to 0 means that we will not even attempt to push down joins to the RonDB data nodes. It defaults to 1. More on pushdown join in a later chapter.
The option ndb-force-send can be set to 1 to ensure that we attempt to send immediately to the RonDB data nodes when we have something ready for sending in our connection thread. If not we will give the responsibility to the sender thread or send based on how much data is waiting to be sent and how many have attempted to send before us. This adaptive send method can sometimes provide better throughput but can increase latency of some queries. It is set to 1 by default.
The option ndb-batch-size gives a boundary on how many bytes that is allowed to be sent to the MySQL Server node as part of a scan query before we return to the MySQL Server to handle the returned rows. By default it is set to 32 kByte. Increasing the batch size can in some cases be positive for query performance, but also increases risks of overloads in the network buffers.
ndb-index-stat-enable enables use of index statistics. It is on by default. For high concurrency loads it could be beneficial to disable ndb-index-stat-enable if only simple queries are executed in the connection. In RonDB 21.10 this bottleneck has been fixed, thus in RonDB 21.10 it should not be necessary to even consider this optimisation.
The configuration option ndb-cluster-connection sets the number of API node connections that the MySQL Server will use, by default it is set to 4 if you have used the managed version of RonDB or installed through the cloud script. If you installed yourself the default will be 1.
For larger MySQL Server that goes beyond 8-12 CPUs it is a good idea to use multiple API node connections per MySQL Server to make the MySQL Server scale to use more CPUs. The connection threads will use different cluster connections in a round robin scheme.
In managed RonDB all MySQL Servers use 4 cluster connections. This means that the MySQL Server in managed RonDB scales to at least 32 CPUs. Scaling to more CPUs is possible, but going beyond 32 CPUs for a single server is less efficient compared to using more MySQL Servers. In RonDB there is no specific benefit in using very large MySQL Servers since we can have hundreds of MySQL Servers in a cluster.
Writing to a table#
There are many different ways of writing to a table in MySQL such as INSERT, DELETE, UPDATE. MySQL also supports REPLACE, INSERT INTO DELAYED and a few other variants.
These statements use the same syntax for RonDB tables as they do for normal MySQL tables. There are a few configuration options that can be used to change the behaviour of those writing SQL statements.
The configuration option ndb-use-transactions is specifically designed for large insert statements. Given that large transactions might be too big to handle for RonDB, those statements can be split into multiple transactions. RonDB can handle a number of thousand row updates (configurable how many) per transaction, but for extremely large insert statements (such as LOAD DATA .. INFILE) that loads an entire file in one statement it is a good idea to split those extremely large transactions into more moderately sized transaction sizes. When this is set to 1 (default setting) the large insert statements will be split into multiple transactions. LOAD DATA INFILE will always be split into multiple transactions.
Transactions#
Everything in RonDB is performed using transactions of varying sizes. In MySQL one can run in two modes, the first is the autocommit mode which means that each SQL statement is treated as a transaction.
The second variant is to enclose all statements belonging to a transaction by BEGIN and COMMIT (ROLLBACK if necessary to roll back transaction).
RonDB supports using autocommit and the BEGIN, COMMIT and ROLLBACK handling in MySQL. RonDB doesn’t support using XA transactions. RonDB doesn’t currently support savepoints.
Drop/Truncate Table#
A table can be dropped as in any normal MySQL table. We will drop tables in a graceful manner where the table is completing the running queries before the table is dropped.
No special syntax is used for dropping tables in RonDB.
MySQL supports dropping all tables in a database by dropping the database where the tables reside. This is supported by RonDB.
Indexes#
RonDB support three different types of indexes. Normal primary key indexes consists of both a distributed hash index and an ordered index on each fragment replica. Unique key indexes implemented as a separate table with the unique key as primary key and the primary key as columns in the unique index table (these also have an ordered index on the unique key). All normal indexes are ordered indexes.
Indexed columns in RonDB must be stored in main memory, columns that are stored on disk using a page cache cannot be indexed. All tables must have a main memory part and at least one primary key hash index.
It is possible to define a table without primary key, in this case the MySQL Server will add a hidden primary key to the table since RonDB requires all tables to have a primary key.
It is possible to define a pure hash index for primary keys and unique keys by using the keyword USING HASH in SQL.
RonDB supports adding and dropping indexes on a table as an online alter table statement. This statement can either be an ALTER TABLE statement or a CREATE INDEX statement.
Index sizes#
In many DBMSs the size of an index is dependent on the number of fields in the index. This is NOT true for RonDB. In RonDB the size of a distributed hash index and an ordered index is a constant overhead. The reason is that we only store a row id reference in the index and not any values at all.
In the hash index we store one word per row that is used for some bits and also used to find the lock owner when we have ongoing transactions on the row. There is also one additional words with a row page id. Each row entry is 8 bytes. In addition the hash index has some overhead in how those 8 bytes are found that adds a few more bytes to the overhead. There is a container header of two words for each container and there is around 5-10 entries per container. There will also be some free space between containers since those are stored in a number of fixed places and the placement into the pages is more or less random based on the hash of the key. Around 15 bytes of overhead one should account for in the hash index per row. One important part of the hash index is that we store a part of the hash in the index. This makes it possible to skip rows that are not equal faster compared to a lookup of the primary key.
hash(PartitionKey) % Number of Hash maps = distribution_id
distribution_info(distribution_id) -> Set of nodes storing replicas
hash(PrimaryKey) >> 6 = Hash index page id
hash(PrimaryKey) & 63 = Hash index page index
tree_lookup(Hash index page id) -> Physical page reference
get_mem_address(physical_page, page index) -> Memory adddress to container
In the box above we show how the partition key is hashed to find the hash map to use for the row. The hash map is used to translate into the partition id and this will give a set of current alive nodes storing the replicas for this row.
When we get to the node we use the hash on the primary key (often the same as the partition key unless the table was created with a specific partition key). We use part of the hash to find the page id where the bucket of the key element is stored in. A second part is used to find the page index in the page. The page and page index will point to the first container in the hash bucket.
Each bucket consists of a linked list of containers, normally there is only one container, but there is no specific limit to how many containers there can be.
The container header contains references to the next container in the bucket if one exists and a few other bits. Each container contains anywhere between zero and eleven key elements. Each key element contains a reference to the row and a part of the hash of the key and a few more bits. A key element is 8 bytes in size. Most of this stores the row id, but there are also scan bits and hash bits and some other bits.
The hash pages are 8 kBytes in size, if we cannot store any more container in the same page as the linked list we can use overflow pages that only store overflow containers.
Given that the containers can be wildly different in sizes we have implemented a variant where we can have containers both starting from the left and from the right. Thus we can have 2 containers in each container entry in the page. Each container entry is 112 bytes. The sum of the sizes of the containers in the container entry is always 112 bytes or less.
At the bottom of each page we have eight overflow containers, these can also be filled from both ends.
The overhead of the hash index is around 15 bytes per row. A significant part of this comes from the element and container overhead. The rest is empty unused slots and memory areas that comes through the random nature of the hash index.
The hash index is used in all primary key lookups and unique index lookups. It is used for full table scans and a number of scans that are part of metadata changes.

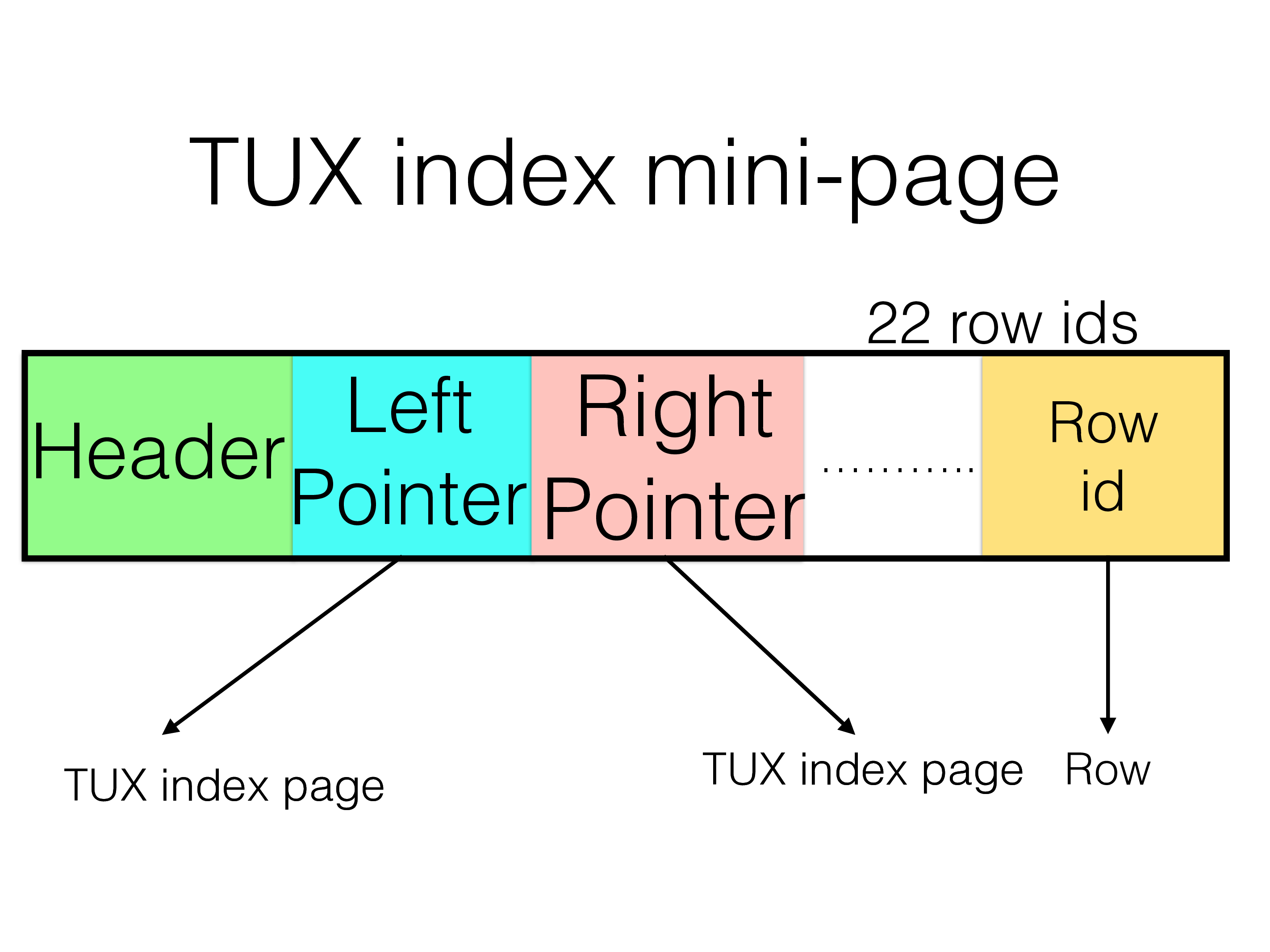
The ordered index is implemented as a T-Tree. A T-tree is similar to a balanced binary tree. A balanced binary tree stores the pointers to rows only in the leaf nodes. The T-tree stores pointers to rows in all index pages. The T-tree index uses mini-pages that are 256 bytes in size (these mini-pages are stored in the DataMemory).
Each such mini-page contains a header, it contains a reference to a new mini-page for those keys that are smaller than the left pointer. It contains a reference to a new mini-page for those keys that are larger than the right pointer. The pointers are row ids that contain the boundary values.
For those keys that are between the left and right the reference to the row is found among the references in the mini-page. The search within those references uses a binary search algorithm.
In addition the mini-page also stores a subset of the left and right key values. These are used to avoid having to go and read the rows for the most part. This subset of the keys is an important optimisation of the index operation.
These mini-pages are stored in a binary tree structure that is kept balanced. When we are searching the index and we come to a container we have three choices. Go left, stay or go right. The most common is to go left or right since it is only at the end of the search that we stay in the same index mini-page.
The benefit of the T-tree structure compared to a binary tree is that it saves memory in that only 2 pointers are needed per entries. It also brings benefits that we can avoid going to the actual rows in many cases where it is sufficient to use the subset of the key to discover whether to move left or right or stay.
The overhead of an ordered index stays at around 10 bytes per row. Most of this memory is used for the row reference.
The main use case for the ordered index is to perform range scans.
Foreign Keys#
RonDB support foreign keys between tables. More on this in a separate chapter on RonDB foreign keys.
Optimize/Analyze Table#
OPTIMIZE table command can be used on RonDB tables to remove any fragmentation on variable sized rows and dynamically formatted row. It cannot defragment the fixed size part in memory since this would change the row id of a row and this is a very important part of the recovery algorithms in RonDB.
The ANALYZE table command is used to build up the index statistics on an RonDB table. It can generate large speedups on some SELECT queries.
BLOBs#
RonDB supports BLOBs of any size. We will describe this in more detail in a specific chapter on BLOBs for RonDB.
Row format of RonDB tables#
RonDB supports a few row formats for its tables. We will describe those and the effect of them in the next chapter.
Disk Data Columns#
RonDB supports storing non-indexed columns on disk. We will describe this in more detail in a separate chapter.
MySQL Replication of RonDB tables#
RonDB supports using MySQL Replication in a fairly advanced manner. We’ll cover this in a specific part of this text.