Non-blocking Two-Phase Commit (2PC)#
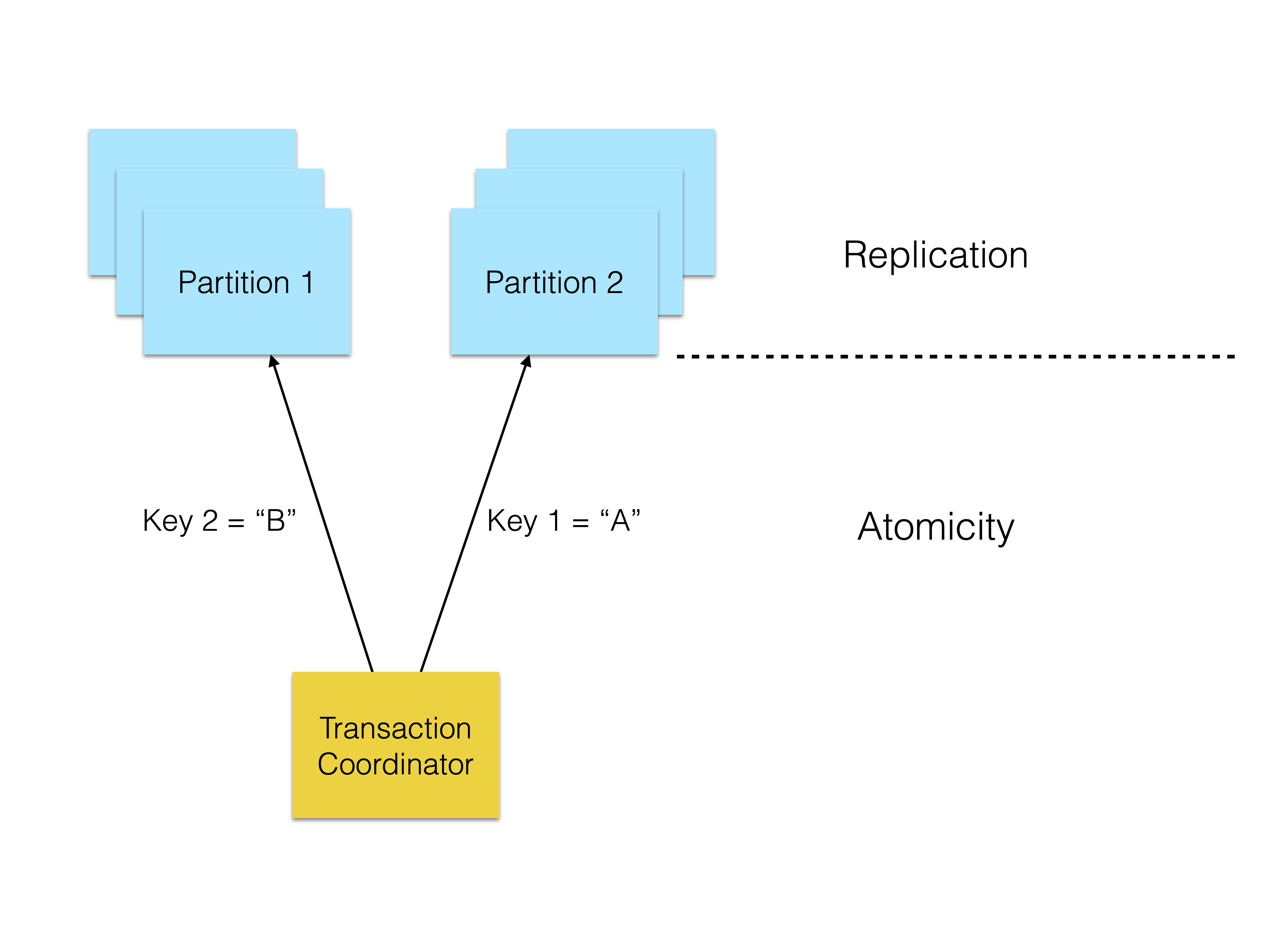
When databases become too large to fit on one node, data can be partitioned and spread across multiple nodes. However, now a transaction spanning multiple rows may also span multiple partitions and thereby multiple nodes. This means that there is a need for a protocol to ensure that the transaction is atomic - either all or none of the nodes have applied the changes of the transaction.
A popular protocol to guarantee this is the two-phase commit (2PC) protocol. This protocol divides between a transaction coordinator (TC) and the participants that contain the data. The TC is responsible for coordinating the transaction, which is generally divided into two phases: prepare and commit. This is the protocol used in RonDB.
Atomicity vs. Replication#
When handling cross-partition transactions with distributed partitions, we need an atomic transaction protocol. However, this is not inherently synonymous with replication. How partitions are replicated is a separate problem and can be solved with consensus protocols such as Paxos or Raft. Databases such as CockroachDB for instance use Raft for replication and 2PC for atomicity.
Consensus algorithms tend to work on a quorum basis. This means that a majority of nodes must agree on a decision. It is therefore highly recommended to use an odd number of replicas and at least 3.
RonDB however, uses 2PC for both atomicity and replication. This means that our 2PC protocol touches all replicas of all partitions. We avoid the requirements of quorums by:
-
using a fixed hierarchy of nodes (defined by cluster-join time)
-
using a management server or API server as an arbitrator
If there is a network partition, the arbitrator will decide which partition is allowed to continue. RonDB is therefore highly available with two replicas.
Blocking Protocols#
The 2PC is often regarded to be a blocking protocol. This refers to the situation where a node fails during the transaction. This may cause the other nodes to be undecided on whether to continue the transaction or not. In the face of atomicity, this is particularly problematic, since we want to ensure that either all or none of the nodes have applied the transaction. In the worst case, the nodes need to wait until the failed node has recovered.
In-memory databases have a ground advantage over disk-based databases in this regard. This is because the former can commit the transaction in memory - but if a node fails, its commit is not (immediately) durable. When the node recovers, the transaction is gone. This means that the other nodes can continue or abort the transaction without having to wait for a participant node to recover.
Another tricky situation is when the transaction coordinator fails after having sent out the prepare messages. In this case, the participants may wait for the commit message from the TC for an indefinite amount of time. By non-blocking we mean that the protocol has solved this problem.
Another term for non-blocking is fault-tolerant.
Two vs. Three Phase Commit#
Another paradox of the 2PC is that it often informally contains 3 phases - the last being the complete phase. The complete phase is used to both release locks and clear the commit state of the transaction on each node.
RonDB’s protocol is also called 2PC due to historical reasons. It used to be the default that the transaction acknowledgment (transaction has succeeded/failed) was already returned after the second phase. Hence it was deemed appropriate to name it a 2PC protocol. However, with the introduction of the Read Backup feature, these acknowledgments are now sent after the complete phase. In RonDB, the Read Backup feature is enabled by default but can be disabled on a table level.
A more typical three-phase commit protocol however contains an additional pre-commit phase, which does not exist in the 2PC. Using this phase is another strategy to avoid blocking.
Developing a Custom 2PC#
The following properties of RonDB have to be kept in mind when designing our 2PC protocol:
-
Data is partitioned by rows
-
Locks are used on a row level (not on a partition level)
-
Each partition has a primary (P) and 0-2 backup (B) replicas
-
Cross-partition transactions are supported (thereby also multi-row transactions)
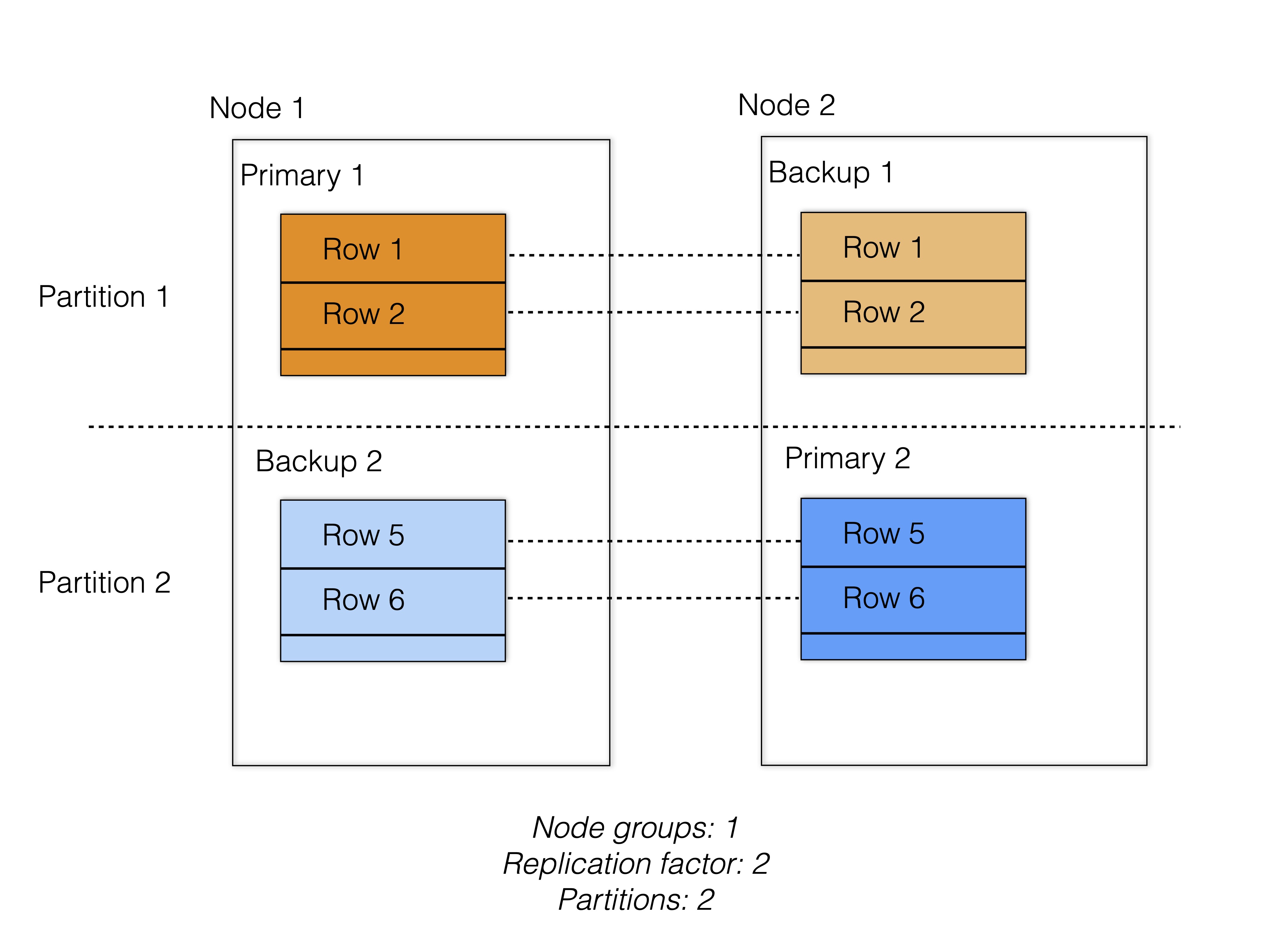
Since our 2PC tackles both atomicity and replication, we need to take into account that it will be affected by both the number of replicas and the number of rows touched by the transaction. The number of replicas can be anything between 1 and 3 and the number of rows depends on the transaction.
In the following, we will first explain the general architecture of our 2PC protocol in comparison to the conventional versions. We will do so by using the metrics throughput and latency as functions of replicas and rows. We will then explain our additional modifications to make the protocol non-blocking / fault-tolerant.
Original 2PC#
Applied to RonDB, the "original" 2PC is a direct protocol between the transaction coordinator and all participants (both primary and backup replicas). Here, the participants do not communicate with each other. This achieves a great amount of parallelism, but also a high amount of messages.
The following figure shows the protocol.
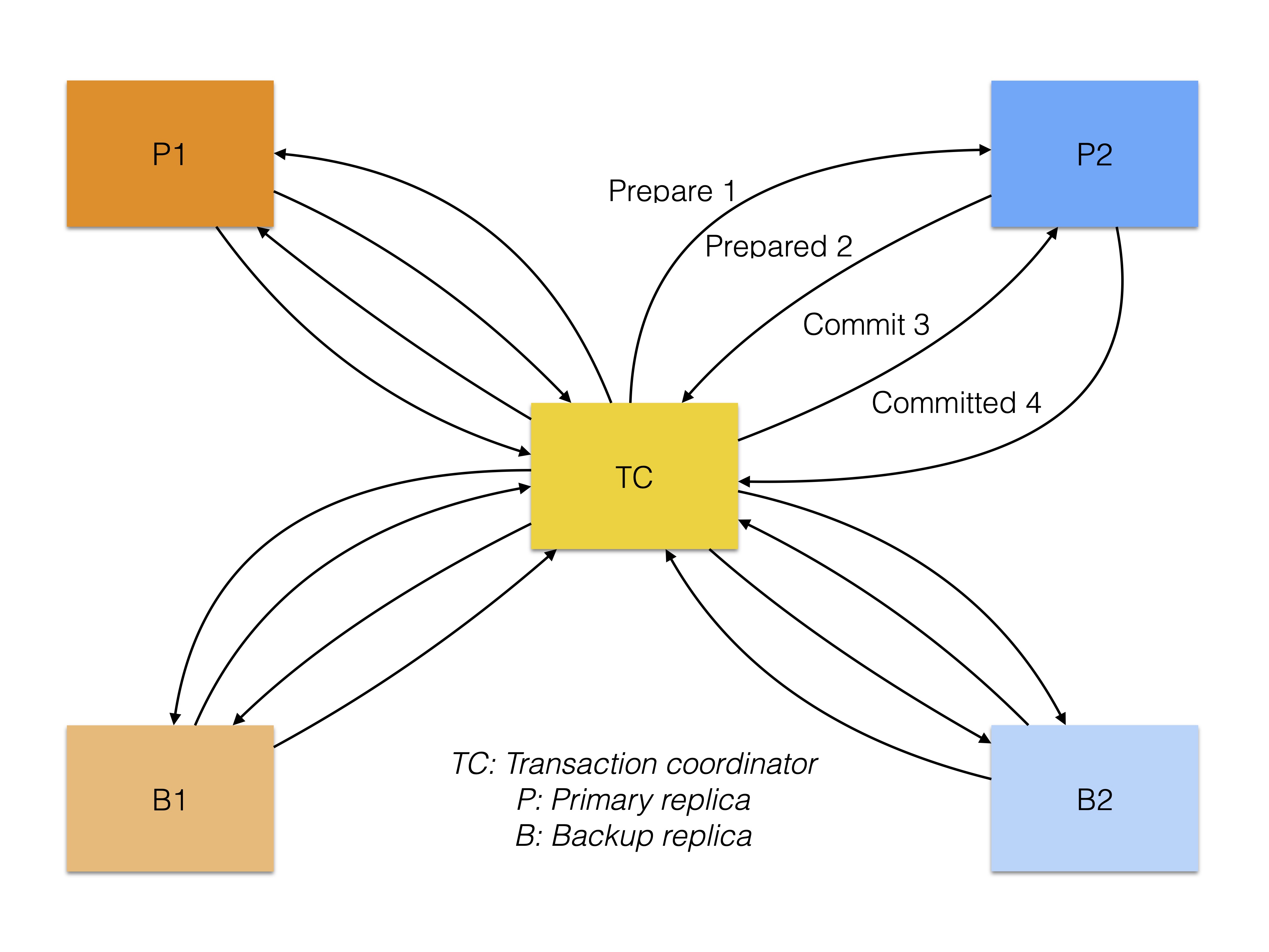
-
Number of messages (throughput): 4 * participants = 4 * rows * replicas ≤ 12 * rows
-
Messages to wait (latency): 4
Example in figure:
-
Number of messages = 4 * rows * replicas = 4 * 2 * 2 = 16
-
Messages to wait = 4
By sending many messages in parallel, this variant achieves very low latency but the high amount of messages hurts throughput.
A weakness of this variant is the high risk of deadlocks within a row. Since the prepare phase is sent out to all replicas of a row in parallel, two transactions may lock the same row in different replica order and therefore block each other.
Linear 2PC#
Another variant of the two-phase commit protocol is called the linear commit protocol. This protocol sends the prepare message from the first participant to the last participant in serial order. Instead of returning to the transaction coordinator to commit the transaction, the commit message is sent in serial order back to the first participant. The transaction is committed by the last participant.
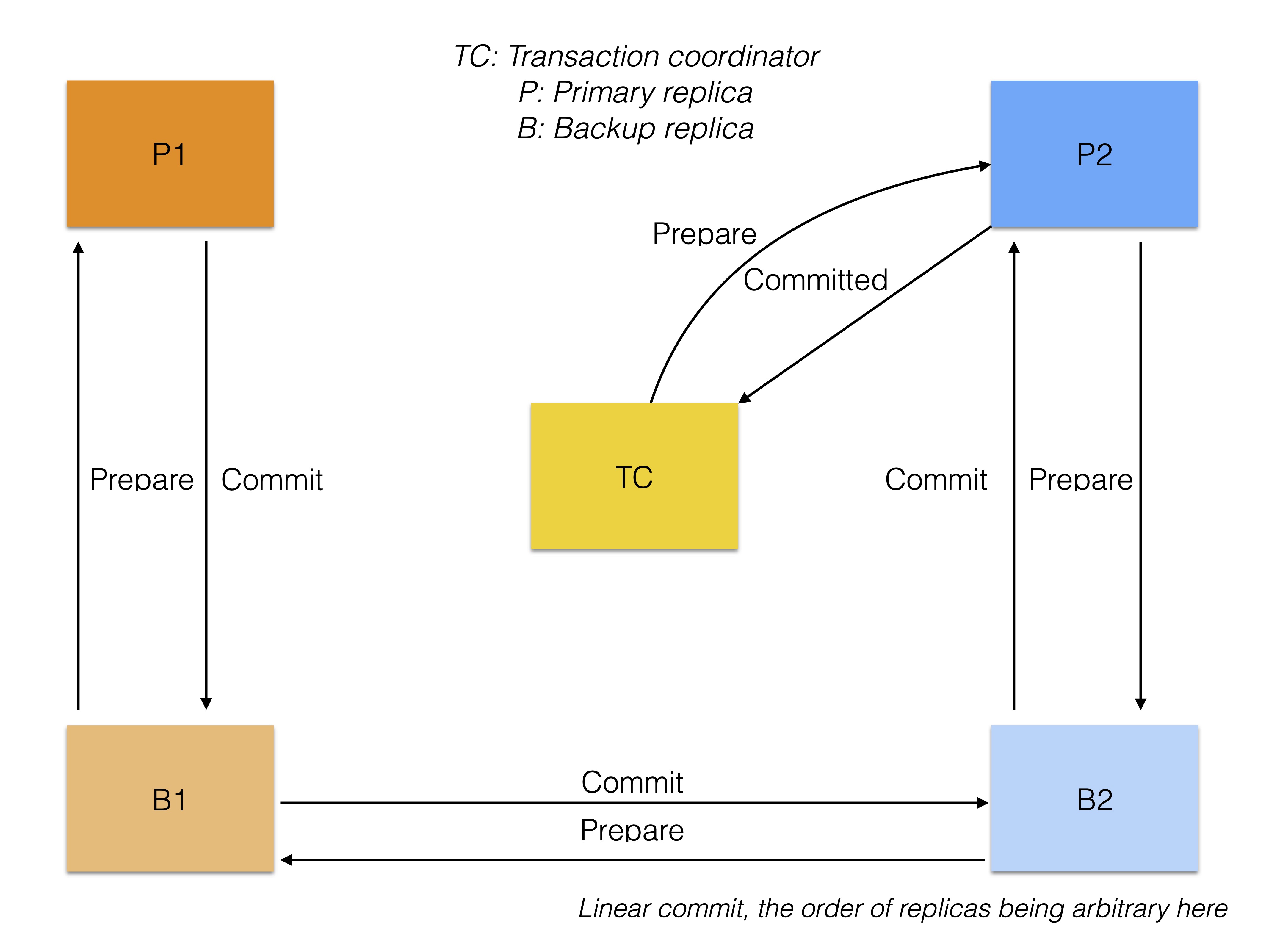
-
Number of messages (throughput): 2 * participants = 2 * (rows * replicas) ≤ 6 * rows
-
Messages to wait (latency): 2 * participants = 2 * (rows * replicas) ≤ 6 * rows
Example in figure:
-
Number of messages = 4 * rows * replicas = 2 * 2 * 2 = 8
-
Messages to wait = 4 * rows * replicas = 2 * 2 * 2 = 8
The linear commit protocol saves more than half of the messages and therefore performs very well in terms of throughput. However, the latency becomes higher with the amount of participants in the transaction. Transactions that span a large amount of rows therefore achieve unpredictable latency.
Another property that is already achieved in this model, is that one can use a feature called primary copy locking to avoid deadlocks within a row. This means that we always lock the primary replica of a row before locking the backup replica.
RonDB’s 2PC#
Given that we want to achieve scalability AND predictable latency it would be beneficial to use a combination of the original protocol and the linear commit protocol. In RonDB we kept some of the ideas of the two-phase commit protocol but changed important details in it.
Our idea is to use the parallelism of the original commit protocol for multiple rows, but use the linear commit protocol within the replicas of one row. Similarly to the original commit protocol, we return to the transaction coordinator after the prepare phase, and the transaction coordinator also initiates the commit phase.
The following figure shows our new protocol.
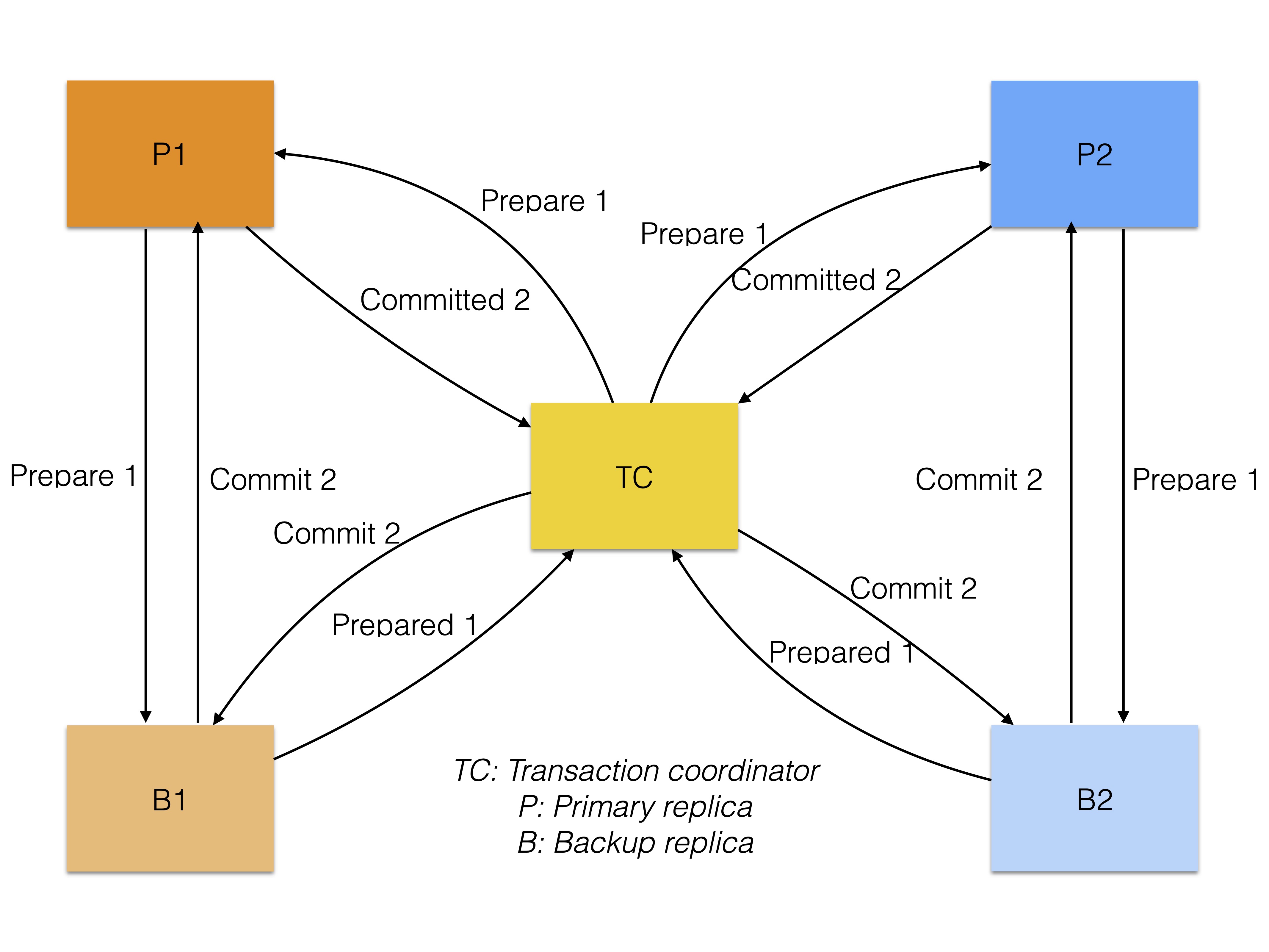
-
Number of messages (throughput): (2 * (replicas + 1)) * rows ≤ 8 * rows
-
Messages to wait (latency): max(2 * (replicas + 1)) ≤ max(2 * (3 + 1)) = 8
Example in figure:
-
Number of messages = (2 * (replicas + 1)) * rows = 2 * (2 + 1) * 2 = 12
-
Messages to wait = max(2 * (replicas + 1)) = max(2 * (2 + 1), 2 * (2 + 1)) = max(6,6) = 6
As one can see, the latency becomes predictable, whilst the throughput is reduced in comparison to the original commit protocol. With 3 replicas, it is reduced by 1/3, with 2 replicas by 1/4 and with 1 replica it has the same throughput as the original 2PC. The latter is because their architectures become identical.
The latency is still up to twice as high as with the original 2PC. However, given that we decreased the cost of communication, we expect to get this latency loss back at high loads. We use a lot of piggybacking to ensure that the real number of messages is a lot lower.
Since we’re using a linear commit within a row, we can once again use primary copy locking to avoid deadlocks within a row. To handle deadlocks between rows, RonDB uses time-out based deadlock detection.
Another feature of this model is to return the commit message in reverse linear order, whereby the primary is the last to commit. Since the primary knows that all other replicas have committed, it can safely release its locks without waiting for the complete phase. This has the advantage that we can read the update directly from the primary replica. The default Read Committed read will consider locked rows as uncommitted and therefore still read the previous committed value on the backup replicas.
Locking in RonDB:
A fully committed row in RonDB is stored in DataMemory. This is where it is read from. When updating a row in RonDB, one creates a new version of the row in TransactionMemory. Given that the application is not using a shared or exclusive lock, locking a row during the prepare phase will only lock this new version. The default lockless Read Committed read will still be able to read the previous version of the row in DataMemory. When removing the locks, the updated data is simultaneously moved from TransactionMemory to DataMemory. This mechanism is called WORM locking (Write Once Read Many). It means that one can read whilst writing.
Complete Stage#
Even though the primaries have already released their locks, the complete phase is still run on both primary and backup replicas. This is because we will still need to release the commit state on the primaries. This is kept after releasing the locks to rebuild a TC state in case of a late-stage TC failure. Naturally, the complete phase also releases the locks in the backup replicas. Just like the first two phases, the complete phase is run in parallel for each row.
Read Backup Feature#
If we want to guarantee read-after-write consistency, we have two
options of when to return the transaction acknowledgment (signal
TC_COMMIT_ACK) to the application:
-
After the commit phase ➡ Only allow reading from the primary replica
This decreases the latency of writes but reads may have to be redirected to the primary. Depending on the geolocational distribution of replicas, this may cause higher latency for reads.
-
After the complete phase ➡ Allow reading from any replica
This increases the latency of writes but reads can be performed from any replica. Therefore the latency of reads can be improved by reading from the closest replica.
This is called the Read Backup feature and is enabled by default in RonDB. It can be disabled on a table level.
Disabling the Read Backup feature would neither be possible using the original nor the linear 2PC protocol. This is because the primary cannot release its locks safely before the complete phase has finished. It does not know whether the backup replicas have committed or not.
Achieving a Non-blocking Commit Protocol#
As mentioned earlier, a blocking 2PC protocol is a protocol where a node/row is blocked for an indefinite amount of time because it is in the prepare phase and another node has failed.
So far, this scenario can happen in our protocol if the transaction coordinator fails after having sent out prepare messages. Therefore, we have designed a takeover protocol, which re-creates a transaction coordinator with the state of transactions that was lost with the previous one. When doing so, we ensure that we can always decide on committing or aborting any ongoing transactions in the cluster. More on this protocol is below.
In the special case where all replicas of a node group fail, the cluster will also fail. There, we will always need to recover those transactions that are also durable on disk. After recovery, we are not blocked anymore either. This is due to the Global Checkpoint Protocol which allows recovering from a transaction consistent state. Transactions that have not been committed by all will not be recoverable and therefore also not be blocking.
Takeover Protocol#
As mentioned earlier, the takeover protocol is a necessity to avoid blocking of data nodes/rows in case of a transaction coordinator failure.
One variant used in another distributed telecom database developed in the 1990s was to use a backup transaction coordinator. We weren’t satisfied with this solution, since this solution would still fail if we had two simultaneous node failures.
Instead, we opted for designing a special failure protocol to rebuild the transaction state at failures. This is possible since the RonDB data nodes are part of an integrated active-active system. This is not possible in most modern distributed database solutions where each data server is also an independent database (the so-called federated database model). Examples of such databases are MySQL InnoDB Cluster, Galera Cluster, MongoDB and many others.
Our takeover protocol is thereby a protocol to rebuild all transaction states where the failed node was the transaction coordinator. It is initiated by the first transaction coordinator thread instance in the oldest data node in the cluster - the master data node. This transaction coordinator will then take over the completion of these transactions.
The first step of the takeover TC is to send the message LQH_TRANSREQ
to all Local Data Managers (LDMs) in the cluster. Each LDM thread (or
more accurately each LQH block instance) will go through all ongoing
transactions. It will then return the transaction information of every
transaction that used the failed node as transaction coordinator to the
takeover TC. It will inform the takeover TC once it has finished.
After having requested all information about a set of transactions, the new transaction coordinator will decide whether each of these transactions should be committed or aborted based on how far it got in the process. If any node heard a commit decision it will be committed. The new transaction coordinator will also inform the API nodes of the transaction outcome.
In case the takeover TC doesn’t have sufficient memory to handle all transactions in one go, it will only handle a subset of the transactions at a time.
The final stage of this protocol is the reporting of the node failure handling being completed. When this is done, we know that all transactions that were ongoing in the failed node at the time of the crash are either committed or aborted.
There is one exception where the API nodes will however not be explicitly informed of a transaction outcome. This is when using the default Read Backup feature, which disallows reporting a transaction as committed before the complete phase has finished, guaranteeing read-after-write consistency on all replicas. To spare messages, the complete message is however piggy-backed onto the message that reports the completed node failure handling. Since this is the last message in the protocol and all aborted transactions should have been explicitly reported already, we can safely assume that the transaction is committed.
We keep special commit ack information in the data nodes to ensure that the API can always be informed of the transaction outcome if the API itself survives.
Writing and Persisting of Data#
The actual writing of the data is done as part of the prepare phase in
RonDB. The prepare phase thereby both locks and writes. In terms of
signals and blocks, the prepare phase consists of the LQHKEYREQ signal
being sent around in the order: TC ➡ LQH(P) ➡ LQH(B) ➡ TC. Since the
prepare phase happens before any commit has happened, this write is
however still reversible. The exact signal flow is described in more
detail in here.
Since RonDB has significant requirements on low latency, writing data or even committing it will also not persist it directly. Instead, the data is persisted asynchronously in batches via the REDO log. RonDB thereby supports Network Durability, which means that data is considered durable once it has been committed in memory on several computers. This weakens the ACID property D (Durability).
Part of the REDO log is the Global Checkpoint Protocol (GCP), which goes hand in hand with our 2PC protocol. The GCP is a method to serialize all writes to the database using global checkpoints, identified by Global Checkpoint IDs (GCI). As part of the protocol, the REDO log will flush once per GCI. Due to the serializability of the GCPs, we can therefore restore a cluster into a transaction- consistent state after a cluster crash.
The GCP affects the 2PC protocol because it blocks every TC from sending out commit messages every time it increases the GCI. This is needed to make the GCP serializable.
Conclusions#
To summarise - the RonDB transaction protocol has the following requirements:
-
Accommodate high throughput & low latency
-
Avoid deadlocks
-
Non-blocking during multiple node failures in all phases
-
Non-blocking during cluster failures
-
Restore a consistent database after a cluster crash
With our custom two-phase commit protocol, we have achieved the following:
-
Low latency due to asynchronous persisting of data in batches (REDO log)
-
Predictable latency due to parallel message passing to different rows
-
High throughput due to linear message passing within replicas of single rows
-
Minimised deadlocks due to primary copy-locking
-
Non-blocking during node failures due to takeover protocol
-
Non-blocking during cluster failures due to serialisable Global Checkpoint Protocol