Overview of RonDB APIs#
To read, write and manage data and metadata inside RonDB one has to go through an API. Even when using SQL the query will have to be passed through an API before it reaches the RonDB data nodes.
The most well known interfaces are all the interfaces that one can use to access any MySQL Server. All this interfaces works with RonDB by using tables that use NDB as the storage engine.
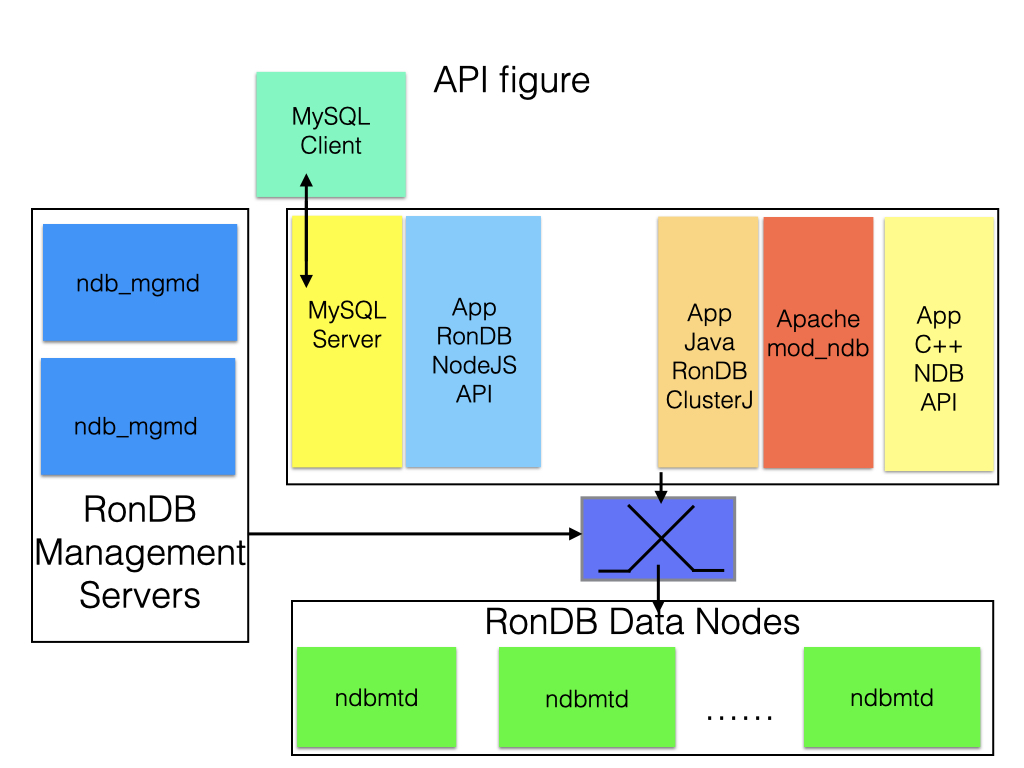
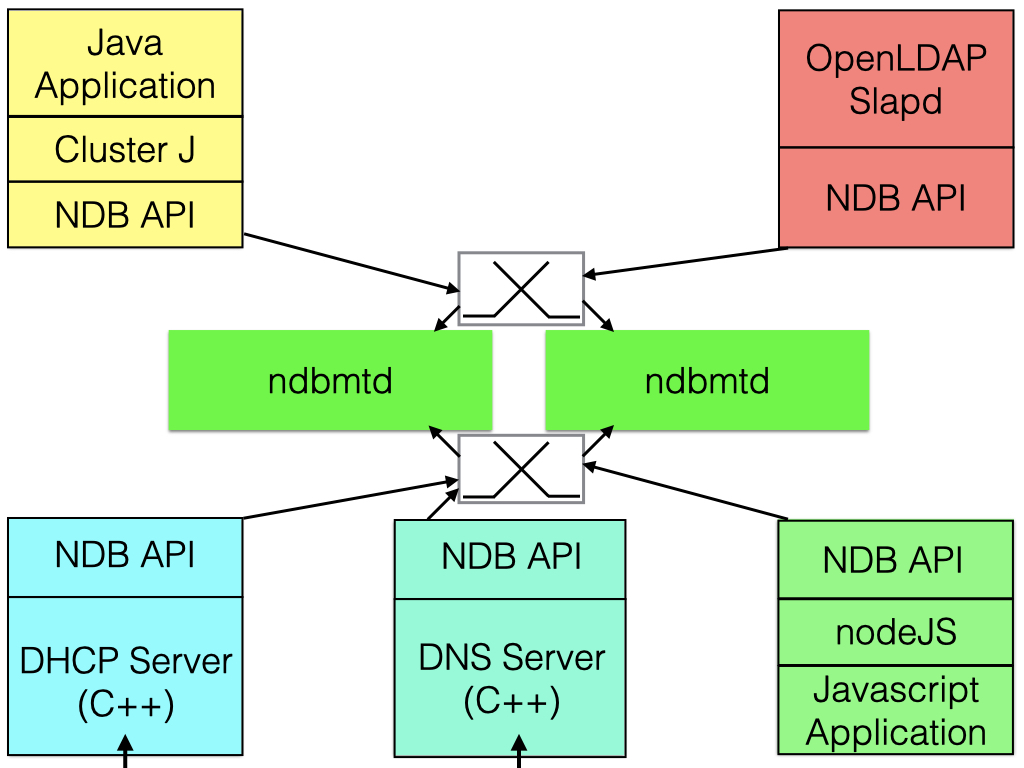
There are a number of native interfaces that we maintain, these interfaces will go directly from the application to the data nodes. This means that we cut away the Query Server functionality and only use the Data Server capabilities. This is especially interesting when building a data service on top of RonDB. Examples we’ve seen when this is appropriate is in building an LDAP server, a file server for Hadoop File Service, a DNS server, a DHCP server and a lot of other functionalities. In this case we’re building a service which is similar to the services a Query Server that can handle SQL does, but it is usually a bit more specialised in its use case. In the figure below we show a few examples of direct applications.
In this case one can use the C++ NDB API, this is the API that all other APIs are eventually going to use. This represents the shortest path to the data in RonDB. The C++ NDB API is fairly complex to use directly, another interface which is quite direct but a lot simpler to program against is ClusterJ. ClusterJ is a Java API, it provides a simple object to relational mapping that makes it easy to work with RonDB. There is also a direct mapping of the C++ NDB API available in Java.
Another interface that can be useful to develop high-performance web services is NodeJS. This interface makes it possible to contact the RonDB data nodes from a JavaScript application.
Programming against a direct NDB API can thus only be done in C++, Java and JavaScript. Most other languages have translation layers that would be possible to map the C++ NDB API to the respective languages. But programming in other languages than these currently requires going through the MySQL APIs.
MySQL APIs#
RonDB is MySQL with NDB as a storage engine plus a lot more. Thus you can access NDB from any MySQL Server that is part of the cluster you are connecting to.
This has the effect that you can access RonDB from any API used to access a MySQL Server. We provide a list of some of those APIs and if there is any specifics about using RonDB from those.
Connector/J#
Connector/J is a very well written Java API towards MySQL. It implements the JDBC interface. Programming in Java means that it is easy to mix using Connector/J for more complex queries and using ClusterJ for simple and more direct queries.
Connector/Net#
Connector/Net provides an API towards the .Net environment. This environment provides access to the CLR (Common Language Runtime) from Microsoft and thus makes it possible to use many different languages available in Windows environments such as C#.
MySQL C API#
The MySQL C API is the API you will use when using the MySQL client and it can be used directly from C and C++. There is also a MySQL C++ API. The C interface to MySQL is used to implement many of the APIs used from other languages.
MySQL API for languages#
There is a MySQL API in PHP which is probably still the most popular API used for MySQL applications. There are APIs available for C++, Python, Go, Java, JavaScript and a few more.
Native NDB APIs#
Native APIs will go directly to the RonDB data nodes without passing the MySQL Server. Thus those interfaces are able to perform better. At the same time it means that one has to program against a lower-level interface. Native APIs don’t exist for all languages, the main direct API is the C++ NDB API which is the base that everyone uses to access the NDB data nodes. Most languages have escape routes such that one can call a function in C. Through these interfaces one can always access the C++ NDB API from all those languages.
As examples in Ruby it is possible to inline C and C++ code and to use something called Rice to access objects written in C++. Scala can access C and C++ code through JNI (Java Native Interface). Go also have a C interface.
ClusterJ: NDB API for Java#
ClusterJ is a bit more than just a wrapper for the C++ NDB API. It does still go through the C++ NDB API on its way toward the RonDB data nodes. But it provides an easy object-relational mapping interface to make it easy to work with.
Here one defines objects that are simply tables in RonDB. These objects can be read from RonDB and written down to RonDB after setting the variables in the object.
A good example of an open-source product using ClusterJ is the HopsFS that implements the metadata server in the Hadoop filesystem (HDFS).
NodeJS: Asynchronous NDB API for Java Scripts#
NodeJS makes it possible to quickly get up and running with MySQL Cluster to develop web applications using JavaScript programs.
OpenLDAP#
The OpenLDAP have a backend that provides access to RonDB. A number of users have started from this backend and developed LDAP servers based on this.