Internals of Global Replication#
The following chapter will describe the internals of asynchronous replication in RonDB. Thereby, we will focus on how MySQL replication servers communicate with the RonDB data nodes. The setup and communication between MySQL replication servers will be covered in the next set of chapters.
MySQL Replication Background#
The MySQL server supports different storage engines of which RonDB is one. Global Replication in RonDB is built on top of MySQL Replication. MySQL Replication uses the concept of a binlog to store database changes to files. However, most other storage engines store this binlog on the same MySQL Server where the writes occur. This is not possible using RonDB because we:
-
can have up to hundreds of MySQL Servers in one cluster
-
can write to RonDB without using a MySQL Server (using the NDB API)
Instead, we use specialized MySQL Servers that we will call MySQL replication servers. All MySQL replication servers in the primary cluster will therefore gather all logs of writes in the database and write them to their independent binlog. They can therefore be labeled as binlog servers.
In the backup cluster, on the other hand, a MySQL replication server:
-
retrieves log records from a binlog server in the primary cluster
-
places them into relay log files
-
batch-writes these into the backup cluster
Naming conventions for MySQL replication servers#
In the texts about Global Replication, we will be using many different naming conventions for the MySQL replication servers. When doing so, one can assume:
-
one primary cluster
-
one backup cluster
-
two MySQL replication servers per cluster (for high availability)
-
two replication channels
With this in mind, we will use the following naming conventions:
| Primary/source cluster | Secondary/replica/backup cluster | |
|---|---|---|
MySQL replication server |
Primary replication channel ➡️ |
MySQL replication server |
MySQL replication server |
Backup/standby replication channel ➡️ |
MySQL replication server |
Data node triggers#
In the RonDB data node, we have a trigger mechanism that is used for diverse purposes. It can be used:
-
to maintain local T-tree indexes
-
to maintain global unique indexes
-
to maintain foreign keys
-
during an online reorganization of table partitions
For Global Replication, we have asynchronous triggers that gather and send information about committed changes in RonDB data nodes.
Each time a write of a row (update, insert, delete) is committed, it can trigger an asynchronous write of the change to a local module called SUMA (SUbscriber MAnagement). The SUMA block is executing in one thread, the rep thread.
There are multiple ldm threads that can commit row writes. In the RonDB architecture, these log messages of a committed row write are called events and the user can access these events using the NDB Event API.
Epochs#
As discussed in the chapter about the Global Checkpoint Protocol, we commit operations in groups that are committed to durable media (files on top of hard drives, SSDs or other persistent media).
These groups are called global checkpoints and occur at configurable intervals, by default 2 seconds. For Global Replication, we have one more grouping of transactions into something internally called micro GCPs. The name we use in documentation is epochs. Epochs is a term that was described in the research literature on replication between databases already more than 25 years ago.
By default, we have 20 epochs for every global checkpoint. Thus they arrive with 100 milliseconds intervals.
Epoch Buffers#
The SUMA block in each node organizes the events in several Epoch Buffers. We can have multiple epoch buffers. Epoch buffers are maintained only in memory.
As soon as an epoch is completed we can send the epoch over to the requester of the events. In this case, the requester is a MySQL replication server. It could be any other application that uses the NDB Event API. As an example, HopsFS uses the NDB Event API to maintain a searchable index in ElasticSearch to files stored in HopsFS.
We work together with the other data nodes in the same node group to send an epoch over to the MySQL replication servers.
At some point, all the MySQL replication servers have acknowledged receiving the epoch from the RonDB data nodes, and the other RonDB data nodes in the node group have acknowledged that they have completed their transfers to the MySQL replication servers. Then, the buffers used by the epoch can be released in the data nodes.
The data nodes in a node group share the responsibility to send the epochs to the MySQL replication servers. If a data node fails, the other data node(s) in the same node group must complete the sending of the buffer.
In the figure below, we see the protocol to transfer epochs from the data nodes to the MySQL replication servers within a single clyster. We have 2 MySQL replication servers and two data nodes in the node group. One node group can have a maximum of 4 data nodes. There can be any number of MySQL replication servers although normally it would be 2.
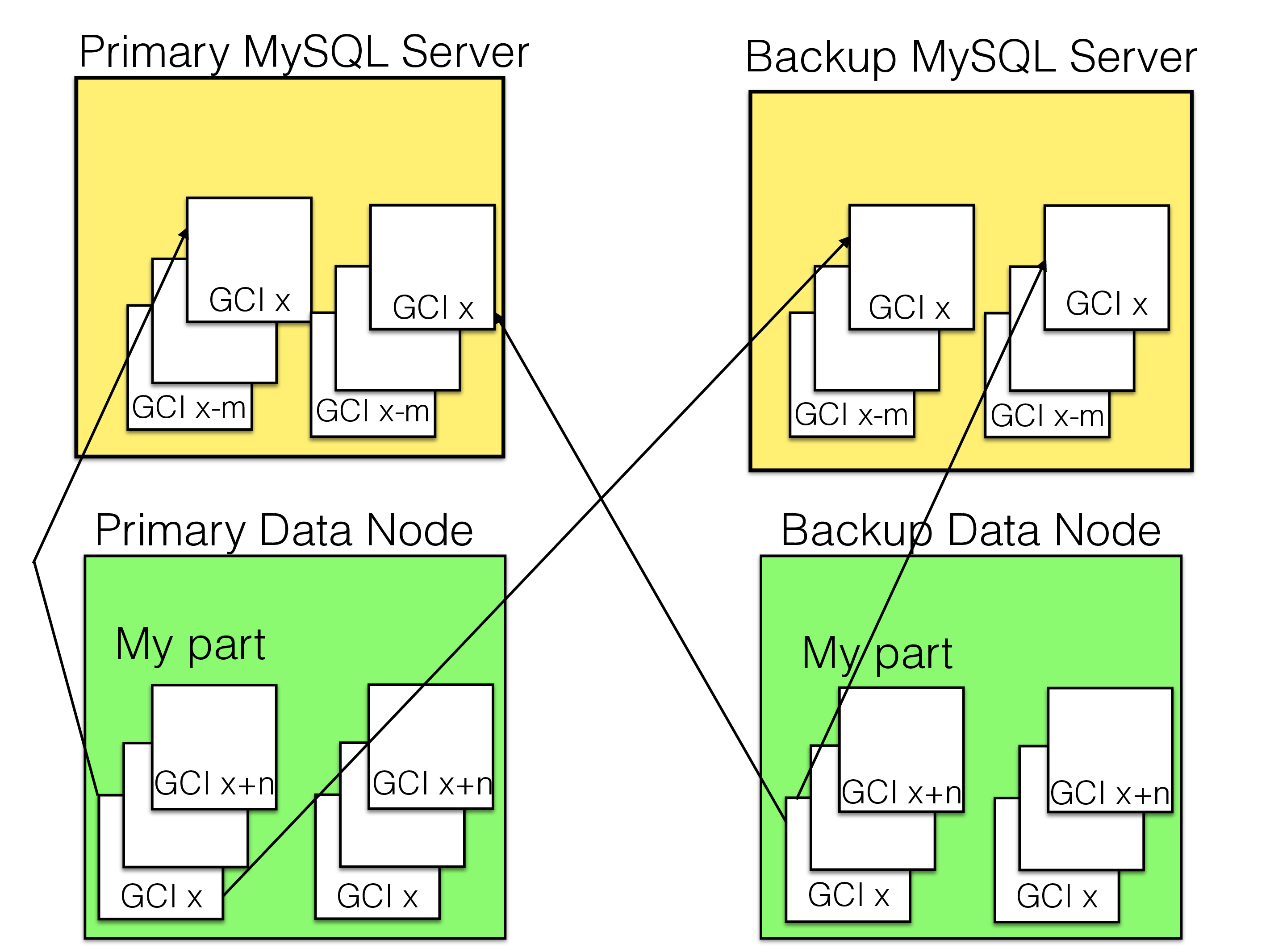
In this figure, we only show how one node group transfers its epoch data to the MySQL replication server. All node groups must do this, and this is performed independently of each other. Thus as soon as one node group has completed the transfer of epoch n we can release the epoch buffers for this epoch in the nodes in the node group.
In the figure, both data nodes in the node group gather their data for the epoch in their epoch buffers. When the buffer is complete and the transfer of the previous epoch is completed, we start sending our part of the epoch buffers to the MySQL replication servers. We send our part to all the MySQL replication servers. The other data node also sends all its parts to all the MySQL replication servers.
When a MySQL replication server has received an epoch buffer from one node group it acknowledges this to the data nodes. The MySQL replication server will send this acknowledgment when it has received the epoch from the entire cluster.
As soon as a data node receives a confirmation from all MySQL replication servers about receiving all epoch data, it can release the epoch buffers connected to this epoch.
We need to have sufficiently large epoch buffers to gather epochs even in situations where node crashes, short bursts of high update rates or a few larger transactions slow things down.
These values are configurable through MaxBufferedEpochs that limits
the number of epochs we will buffer. By default, this is set to 100,
allowing a bit more than 10 seconds of buffering.
MaxBufferedEpochBytes sets the limit on the buffer sizes for epoch
buffers. By default, this is set to 25 MiB. A cluster that handles a
hundred thousand transactions per second could be writing 50 MiB/s or
more. In this case, it would be a good idea to extend the buffer size to
500 MiB instead.
Running out of epoch buffers means that the replication channel is at risk. Running out of epoch buffers in all data nodes in a node group means that the MySQL replication servers cannot continue replicating and thus the entire replication channel will be lost. In this case, the replication channel must be restarted.
Thus it is very important to ensure that the epoch buffers are large enough. Failure of a replication channel will not stop transactions in a cluster from proceeding. The operation of the local cluster has higher priority than the event handling.
Send buffers#
There is a lot of data sent from the data nodes to the MySQL replication servers that act as binlog servers. Similarly, there is a lot of data sent from MySQL replication servers to the RonDB data nodes when they act as replica appliers.
The send buffers to communicate between MySQL replication servers and RonDB data nodes are more likely than other buffers to run out.
Send buffer memory can be configured per link between nodes if desirable to change the send buffer for those links to a higher value compared to other nodes.
GAP events#
When a MySQL replication server in the primary cluster has lost the
ability to write the binlog, it will insert a GAP or LOST_EVENT
event into the binlog. Common reasons for this to happen are:
-
The binlog server has lost connection to the primary cluster
-
The binlog server ran out of event buffer memory
-
The binlog server ran out of binlog disk space
When the replica MySQL server encounters a GAP event in the binlog, it
will stop. In this case, we must hope that we have a backup binlog
server that has not encountered a GAP event at the same place. If this
is the case, we can cutover to the backup binlog server. This can mean:
-
Activating the standby replication channel
-
Pointing the primary replica applier in the backup cluster to the backup binlog server
If we do not have any log of the missed event, we must run a full backup and restore the backup cluster from this backup.
MySQL replication server internals#
The following describes the internals of the MySQL replication. However, we will skip most of the details here, since the MySQL manual and many books on MySQL already describe this thoroughly.
The following figure shows the main active threads in the MySQL servers during RonDB’s Global Replication:
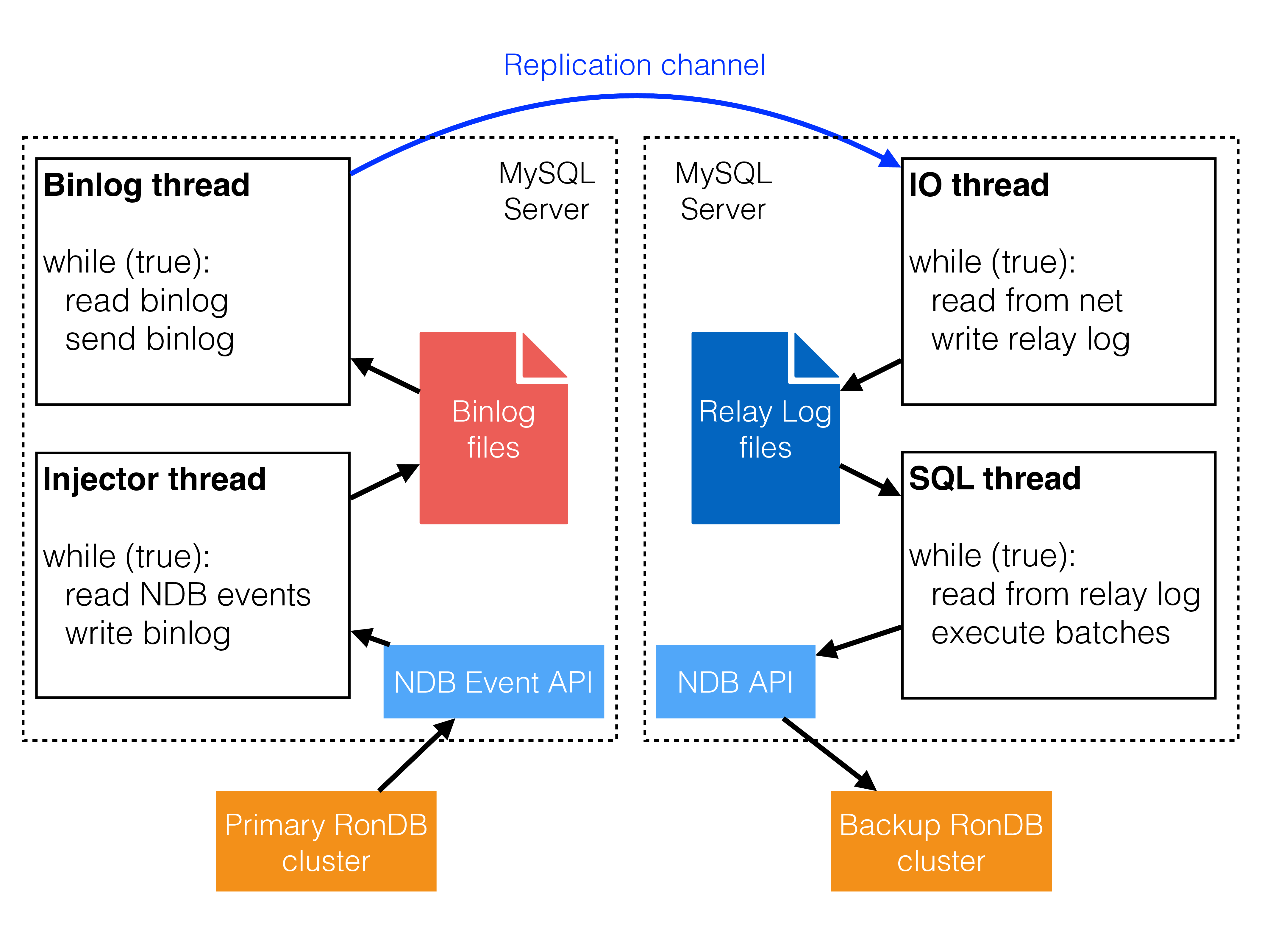
Both the MySQL Server in the primary cluster (i.e. the binlog server) and the MySQL Server in the backup cluster (i.e. the replica applier) use two main threads.
The binlog server’s threads:
-
the injector thread: this reads NDB events and inserts these into the binlog files
When writing into the binlog files, a memory buffer is used. To ensure that this writing doesn’t become a bottleneck, it is possible to set the binlog cache size through the MySQL option
binlog-cache-size. By default, this is set to 32 KiB. It is more or less mandatory to set it higher. -
the binlog thread: this reads the binlog files and sends the information to the replica applier in the backup cluster.
Another important parameter to consider setting is the size of the
binlog files. If file size is too small there will be too many hick-ups
when files are changing. At the same time, very large files can become
problematic because it will be difficult to purge the binlog files. It
is set through the MySQL option max-binlog-size which
defaults to 1 GiB. This is fine for most use cases. The MySQL binlog
files must be purged manually.
The replica applier’s threads:
-
the IO thread: this reads over the network from the source MySQL replication server. It stores the information in relay log files.
-
the SQL thread: this reads from the relay log and inserts an entire epoch using a single RonDB transaction at a time. The reason is that the epochs are the only consistency points - in the middle of applying an epoch the database isn’t consistent.
The relay log files are automatically purged as soon as they have been used.
Characteristics of replica applier#
The replica applier used by MySQL Replication is single-threaded. At the same time, this single thread works on very large batches where transactions spanning the last 100 milliseconds are applied in one large transaction.
Given that the NDB API can sustain very high levels of batching, the performance of this single thread is extremely good. It can handle more than a hundred thousand operations per second.
Limitations of Global Replication#
With a proper setup of Global Replication, it should be possible to reach at least well beyond 100.000 row writes per second.
However, since there are many parts of the replication between clusters that are single-threaded, there are limits to how many transactions per second can be handled. The most demanding write applications can therefore cause problems when using Global Replication.
A solution to this is to shard the application such that each shard has a cluster. This has been done by a handful of NDB’s most demanding users of Global Replication.
Scaling Global Replication#
One approach to scale Global Replication is to have separate MySQL databases use different replication channels. This works if one’s application is not running cross-database transactions. In Hopsworks we have multi-tenant clusters, meaning they have one database per user. This makes it fairly easy to scale replication by assigning databases to a set of replication channels instead of using a single replication channel. In this manner, Global Replication can handle millions of row changes per second.
Bottlenecks in Global Replication#
There are a few potential bottlenecks in Global Replication:
Primary & backup cluster#
- MySQL Server resources:
Sharing MySQL servers for writes/reads and replication can cause performance bottlenecks.
Solution: Use dedicated MySQL Servers for replication to achieve the best possible throughput. These replication servers should use one cluster connection and 4 CPUs each. In the edge case where a replication server is both a source and a replica, it should use 8 CPUs.
Primary cluster#
-
CPU utilization within MySQL replication server:
Solution: Using 4 CPUs allows both the receive thread and the injector thread to have its own CPU. The other two CPUs can then be used to send data to the replica MySQL server(s).
-
Binlog injector thread in MySQL replication server:
The receive thread for the NDB API and the injector thread perform a lot of work in this part.
Solution: To ensure that the binlog injector thread doesn’t perform any of the receive thread activities, one should set
ndb-recv-thread-activation-threshold=0. This ensures that all receive activity is handled by the NDB API receive thread and not by any other thread at all. -
Rep thread in the data nodes:
This thread receives change information from the ldm threads and buffers this information to send it on to the API nodes that have subscribed to those changes. We have however never seen this become a bottleneck.
Solution: One can lock this thread to an exclusive CPU.
Backup cluster#
-
Batching in MySQL replication server:
Solution: Set
replica-allow-batchingto increase the throughput by a magnitude. -
CPU utilization within MySQL replication server:
Solution: Using 4 CPUs per MySQL Server allows the replica IO thread, the replica SQL thread, the NDB API receive thread and the send thread to each have their own CPU.
-
SQL thread in MySQL replication server:
Solution: Set
ndb-recv-thread-activation-threshold=0to ensure that the replica SQL thread doesn’t have to handle any NDB API receive thread activity. -
Tc threads in the data nodes:
Too few tc threads can cause a bottleneck when executing the epoch transactions. This is the least likely performance bottleneck.
Solution: Ensure a sufficient amount of tc threads