Node groups (Shards)#
A basic theme in RonDB is the use of node groups. The RonDB data nodes
are formed in node groups. When starting the cluster one defines the
configuration variable NoOfReplicas. This specifies the maximum number
of nodes per node group. When defining the nodes in the cluster the data
nodes are listed in the NDBD sections. The data nodes will be put
automatically into node groups unless specifically configured to be in a
node group.
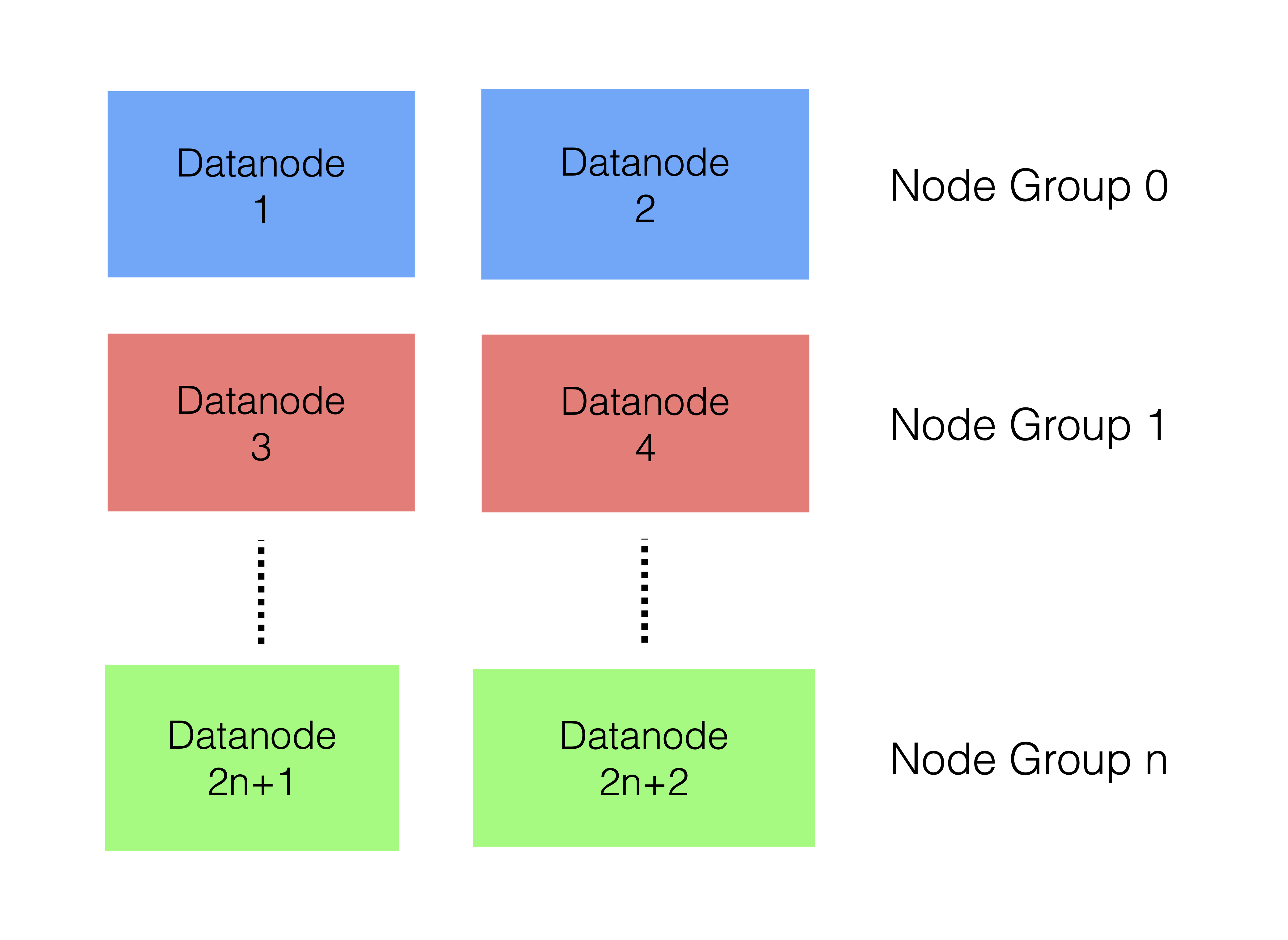
E.g. if we define 4 nodes with node IDs 1,2,3 and 4 and we have
NoOfReplicas=2, nodes 1 and 2 will form one node group and nodes 3 and
4 will form another node group.
Node groups work similarly to shards. Thus all the nodes in a node group (shard) are fully replicated within the node group. In the example above, node 1 and node 2 will have the same partitions and the same data. Thus all rows that exist in node 1 will also be present in node 2. The same holds for node 3 and node 4. However, none of the rows in node 3 and node 4 will be present in node 1 and node 2. An exception is tables using the fully replicated feature.
The main difference to standard sharding solutions is that RonDB supports foreign key relations between node groups and it supports distributed queries over all node groups. Due to these features, a cluster will fail if all nodes in one node group fail. Nonetheless, the fact that our data is split up into node groups means that we can generally handle a higher number of node failures. More information on how node groups make the cluster more resilient and how they handle network partitioning can be found in the Resiliency Model.
Partitioning#
Regardless of node groups, RonDB also partitions its data (also called fragments). To explain how partitioning works, we will first define the two following terms for convenience:
-
Number of partitions per table (NOPPT): the number of unique partitions that each table is split up into. It does not take into account any replication.
-
Number of partitions (NOP): the total number of unique partitions in the cluster
-
Active replication factor (ARF): this is the replication that takes into account the
NodeActive=1for node slots in the config.ini. It is less or equal toNoOfReplicas. It should be constant across node groups, but it is not a must.
Now:
-
NOPPT =
PartitionsPerNodex #Nodes -
NOP = NOPPT x #Tables
-
#Nodes = #NodeGroups x
NoOfReplicas
whereby both PartitionsPerNode and NoOfReplicas are defined in the
config.ini file. The usage of NoOfReplicas means that we also take
into account the inactive node slots in the config.ini.
The number of times a partition is replicated is defined by the ARF of the node group the partition is in. When replicated, a partition always has a primary replica and 0-2 backup replicas (depending on ARF). A node will contain both primary and backup replicas of different partitions. The primaries will require more CPU resources.
The following diagram illustrates how partitions are distributed across
node groups, taking into account both NoOfReplicas and ARF (both are 2
in this case). Note that the numbering of partitions is arbitrary and
simply shows that they are unique.
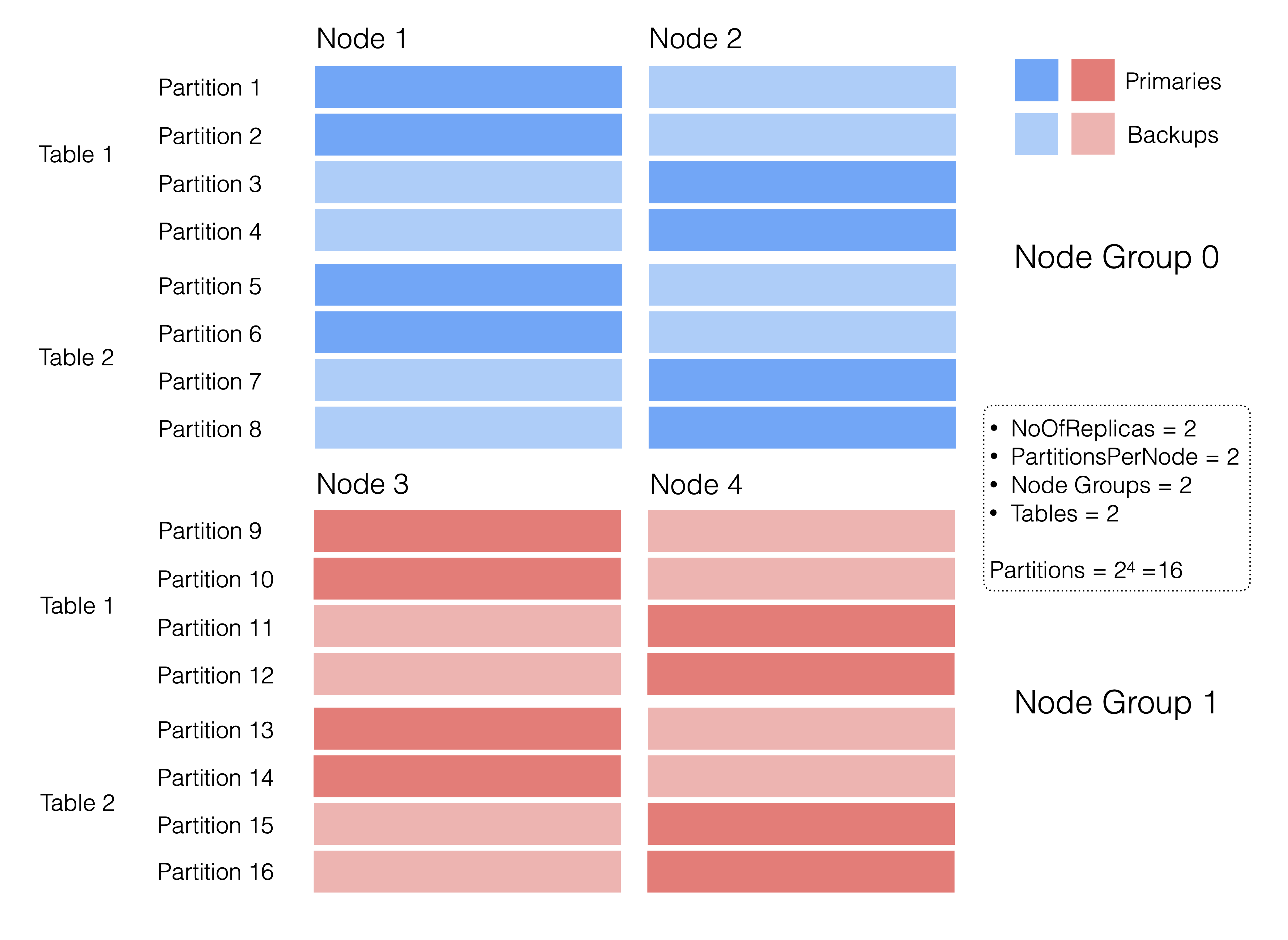
Each table is split up into NOPPT partitions, which equals 8 in this example (2 x 2 x 2). Since we have two tables, we have 16 unique partitions. Furthermore, since our ARF is 2, we have 32 live partitions in total.
Since our node groups do not share any data, #NodeGroups do not affect
how many partitions will be on one node. If we increase #NodeGroups, we
will increase NOP, but the new partitions are all placed onto the nodes
of the new node group. NoOfReplicas on the other hand directly
influences how many partitions will be on one node.
So why is NoOfReplicas a factor of NOPPT? The answer is that it allows
us to always have a balanced amount of primary and backup replicas per
node. Let’s take a single node group, PartitionsPerNode=2 and
NoOfReplicas=3. Let’s further say that:
- NOPPT =
PartitionsPerNodex #NodeGroups = 2 x 1 = 2
whereby NoOfReplicas is ignored. The following table shows what this
would imply:
| Node 1 | Node 2 | Node 3 | |
|---|---|---|---|
| Partition 1 | Primary | Backup | Backup |
| Partition 2 | Backup | Primary | Backup |
As one can see, only nodes 1 and 2 could contain a primary partition. Node 3 would just have backup replicas. This would mean heavy querying of a single table would create a load imbalance in the cluster.
What it looks like instead, is this (NOPPT = 2 x 1 x 3 = 6):
| Node 1 | Node 2 | Node 3 | |
|---|---|---|---|
| Partition 1 | Primary | Backup | Backup |
| Partition 2 | Primary | Backup | Backup |
| Partition 3 | Backup | Primary | Backup |
| Partition 4 | Backup | Primary | Backup |
| Partition 5 | Backup | Backup | Primary |
| Partition 6 | Backup | Backup | Primary |
Here, all nodes have a balanced amount of primary (2) and backup partition replicas (4).