Computer Model#
Modern computers are designed more or less as networks of processors that are interconnected in various ways. We will discuss configuration of RonDB a lot in this documentation and describing how to make optimal use of modern computers. To support this we will describe the computer model to ensure that the language is defined when describing CPUs, memories and networks. Given that this development is fairly new every processor manufacturer have invented their own language to describe their CPUs. Here we define a language that can be used to describe any type of CPU.
A modern CPU consists of multiple CPU cores. The largest Intel CPUs can have up to 40 CPU cores. The newest AMD Epyc CPUs can have 64 cores in the high-end server models. Internally within one CPU core there can be one or more processors, we will call these processors CPUs. CPUs is what is seen by the operating system. The operating system knows about CPU cores, CPU sockets and so forth, but when a thread is scheduled to execute, it is scheduled to execute on a certain CPU within one CPU core.
Modern servers most often have more than one CPU chip, the most common is that each server have two sockets. These CPU chips used to be called CPUs simply, but we opt here to define these as a CPU socket, the CPU chip is placed into a CPU socket on the motherboard. Each such CPU socket houses a number of CPU cores which in turn houses one or more CPUs.
This defines the language where we use CPU, CPU core, CPU socket and computer to define ever larger parts of the computer. We will now describe how the current processors available on the market map into this language such that one can translate the language you are familiar with to the language used in this book.
In some sections we might use the term CPU thread instead of CPU to clarify that we are talking about one CPU inside a CPU core.
CPU Core#
The most commonly used processors to use to run RonDB are the x86 variants. We have limited support of the ARM processors, this means that it isn’t of the same high quality yet as the x86, this is work in progress. SPARC processors are no longer supported.
In this presentation we will focus on describing the processor architecture for modern x86 processors.
All modern x86 CPU cores use 2 CPUs per CPU core. Since 2017 this is also true for the AMD x86 processors using the new AMD architecture.
An important feature of those 2 CPUs is what they share and what they don’t share. The figure below shows this for the x86 CPUs.
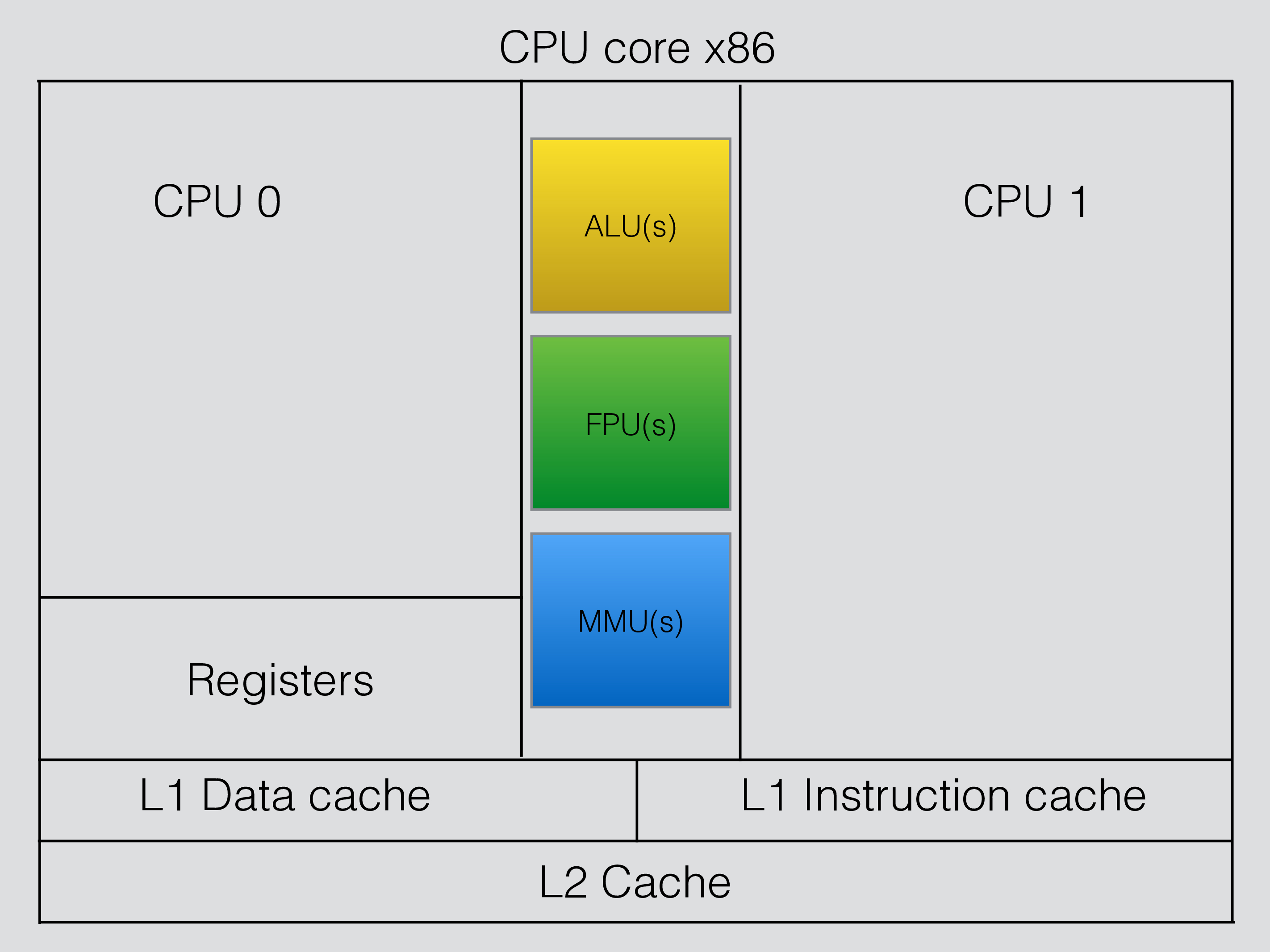
Each CPU has its own set of registers. Thus a CPU will always execute as if it was on its own. It will have more wait states compared to a CPU core with only one CPU since there are some shared resources as well.
Each CPU core has an L1 (Level 1) instruction cache, this is usually around 32 kBytes in size. Each CPU core has an L1 data cache as well, this is about the same size or smaller than the L1 instruction cache. Next there is an L2 cache which is used for both data and instructions in each CPU core. This is usually around 256 kBytes to 512 kBytes in size. All of those caches are shared between the two CPUs in the CPU core.
The CPUs share a set of computing resources such as ALUs (integer operations), FPUs (floating point operations) and MMUs (memory address calculations). Since each CPU can issue several instructions per cycle there is quite a few such resources inside a CPU core. This means that to a great extent a CPU will not be slowed down so much by another CPUs usage of computational resources.
The main reason that running two threads in parallel on the two CPUs doesn’t provide twice the throughput is the sharing of the caches in the CPU core.
Modern CPUs have improved greatly in this area, in the first processors of this type that Intel came out with there was a slowdown due to parallel use of computational resources. This is much smaller now. The support for using both CPUs in the CPU core is now much improved.
Our experiments show that for the most part using both CPUs in the CPU core will deliver 50% more throughput compared to just using one CPU in the CPU core. It will pay off in almost all occasions to use all CPUs in the CPU core. With the introduction of query we also use the second CPU in the CPU core to achieve balanced load on CPU cores.
The next level of CPU caches is the L3 cache. This is usually shared amongst a set of CPU cores and how many those are is different per processor variant. The AMD Epyc processor have 4 CPU cores that share an 8 MByte L3 cache. With the Zen 3 version of AMD Epyc this was extended to use 8 cores per chiplet that share a L3 cache.
Intel CPUs have similar sets of sharing where a number of cores share an L3 cache, it is not the same for all Intel products. Thus it is hard to generalise there.
When we configure the RonDB data nodes in how they map the various threads into CPUs, we need to take into account the consideration of which threads that should share CPU core. The RonDB data node consists of a number of threads that all have an internal scheduler and each such thread can be heavily used. There are different thread types, one thread type to execute the data storage and recovery algorithm, another thread type to handle transaction coordination, one thread type to handle receive from the network, others to send to the network and others to handle other things such as IO, metadata and so forth.
One method that brings a bit of benefit (a few percent improvement of throughput) is to ensure that the two threads sharing a CPU core should be of the same type if possible. Thus we use the same instructions for both the CPUs and this has a positive effect on CPU caching.
Another variant to consider is to configure a thread which is using a lot of CPU with another thread that uses less CPU. This has the effect that CPU usage on the hot thread is going up when the other thread is more active than usual. There might not be sufficient amount of lightweight threads to share with the heavy threads.
In RonDB we have strived to automate the configurations of threads and binding those to subsets of the CPUs in the computer. It is still possible to control this in detail through configuration though.
In this chapter we will discuss what ids the OS gives to the various CPUs in the box to ensure that we can make a proper configuration of RonDB data nodes.
CPU Socket#
The next level for a processor is the CPU socket. This means one physical processor that contains a set of CPU cores. It could contain anything from 2 CPU cores in the most minimal configurations as e.g. in the Intel NUCs I have at home playing around with. It can go up all the way to 64 CPU cores in one CPU socket for AMD architectures.
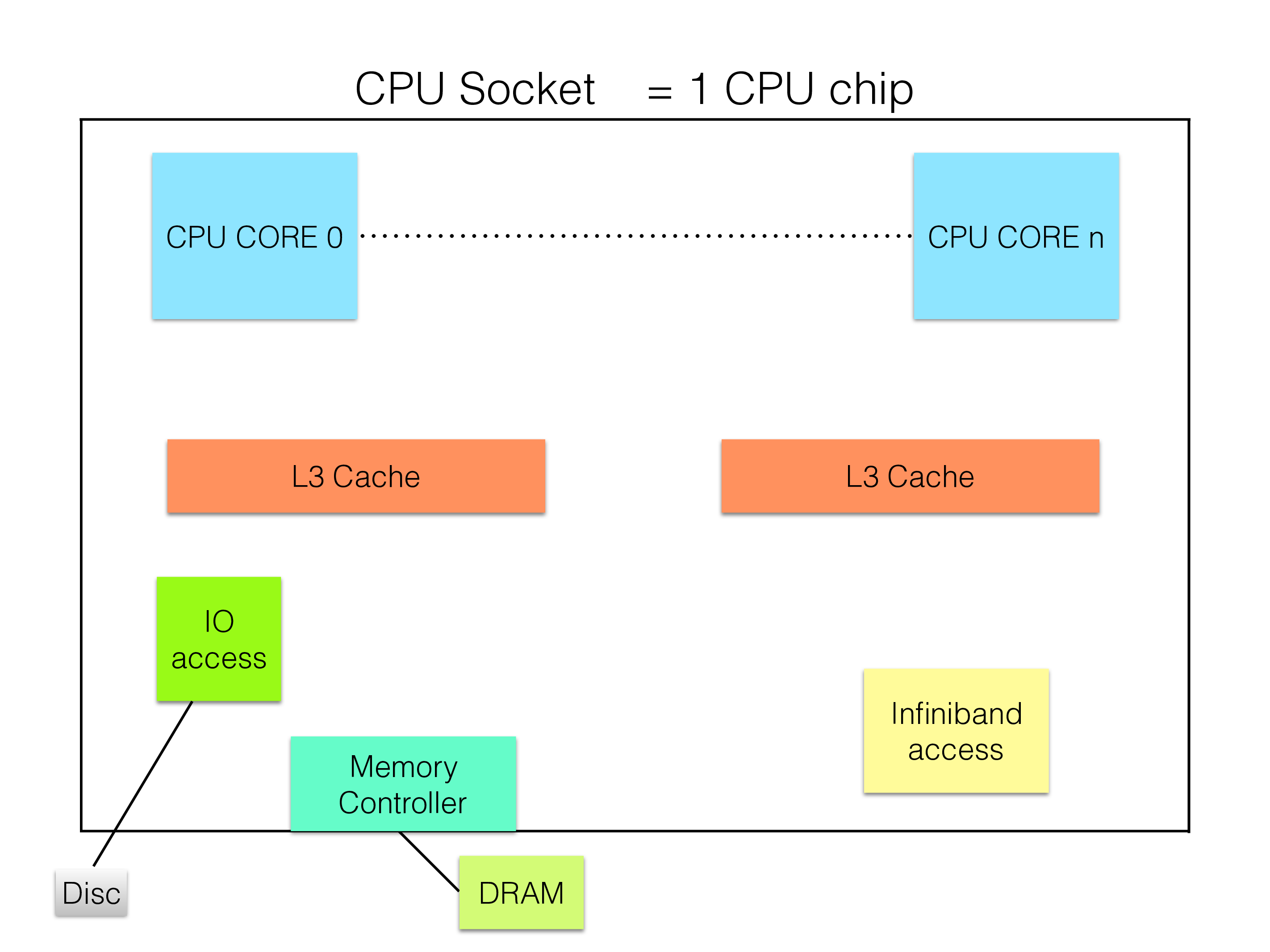
When defining a configuration it is important to consider CPU sockets. For RonDB data nodes it is usually sufficient to house the CPU resources on one CPU socket. It is also important to consider bandwidth to processor memory. Each CPU socket have its own set of resources to access the memory in the machine. Each CPU socket can access all memory in the machine. But the bandwidth is bigger to the memory if all CPU sockets are used.
Thus having CPU sockets in mind for both memory and communication is important.
Computer#
With one or more CPU sockets in the machine we are ready to look at other memory components. Naturally for a memory-based database the RAM memory is important. Memory is normally attached to a CPU socket and bandwidth to and from memory is usually high.
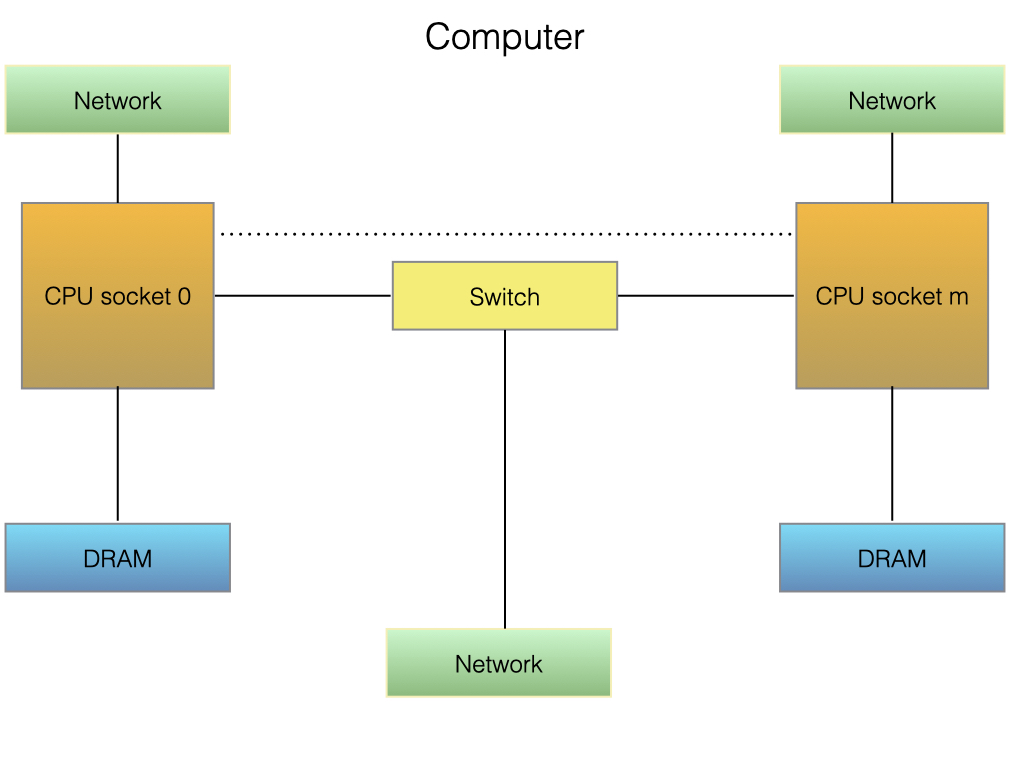
From an operating system point of view the memory is attached to processes. Each process can execute in a number of OS threads that all of them are able to access to the same memory.
The OS can provide shared memory between processes that could be used to communicate e.g. between a MySQL Server and an RonDB data node when they are located on the same machine.
Files are stored independent of processes and are read and written through the file IO APIs of the OS. RonDB use normal files to store recovery data and the data on disk parts.
Computer network#
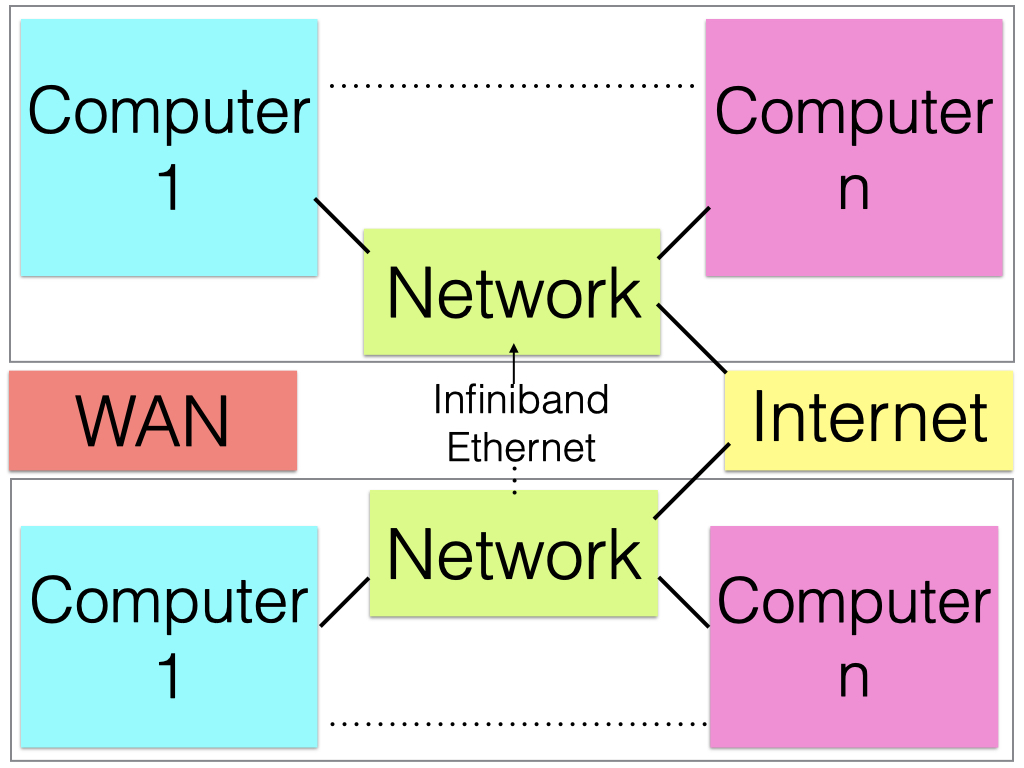
The networking does mostly go through some sort of IO bus. RonDB works best with high bandwidth networking. It is fully possible to run with Gigabit Ethernet, but it is possible to get the network to become a bottleneck in this case with as little as 2 CPU cores and most definitely with 4-6 CPU cores. For any server-like environment it is important to run RonDB on at least 10G Ethernet. Infiniband or high-end Ethernet installations can be useful. In benchmarks we have been able to make 25G Ethernet a bottleneck.
Distributed Data Centers#
Many RonDB installations are done in large distributed data centers. In these centers one finds often a homogenous networking infrastructure where often it is efficient to communicate within one rack. Communication between racks has usually less bandwidth available and one should attempt to place an entire RonDB inside one rack. Modern cloud installations have worked hard to make it possible to communicate between all machines using the full bandwidth.
When using RonDB with replication between clusters one will often use installations in different parts in the country or world for higher availability. In this case the inter-cluster bandwidth is an important factor.