Local checkpoint protocol#
Up until version 7.5 of NDB the local checkpoint protocol used full checkpoints. When NDB was designed originally a machine with 1 GByte of DRAM was a large memory size. Thus handling of checkpoints of a few GBytes wasn’t seen as a problem. As memory sizes started to grow into hundreds of GBytes this started to become an issue.
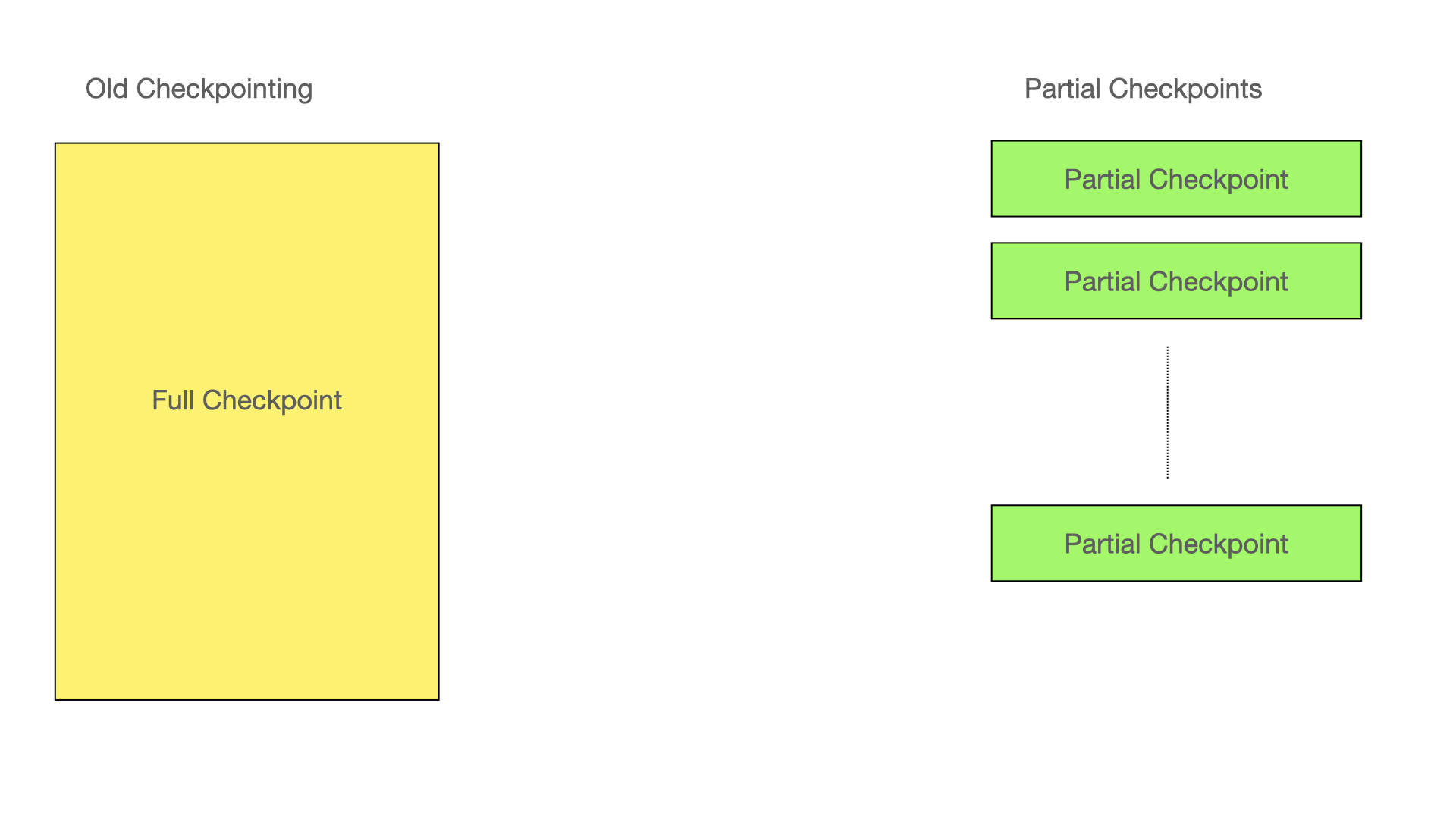
Thus it was deemed absolutely necessary to implement a local checkpoint protocol that was based on partial checkpoints instead. At the same time it was desirable to make the checkpoint speed adapt to the environment it is running in. Also instead of only being able to restore from the start of the checkpoint, the checkpoints are restorable as soon as a checkpoint of a table partition has completed.
One more issue that needed to be handled was that the checkpoints was a distributed protocol where all nodes participates. This is ok when all nodes are in the same situation. But a starting node usually has to checkpoint a lot more data than the live nodes since it hasn’t been participating in a number of checkpoints while it was down.
Thus there was a need to support checkpoints only handled locally during node restarts and most particularly during initial node restarts. These checkpoints enable the starting node to catch up with checkpoints that it wasn’t part of while being down. Normally one such extra checkpoint is enough, but in rare cases multiple ones might be required.
This also ensures that our restarts fail since we run out of UNDO log for the disk data columns.
All these things were implemented in NDB version 7.6 and is thus part of RonDB today.
Considerations for Partial checkpoints#
The requirements of the design was to support DataMemory sizes up to 16 TBytes. Going beyond 16 TBytes will be possible, but will require dividing the checkpoints into even more parts than the maximum of 2048 implemented in RonDB. Increasing the number of parts will lead to larger control files, but in reality is not a major concern.
Thus the implemented algorithms for checkpoints should scale far beyond 16 TBytes as well when this limit becomes an issue.
Another important requirement was to decrease the size of checkpoints on disk. In a full checkpoint it is necessary to always keep 2 versions of the checkpoint. Thus the size on disk is always at least two times more than the size of data.
It is desirable to get this down to around 1.5 times the size of data. If the checkpoints are also compressed, the size can decrease even further.
With full checkpoints the REDO log has to be very large to accomodate the case when the application is loading the database. With partial checkpoints the requirement is to be able to always handle the situation with a fixed size REDO log. We have found that a size of 64 GByte of REDO log can handle more or less any load situations.
We tested with loading 53000 warehouses in TPC-C (5 TByte of data) into RonDB using a REDO log of 64 GByte with very high speed in the loading. This worked like a charm. With full checkpoints this would have required a REDO log of almost 10 TByte since eventually the checkpoints won’t be finishing during the load process since data keeps growing faster than we can checkpoint it.
Thus the requirements of disk space with compression goes to below the data size and without compression it stays below two times the data size.
Even for a DBMS that primarily stores data in-memory it is important to save disk space. Most VMs in the cloud that use NVMe drives have a size of the NVMe drives that is close to the memory size. Block storage in the cloud is fairly expensive, thus it makes a lot of sense to minimise the requirements on required disk space.
Thus although sizes of SSD’s keeps growing and grows faster than the size of memories, most servers keep the same ratio between memory and storage.
Row-based vs Page-based checkpoints#
When implementing a partial checkpoint one alternative is to use a traditional checkpoint using pages and only checkpoint those pages that have changed. This was a clear alternative that would be simple and RonDB already has this type of checkpoint available for the disk columns.
However some math on the impact of page-based checkpoints showed that this approach wasn’t a good idea.
Let’s assume that database rows are 300 bytes each, the data size is 1 TByte and page size is 32 kBytes (this is the standard page size we use in RonDB).
Assume that a checkpoint takes about 10 seconds and that we execute 1 million updates per second. The data fits in 32 million pages, thus most pages will only be updated once. Let’s say we thus update around 8 million pages in 10 seconds.
All these 8 million pages need to be written to disk during a checkpoint. This means that a checkpoint will need to write 256 GByte per checkpoint and thus around 25 GByte per second. There are almost no servers existing that can write even to NVMe drives at this speed.
Assuming that we cut the page size to 8 kBytes we would still arrive at more than 6 GByte of write speed.
Now the same calculation using a Row-based checkpoint shows that we need to write all changed rows, thus 3000 MByte of data. On top of this we also need to checkpoint a small part of the data fully. In this type of test we expect it to use the smallest possible size here which is in 1 out of 2048 parts per checkpoint. This means an additional 500 MByte of data.
Thus we arrive at a total of 3500 Mbyte to checkpoint, thus 350 MByte per second. This is definitely within reach even for a block storage using gp3 (general purpose block storage version 3) in AWS that maxes out at 1000 MByte per second when paying a bit extra. We also need to write the REDO log, but we are still within the limits of this type of block storage.
Thus we have shown that this workload can easily be handled without requiring specialised storage solutions in a cloud environment.
From this calculations one could quickly derive that it was a very good idea to pay the extra cost of the complexity of a row-based partial checkpoint. We showed that the row-based checkpoint is 20x more efficient when using 8 kByte pages and even 80x more efficient in this example when using row-based checkpoints.
Partial checkpoints#
Size vs checkpoint speed of partial checkpoints#
Each partial checkpoint operates on one table partition at a time. The actual checkpoint processing happens in the data owning ldm thread. Thus it is important to ensure that we regulate checkpoint speed based on the current CPU usage of the ldm thread. Thus the higher the CPU usage, the smaller the amount of checkpoint processing.
At the same we cannot stop checkpoint processing, this could create a situation where we run out of REDO log and having to write the checkpoint at very high speed. Thus we need to maintain a balanced checkpoint speed that takes into account amount of REDO log available, amount of CPU resources available and even the current load on the disks used for checkpoint writes.
The checkpoint scan needs to write all rows that have changed since the last checkpoint plus a subset of all rows. The subset of all rows can be 1 part of 2048 parts up to all 2048 parts. The calculation of how many parts to write fully uses a mathematical formula that tries to ensure that the total size of checkpoints are no more than 1.6 times the data size. This number can be adapted through the configuration variable RecoveryWork. It is set to 60 by default meaning that we strive to have 60% overhead on the data size. It can be set to a value between 25 and 100. Obviously decreasing this value means that we save disk space. However it also means that we need to write more parts of all rows and thus it increases the write speed of checkpoint.
Thus it isn’t recommended to adjust parameter very much unless one is very certain that one can allow higher checkpoint speeds or can allow higher use of disk space. The mathematical functions are of the for 1 DIV (1 - x). Thus the increase isn’t linear, it is much faster than this.
One particular time when the disk subsystem is heavily used is during load operations such as when the entire database is reloaded from a backup or from another database. In this case we have a configuration parameter called InsertRecoveryWork that can be set higher to decrease the load on the disk subsystem at the expense of temporarily using more disk space. It is set to 40 by default. It can be set lower as well to decrease disk space usage, this will further increase the load on the disk subsystem.
The writes to the checkpoint files use fairly large buffers and will write normally 256 kByte at a time which is the maximum size of an IO operation in many clouds. The REDO log is normally written with the same size although this requires a fairly high load to be achieved.
Partial checkpoint scans#
A partial checkpoint is basically a diff between what existed in the table partition at the time of the previous checkpoint and its current content. We have to take into account completely new pages, pages that are no longer in use. To ensure that we don’t lose any vital information we retain the page map information also for dropped pages. The page map contains 4 bits of vital information for checkpoints.
The normal case is obviously that the page existed before and that the page still exists. In this case we scan each row id in the page and check whether the row has been changed since the last checkpoint by checking the timestamp on the row. This timestamp is implemented as a GCI (global checkpoint identifier). We know the GCI which was fully incorporated in the previous checkpoint. All rows with a GCI that is higher than this will be recorded in this checkpoint.
To make the scanning more efficient we record change bits in the page header. This ensures that for example a page that hasn’t been touched since the last checkpoint scan will be quickly taken care of. This improves the speed of checkpoints up to a hundredfold.
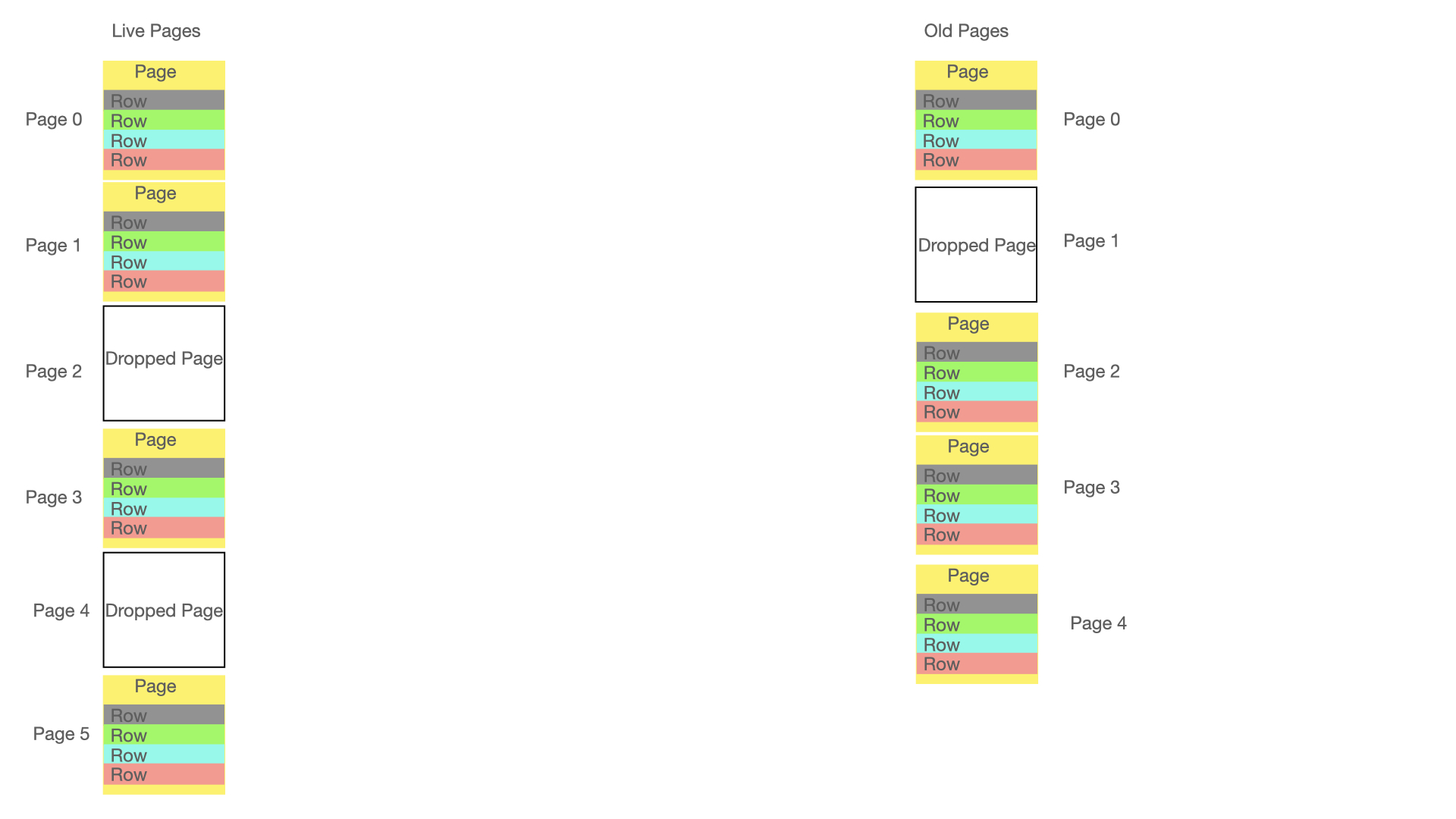
Thus in the figure above we can see that the above method is used when both old and current have existing pages.
In the figure above we are missing a page in the old checkpoint, all the rows in this page must thus be written as part of the current checkpoint.
We have two pages that are missing in the current checkpoint that was present in the old checkpoint. In this case we issue Delete Page instead of a set of Delete Row commands.
The final point here is that we have more pages in this checkpoint than in the previous checkpoint. Again these pages must be fully written in the checkpoint since all rows in those pages are new pages.
There is one thing more to consider. If a transaction writes a row before it has been scanned, then we need to write the row to the checkpoint before the old row data is dropped. This includes setting a bit to ensure that the row is skipped later when the row is scanned.
The reason for this is that a checkpoint is consisting of the rows at a very exact point in time.
Partial checkpoint disk files#
Checkpoint files are stored in the RonDB file system. The RonDB file system can be divided into a number of parts, but checkpoints are always stored in the main RonDB file system as set in FileSystemPath configuration variable. In the top RonDB file system directory there is a directory called LCP. In this directory we have a number of directories called a single number from 0 and up to 2064.
Directory 0 and 1 are used to store the control files for each table partition. These control files are called e.g. T13F3.ctl. This means that the file is a control file for table 13 and partition 3. There can be such file in directory 0 and one in directory 1. There are only two files temporarily, as soon as the new one is fully safe, the old one is removed. There is no mapping from table name to table id in these files and similarly there is no column information in those files. Thus the files are completely binary and require other information to be useful.
The data files are named T13F3.Data. These files are stored in increasing directory numbers. Thus the first checkpoint is stored in directory 0, the next in directory 1 and so forth. As soon as a data file is no longer needed, the file is deleted from the file system. The number of data files can be 0 immediately after the table was created and between 1 and 2048 when the table has been in use for a while.
Starting point of partial checkpoint#
The starting point of a checkpoint is an important point. The data in the database at start of the checkpoint must be retained in a fuzzy manner in the checkpoint on disk. What this means is in this case is that exactly the rows that are present at the start of the checkpoint of a fragment must exist in the fragment checkpoint on disk.
If a row doesn’t exist at the time of the start of the checkpoint it cannot exist in the checkpoint on disk either. The actual row data might be different. After restoring the checkpoint we will execute the REDO log to bring the data content to the global checkpoint that the data node had written before it crashed.
In a system restart this is the data recovered, in a node restart we also need to synchronize the data with a node that is alive with the most up to date version of the data.
Partial checkpoints also write the disk data parts. The references from the main memory row at start of the checkpoint and the reference from the disk row back to the main memory part of the row must be retained in the checkpoint on disk. The disk data reference from main memory row doesn’t change unless the row is deleted. If a row is deleted before it was sent to the checkpoint, the row will be copied and queued up for immediate sending to the checkpoint on disk.
The disk data parts use an UNDO log to ensure that the data pages of the table partition has exactly the rows at start of the LCP. This is accomplished by writing an UNDO log record representing the start of the checkpoint into the UNDO log.
Next each change of the row is UNDO logged. Each time we make an update to a disk data page we will update the page LSN (Log Sequence Number). This ensures that when the page is written to disk we know which UNDO log records need to be applied and which can be ignored.
Write phase#
We perform a full table partition scan such that all rows will be retrieved. We have some special mechanisms to ensure that checkpoint writing has higher priority at very high loads to ensure that checkpoint writing is done at the rate we need it to be. If we have filled our quota for checkpoint writing we will back off from writing until we get more quota to write again. We get a new quota once per 100 milliseconds.
The local checkpoint simply takes the row format as it is and copies it to disk. The operation to write the row is very simple. It must copy the fixed size part of the row first and next the variable sized part of the row.
When the writing of the main memory parts are done we record the maximum global checkpoint identifier that was written during this write phase. The checkpoint is not usable for restore until this global checkpoint is restorable. We cannot remove the checkpoint files from the previous checkpoint of this table partition until we are sure that this global checkpoint is restorable.
Next step is to write the disk data pages that are dirty to disk if such exist in the table partition. To ensure that this writing is not too bursty we start by writing some pages already before the actual checkpoint starts.
The UNDO log will ensure that those pages are transported back to the start of the checkpoint at recovery, we need not care about what is written on those pages while we are checkpointing, the UNDO logger will handle that.
Long-running transactions#
Each operation in the REDO log consists of two parts. The prepare part and the commit part. We will execute the REDO log operation when we find a commit entry. The commit entry will refer to the prepare entry. The prepare entry is written at prepare of the write operation, if a long time goes by after preparing before committing the transaction we will have to keep the change records in memory as well as we cannot cut the REDO log tail beyond the prepare records we have written for prepared transactions. Long-running transactions can lead to that we miss finding prepare entries in the REDO log buffer when executing REDO logs. They can slow down restart execution.
RonDB isn’t intended for long-running transaction applications. A certain amount of long-running transactions can be handled by proper configuration, but it isn’t intended to perform transactions that takes several minutes to complete or that changes more than 10% of the database in one set of transactions running in parallel. Again it is possible to configure it for that, but it will use more memory and disk resources. A better approach is to divide your changes into appropriately sized transactions (can still be fairly large) that executes without awaiting user input.
RonDB 21.04.3 ensures that RonDB will be able to handle transactions with millions of rows involved. Again this is not what RonDB is optimised for and thus even if it will work it isn’t recommended to execute so large transactions.
General thoughts on Partial checkpoints#
The execution of checkpoints is controlled by the master node. The nodes will send a report about completed checkpoints to all data nodes. We retain this information in the DIH block, and use it at recovery to decide which checkpoint to use in restore. In reality the ldm thread have enough information to find this information using the checkpoint files. Thus we are really only interested in knowing which table partitions to restore and which global checkpoint identifier to restore the data to.
A checkpoint only writes down the row content, no information about indexes is written to checkpoints, instead the indexes are rebuilt during restart.
The whole purpose of the checkpoint protocol is to cut the REDO and UNDO log, this happens after completing a partial checkpoint on all table partitions. The actual point in time when this cut is performed is at the start of the next partial checkpoint. At this point we move both the REDO log tail forward as well as the UNDO log tail.