Signal flows in RonDB#
We will go through some of the most important signaling flows to give an idea about what happens when a query is executed against RonDB.
For queries against the database, there are three main flows that we use. The key lookup flow is used to read and write data through primary keys or unique keys. The scan flow is used to perform full table scans, range scans and pruned versions of these. We have a pushdown join that is essentially linked key lookups and scan operations. Pushdown joins are built entirely on top of the key lookup and scan flows.
In addition, there are several protocols implemented in RonDB to handle all sorts of node failures, node restarts, schema changes and so forth. We will go through a few of those and in some cases simply point out where one can find descriptions of these in the source code.
To maintain various secondary data structures we use triggers, which are integrated into the key lookup protocol. We will describe how this happens later on.
Key operations#
RonDB was designed with efficient key lookup transactions in mind. Almost all applications that were analyzed before implementing RonDB had a major portion of key lookups. Most of them had a high percentage of writes as well.
One of the problems with DBMSs in the 90s was that the overhead of transactions was very high. This is still to a great extent true. For example, in other MySQL clustering solutions, there are limitations on how many transactions can commit in parallel.
With RonDB, each row operation is committed in the same fashion whether it is a single-row transaction or if it is a transaction updating 1000 rows. We have worked on streamlining this implementation and there is no limitation on how many transactions can commit in parallel. The only limit is the CPU resources, memory resources, networking resources and disk resources.
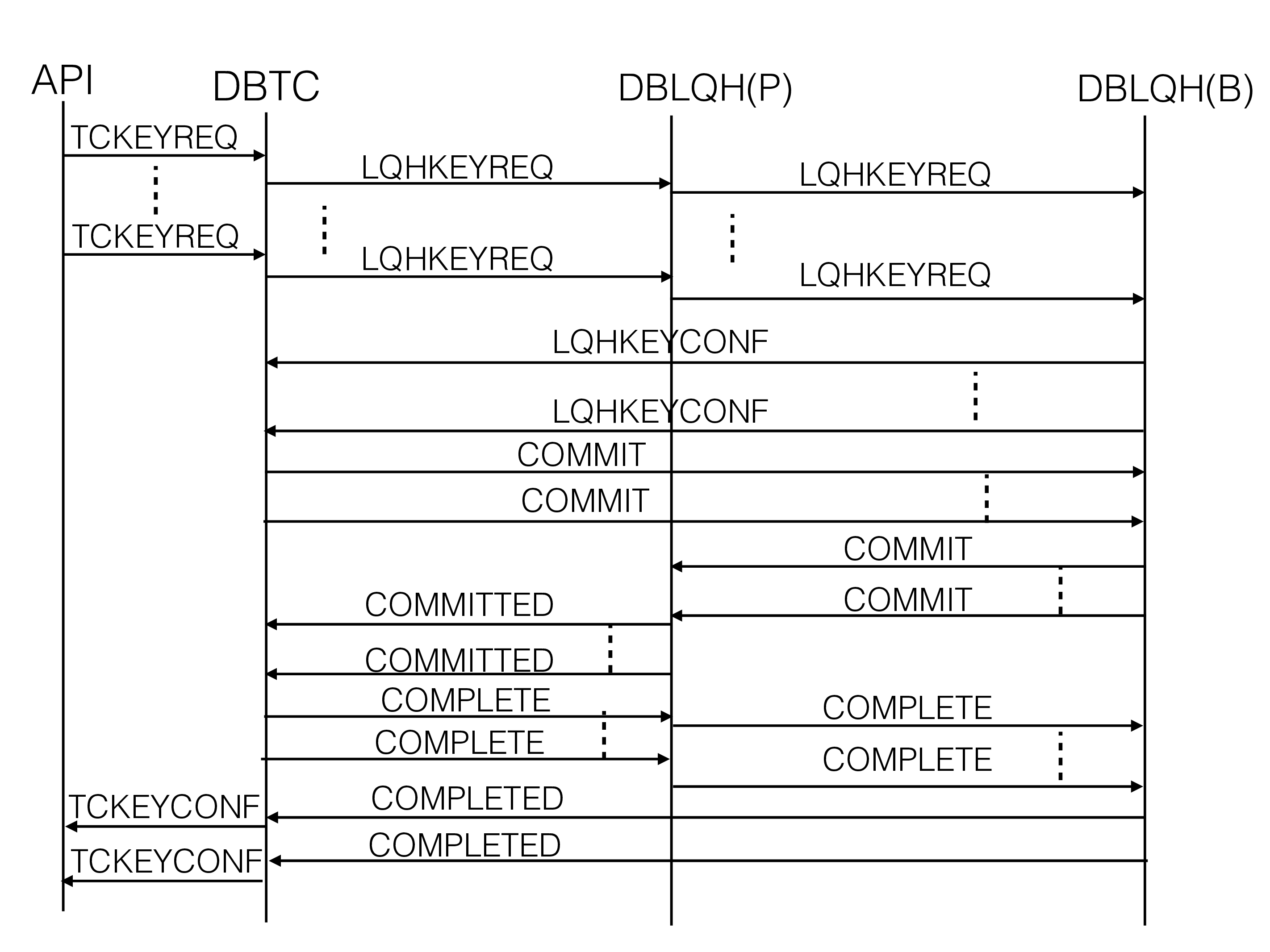
Basic write transaction#
We send one signal from the NDB API for each row to be read, updated, deleted, written or inserted. The same signal is used for all types of key operations.
The figure below shows the signal flow for a single-row transaction.
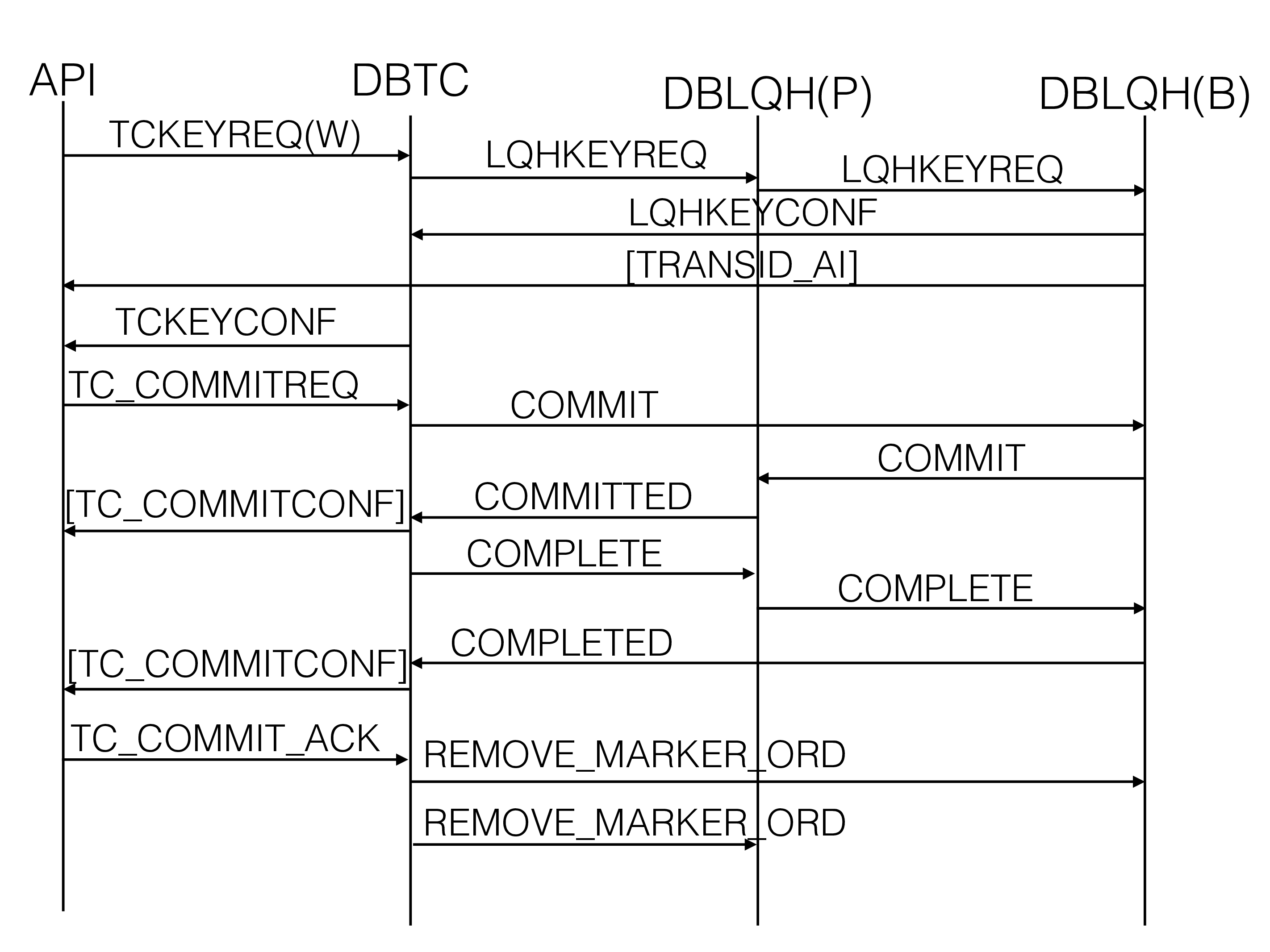
The signal used is called TCKEYREQ and this signal is sent to any tc
thread based on some hinting techniques described in the chapter on the
NDB API.
DBTC uses DBDIH to discover the placement of all the live replicas in
the cluster of the row. Next, it sends LQHKEYREQ to DBLQH in the node
where the primary replica belongs. The signal is sent directly to the
proper ldm thread owning the partition where this primary row resides.
The idea of sending it to the primary replica first is to avoid deadlocks which would easily happen if the writes are sent to replicas in any order.
There is no special signal to start a transaction. The start of a
transaction is indicated by one bit in the TCKEYREQ signal.
There is a commit signal that can be used called TC_COMMITREQ. In the
signal diagram above it is used. It is not necessary to use this signal.
One can also send a TCKEYREQ with the commit bit set. In this case,
the transaction is committed immediately after completing the last
operation and no more TCKEYREQs will be accepted in this transaction
after receiving this bit in a TCKEYREQ signal.
The first LQHKEYREQ contains the list of nodes to update. The primary
uses this to send a signal to the backup replica. It sends a LQHKEYREQ
and the code executed in the backup replica is almost identical to that
executed in the primary replica. Both replicas will update the row in
the prepare phase. The new row will be stored in a copy row, the old row
is kept until the commit point. This means that readers who want to see
the latest committed row state can always proceed and perform the read.
When all replicas have been updated the last replica sends LQHKEYCONF
back to the DBTC that handles the transaction. In this case, the
TCKEYREQ had both a start bit and a commit bit set, thus the
transaction will immediately be committed. We will get the GCI (global
checkpoint identifier) of the transaction from DBDIH and send COMMIT
to the backup replica. Backup replicas will simply record the commit
state and send COMMIT to the next replica in the chain until it
reaches the primary replica.
At the primary replica, it will release the lock and commit the row
change by installing the copied row into the row state and writing the
commit message into the REDO log buffer. After this, any reader will see
the new row state. Next, the primary replica will send COMMITTED to
DBTC.
In RonDB, all tables default to use the Read Backup feature added in MySQL Cluster 7.5. For those tables, the primary replica will not release the locks in the Commit phase. Instead, it will wait to release locks until the Complete phase.
When receiving the COMMITTED signal in DBTC the behavior depends on
whether the table is a read backup table or not. If it isn’t, DBTC
will send an ack to the API using the TCKEYCONF signal. In parallel it
will send the COMPLETE signal to the last backup replica. In the
complete phase, the backup replicas will release the locks and commit
the row changes. It will also release operation records and any other
memory attached to the operation.
The primary replica will send COMPLETD back to DBTC. At this point,
the read backup tables will send TCKEYCONF. After executing the
COMPLETD in DBTC the transaction is committed and we have released all
records belonging to the transaction.
A final part is happening in the background. When receiving TCKEYCONF,
indicating transaction commit, the NDB API will send TC_COMMIT_ACK to
the DBTC. This will generate several REMOVE_MARKER_ORD signals. These
signals clear transaction state that we needed to keep around when for
some reason the NDB API didn’t receive the confirmation of the commit
decision.
Most of these signals are sent as packed signals. This is true for
LQHKEYCONF, COMMIT, COMMITTED, COMPLETE, COMPLETD and
REMOVE_MARKER_ORD. This saves 12 bytes of overhead for each of those
signals in the transporter part. The cost of sending data over TCP/IP
sockets is a large part of the cost of executing distributed
transactions.
Most signals are fairly static, thus the code that reads the signal data knows exactly where to find each item. This makes the code very efficient. The original idea for the NDB protocol was to use a standard telecom protocol using BER encoding. The protocol’s flexibility made it too expensive. Thus we invented a streamlined protocol where all parts of the protocol are 32 bits in size. Now we can process four bytes instead of one byte at a time. This uses the CPU instructions most efficiently.
A special note on key writes is that they can also read data while updating it. For example, it is possible to send a delete operation that reads the record while deleting it. These operations can read either the values before the update or after and it is even possible to send back calculated values.
Basic read transaction#
Reads using a primary key also utilize the TCKEYREQ signal. In this
case, the signal goes to DBTC and from there, it is sent to one of the
DBLQH blocks. For default tables, it will always be sent to the DBLQH of
the primary replica. For read backup and fully replicated tables, it
depends on the type of the read. Read committed can be sent to any
node with a replica. For reads using shared or exclusive locks, it is
sent to the primary replica.
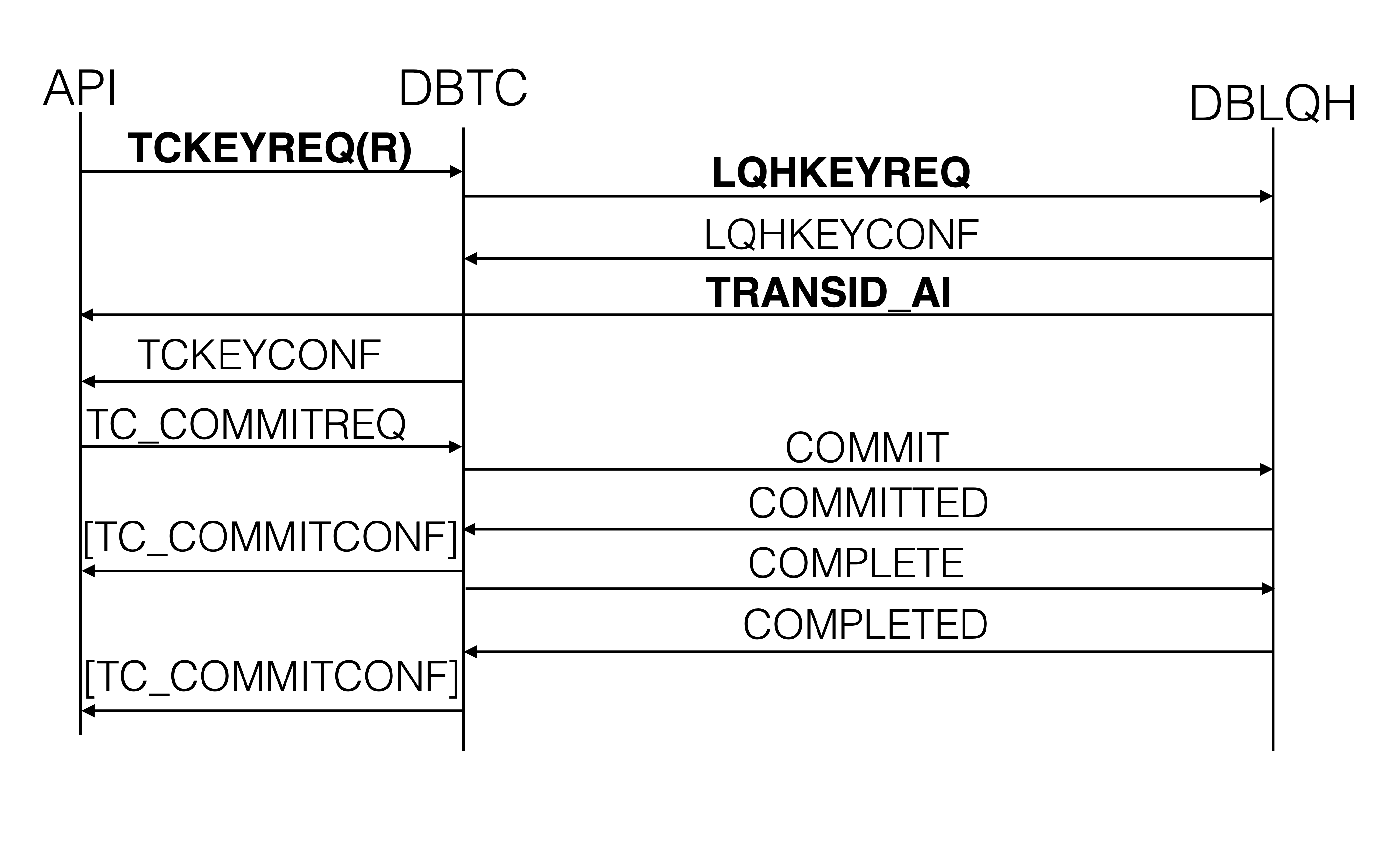
DBLQH sends the data immediately from the ldm thread back to the API
using the signal TRANSID_AI. For read committed there is no other
signal sent to the API.
For reads with shared or exclusive locks, the LQHKEYREQ signal will
cause the row to be locked. In this case, there is also a signal going
back to DBTC called LQHKEYCONF to ensure that the read can be
integrated into write transactions. This signal will lead to a
TCKEYCONF signal sent back to the API. TCKEYCONF is a reference to
one or more TCKEYREQ signals but does not contain any row data. One
transaction can have multiple TCKEYREQs, whereby the last one will
have a flag set, indicating that it is the last. TCKEYCONFs can be
sent back to the API in the middle of a transaction (before other reads
have started).
Updates in fully replicated table#
Fully replicated tables are tables that are replicated across all node
groups. The protocol here is the same as for a normal write transaction.
The difference lies in that a trigger is fired from the primary replica
when updating the row. This trigger sends a signal called
FIRE_TRIG_REQ to DBTC.
The trigger contains several LQHKEYREQ signals - one LQHKEYREQ
signal per extra node group. The initial LQHKEYREQ is always sent to
the first node group to avoid deadlocks. If the initial LQHKEYREQ
contains an executable program (e.g. increment), the first primary DBLQH
can execute this on behalf of the other primary DBLQHs. Thereby, the
trigger will only contain the information to change in the rows.
The updates in the base fragment and the replicated fragments will then proceed in parallel and commits of each such replicated fragments will happen as if they were independent writes. But since they are part of a transaction, the changes will be atomic. Either all or none of them happen. This is ensured by using a single transaction coordinator for all fragments.
In a single node group cluster, the only difference for fully replicated
tables is that the FIRE_TRIG_REQ signal is sent to DBTC.
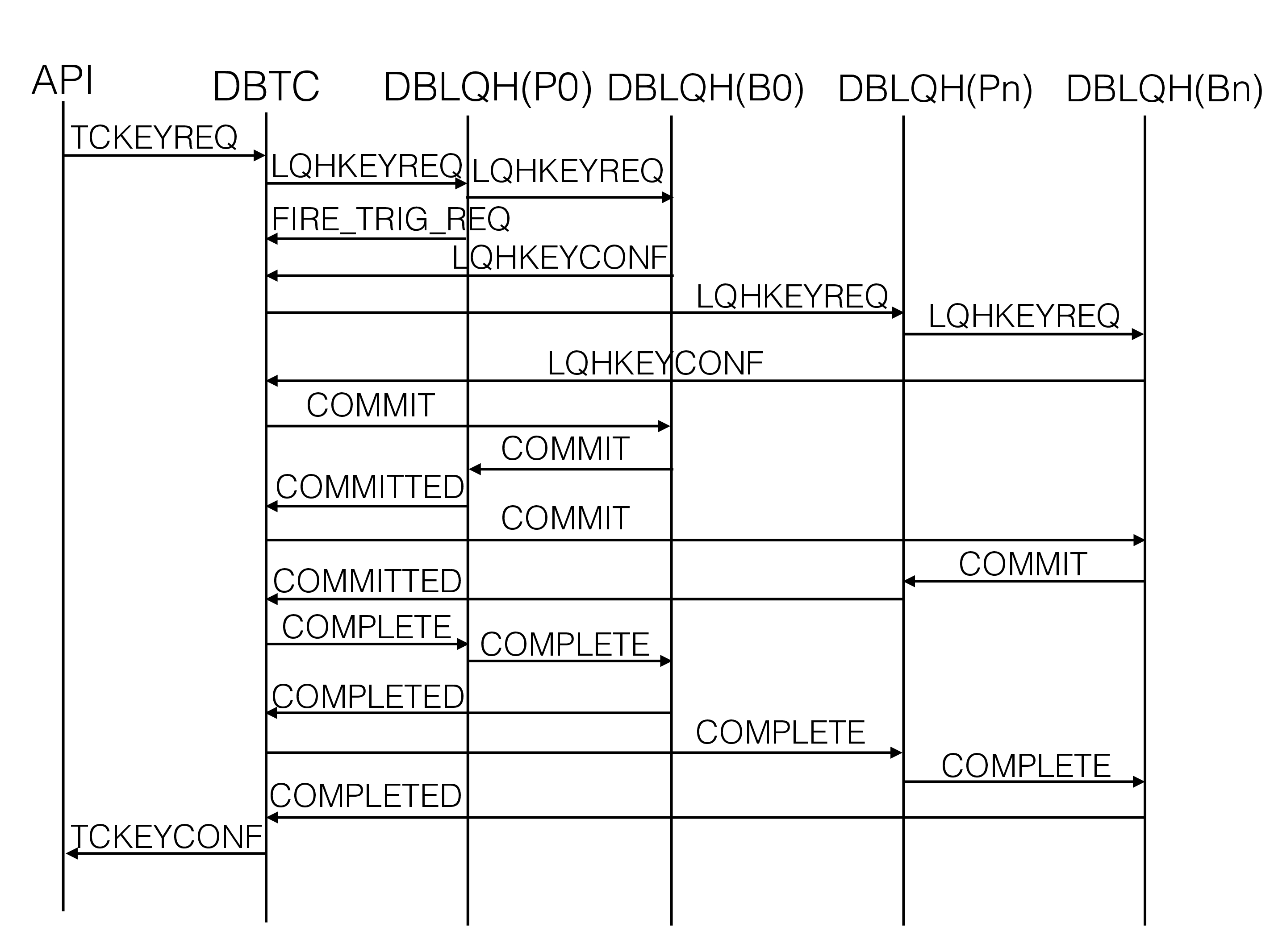
Note: Technically, the FIRE_TRIG_REQ signal is sent from DBTUP to
DBTC. Both the DBTUP and the DBLQH blocks are part of ldm thread, they
work together closely.
Unique index read operations#
Unique indexes are hidden tables in RonDB’s "backend" that take care
of the UNIQUE constraint in the schema of normal tables.
The unique index tables use the unique index as a primary key and then
store the primary key of the main table as a column.
In RonDB, each table is partitioned into its own fragments. The fragment that a row is placed in is decided by the hash of its partition key. In the case of the unique index table, the primary key is also the partition key. Since however each table is partitioned separately, the row in the unique index table can be on a different node than the row in the main table. Partitioning is further explained here.
Unique indexes can both be read and updated. Reading from the main table using a unique index requires a read from the unique index table to get the primary key of the main table. The signaling of this is shown in the figure below.
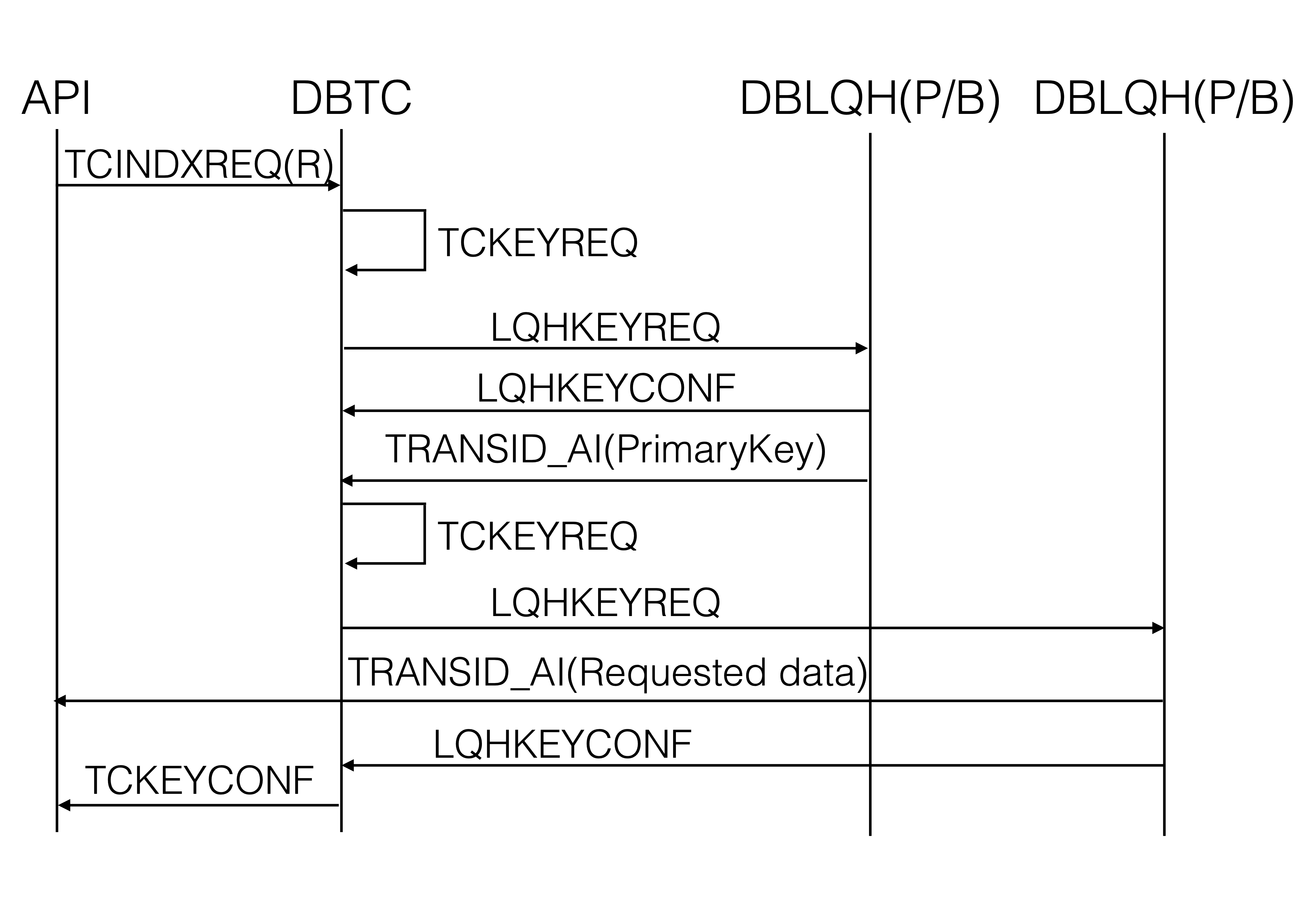
The DBTC sends a TCKEYREQ signal to itself to trigger a read operation
using a shared lock that returns the primary key of the main table. This
key is then used to start up a normal TCKEYREQ to read/write the row.
The reason why the read of the unique index table uses a shared lock and why this can cause deadlocks is described in the section on locking unique indexes.
Updating a unique index#
To update the unique index of a row, we require a lock on the row in the
main table. The update towards the main row, using the LQHKEYREQ
signal, will then trigger the FIRE_TRIG_REQ signal, similar to the
fully replicated table case. In this case, the trigger’s FIRE_TRIG_REQ
signal will however only contain one LQHKEYREQ to update the fragment
where the unique key resides.
A special case is a unique index in a fully replicated table. Here, the
trigger will contain LQHKEYREQs for each extra node group, like in an
update in a fully replicated table.
Building new partitions#
When executing the SQL statement ALTER TABLE t1 REORGANIZE PARTITIONS
we will reorganize the table to use the new nodes in the cluster.
While building the new partitions we will have triggers that ensure that operations on the table partitions that are reorganized will be sent to the new table fragments. These fragments are normally present in new nodes in the cluster.
This follows the same type of protocol as for fully replicated tables. In this case, only rows that are moved to the new table fragments will execute those triggers.
Asynchronous operations#
Asynchronous operations in the NDB API are not the standard method to use. But it is a very efficient method that at times has shown to outperform other methods by as much as 10x.
In contrast to the standard NDB API, the asynchronous NDB API lets
the client send multiple transactions in a single function
call. The results of these transactions can then be polled in a separate
function pollNdb(). The advantage of this, as opposed to
executing one blocking transaction per thread, is that:
The transactions can be bundled into fewer TCP/IP packets
We avoid the overhead of creating and destroying threads
The figure below shows the signal flow for an asynchronous operation:
In principle, the protocol is the same as before, but now everything is heavily parallelized. By sending 200 update transactions in a batch instead of 1-2 updates at a time, we can gain up to 10x higher throughput. Note that also spinning up 200 threads to execute 200 transactions in parallel would not be a good alternative due to the threading overhead.
Currently, only key operations are supported asynchronously.
Table scan operations#
The most basic scan operation is a full table scan. This will be run on row-id order or disk order in DBTUP. The latter is however currently disabled.
A range scan is a scan operation that places a range on an ordered index. A range filter on a column that is not an ordered index is not a range scan and will instead cause a full table scan. Range scans are by far the most common scan operations.
A partition pruned scan is a scan operation where an equals filter is on the partition key. This will cause the scan to only scan one partition. Any other scan will scan all partitions of the table. Therefore, this scan is the most efficient. This also makes it very important to choose the partition key carefully.
The second class of query operations that RonDB handles are scans of a table.
Basic scan operation#
All scan operations use the same base protocol. It starts by sending
SCAN_TABREQ from the API to the chosen DBTC. DBTC discovers where the
partitions of the table reside. Next, it sends SCAN_FRAGREQ in
parallel to all table partitions. An exception is for pruned scans that
only scan one partition. It is possible to limit the amount of
parallelism using a parameter in the SCAN_TABREQ signal.
SCAN_FRAGREQs are sent in parallel to a set of DBLQHs that house the
partitions. DBLQH has a local scan protocol to gather the data using
DBACC, DBTUP, and DBTUX blocks. This protocol is local to one thread in
the data node.
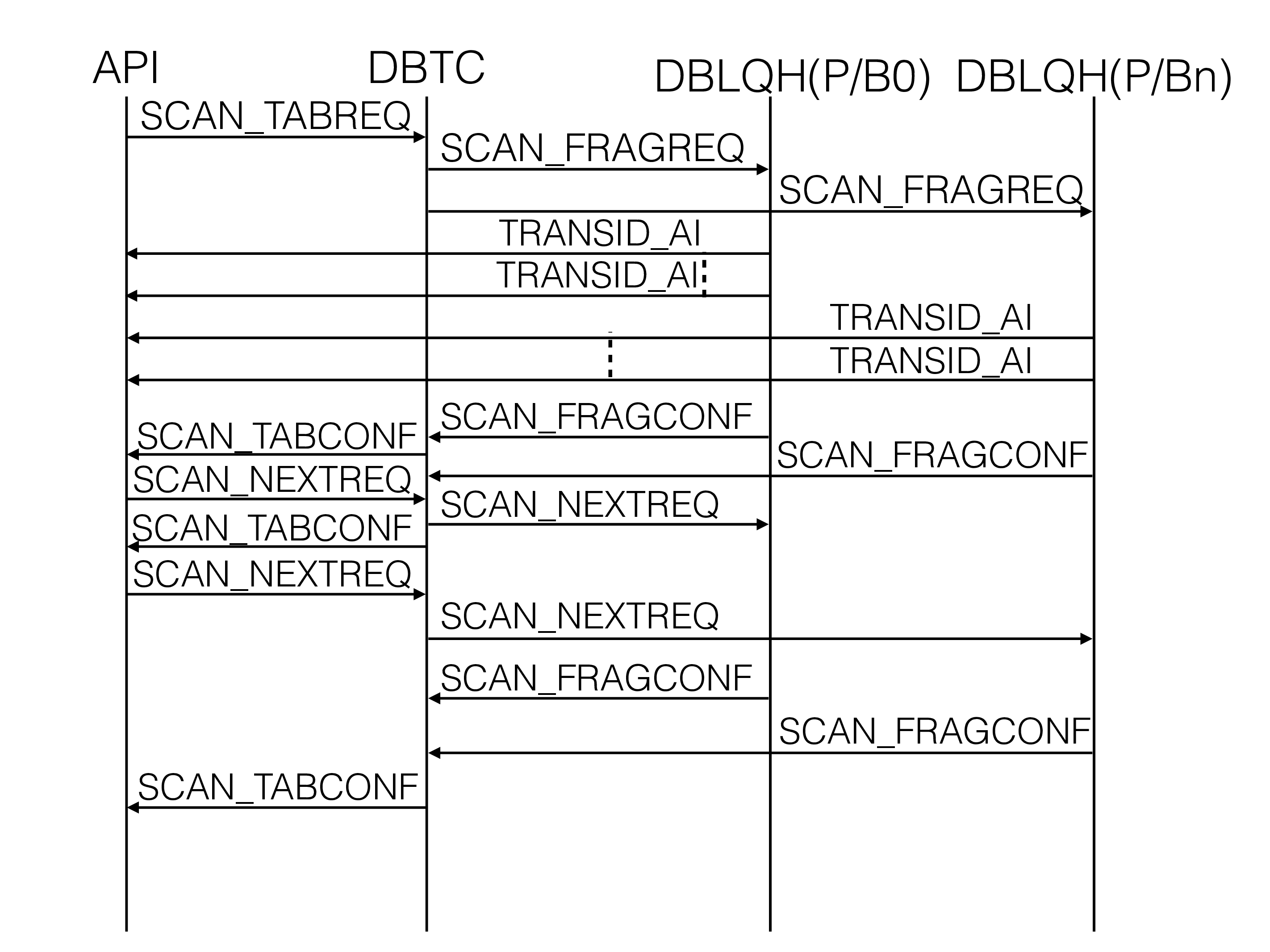
Each signal execution of SCAN_FRAGREQ in DBLQH will scan up to 16 rows
at a time and then return these rows via the TRANSID_AI signal. It
then sends a signal to itself to scan the next 16 rows in a new
execution. Execution times range from about 2-3 microseconds to over
20-30 microseconds. Thus, even if a scan goes through 1 million rows, it
will not cause real-time issues for other scans or key lookup
operations. Such a scan will be divided up into hundreds of thousands of
signal executions automatically. Thus, even in this case, millions of
operations can execute on the same data in parallel with the scan
operation.
DBTC serializes communication with the API. The communication between
DBTC and the NDB API has one talker at a time. When one of the DBLQH
blocks sends back SCAN_FRAGCONF to DBTC, two things can happen. If the
NDB API is still waiting for input from DBTC one sends a SCAN_TABCONF
signal back to the API immediately. If we have sent SCAN_TABCONF and
are waiting for the SCAN_NEXTREQ signal to proceed we will queue the
scan results in DBTC. When SCAN_NEXTREQ arrives we will immediately
send a new SCAN_TABCONF to the API if any results were queued up. At
the same time, we will send SCAN_NEXTREQ to the DBLQH blocks that
already reported ack to the API.
SCAN_TABCONF will normally report back rows read from multiple DBLQHs
at a time. How many are completely dependent on the current system load.
SCAN_TABREQ carries two signal parts. One part is the interpreted
program to execute on each row scanned. The second is an index bound
(only used by range scans).
The interpreted program carries out filtering and will report back
whether the row read was sent back to the API or if it was skipped. The
actual row data is sent directly from the ldm thread to the API using
the TRANSID_AI signal.
The API can always send SCAN_NEXTREQ with a close flag if it decides
that it has seen enough. This will start a close protocol of all the
outstanding fragment scans.
Similarly, DBTC can close a scan in DBLQH by sending a SCAN_NEXTREQ
signal with the close flag set.
Pushdown joins#
Pushdown joins are implemented on top of the key lookup protocol and scan protocol. They use a linked join algorithm where keys for the tables down in the join are sent to the DBSPJ block for use with later scans and key lookups. Columns that are read are immediately sent to the NDB API for storage in memory there waiting for the rest of the queried parts that are fetched further down in the join processing.
Foreign Keys#
Foreign keys have two parts. The first part is the consistency checks that the foreign key defines. The checks are executed in a special prepare-to-commit phase executed when starting to commit. If this phase is successful the transaction will be committed, otherwise it will be aborted.
The second part is the cascading actions. These are executed exactly as the other triggering operations. One special thing to consider about foreign keys is however that triggers can fire recursively. One small change is capable of triggering very massive changes. This is not desirable, it is important to consider this when defining your foreign key relations.
Table Reorganisation#
In the block DBDIH in the file DbdihMain.cpp, there is a section called Transaction Handling module. This describes exactly how the global data in DBDIH used for query processing is maintained. In particular, it describes how table reorganizations are executed in RonDB. It contains a description of the signal flows for this algorithm.
Metadata operations#
Metadata operations start with a phase where the metadata transaction is
defined by using signals such as CREATE_TABLE_REQ, DROP_TABLE_REQ,
ALTER_TABLE_REQ, CREATE_FILE_REQ and so forth. These signals are
spread to all data nodes and are processed by the DBDICT block.
After defining the metadata transaction, there are a great many steps for each of those metadata parts where there are several different phases to step forward, there is also a set of steps defined to step backward when the schema change doesn’t work.
These steps are implemented by a signal SCHEMA_TRANS_IMPL_REQ and its
response SCHEMA_TRANS_IMPL_CONF. All the nodes step forward in
lockstep until all phases have been completed. If something goes wrong
in a specific phase, there is a well-defined set of phases defined to
abort the schema transaction. Aborting a metadata operation is a lot
more complex than a normal transaction.
Cluster Manager operations#
The node registration protocol and the heartbeat protocol following it are described in some detail in the Qmgr block in the QmgrMain.cpp file in the RonDB source code. It contains signal flows for this algorithm.
Local checkpoint protocol#
The local checkpoint protocol consists of several protocols. The first
step is a protocol using signals TC_GETOPSIZEREQ/_CONF,
TC_CLOPSIZEREQ/_CONF. These are used to decide when to start a new
LCP based on the amount of changes in the data nodes.
We have to acquire a schema lock also for a short time to decide on which nodes to integrate into the LCP. Only the tables defined at the start of the LCP will be checkpointed. New tables created after starting a local checkpoint will have to wait until the next local checkpoint.
One important part of the LCP protocol added in 7.4 is the pause LCP
protocol. This ensures that we can pause the LCP execution when a node
is starting up to copy the metadata in the cluster. There is a long
description of this protocol and the LCP protocol itself in the block
DBDIH, in the source code file DbdihMain.cpp. This protocol aims to
ensure that DBLQH stops sending LCP_FRAG_REP signals that will change
the state of distribution information in DBDIH. This protocol is only
required during the restart of a node.
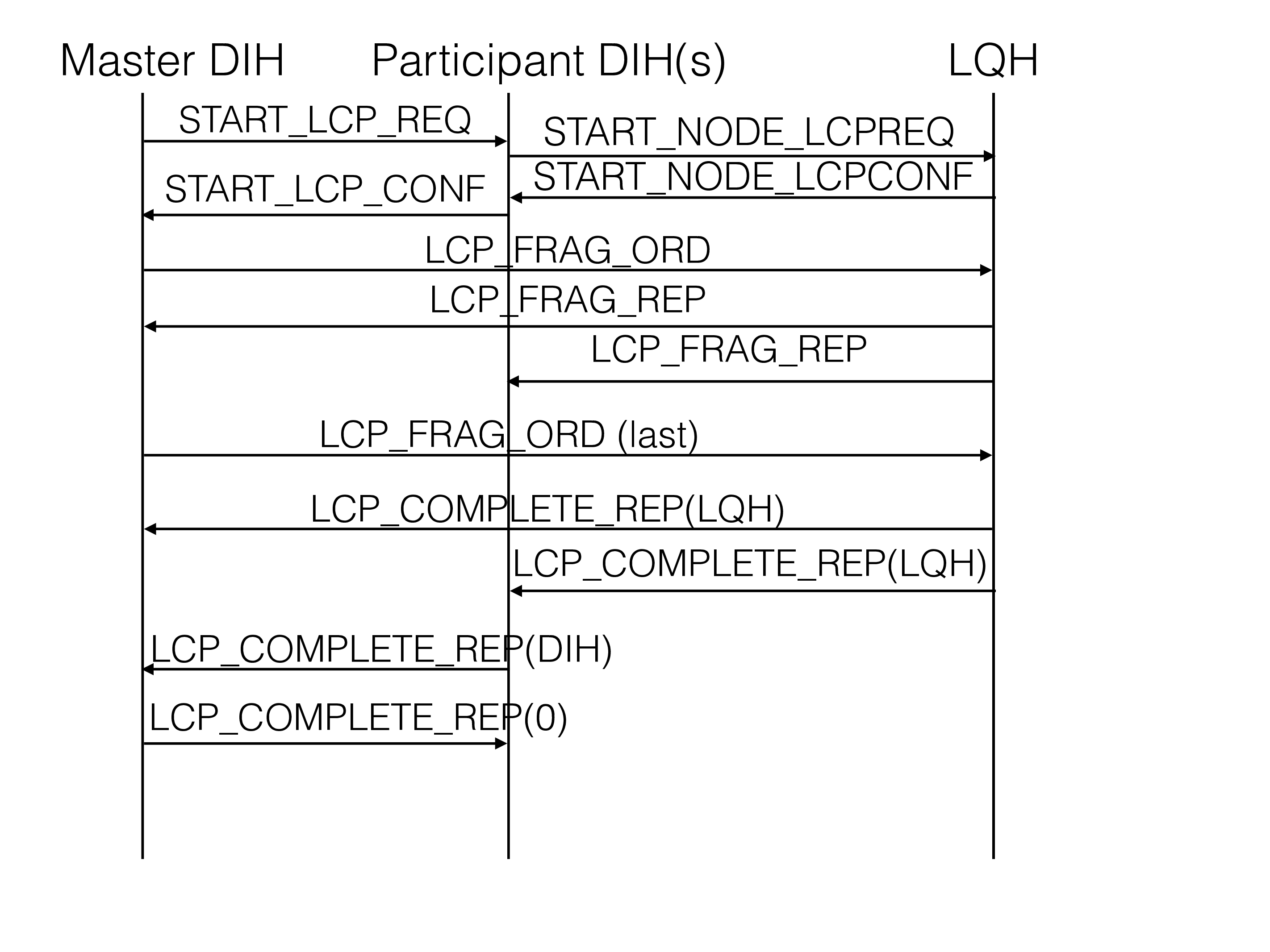
The above figure shows the execution phase protocol of a local
checkpoint. It starts by sending START_LCP_REQ to all nodes. Before
sending this signal we acquired a mutex on the distribution information
in DBDIH. This signal aims to set the flags on what table fragments that
will perform this local checkpoint. Since we have locked the
distribution information all nodes will calculate this locally. After
completing this preparatory step of a local checkpoint each node will
respond to the DBDIH block in the master node with the START_LCP_CONF
signal.
After receiving this signal from all nodes we have finished the preparation of the local checkpoint. We can now release the mutex.
The next step is to start sending the signal LCP_FRAG_ORD to DBLQH.
Each such signal asks DBLQH to checkpoint a specific table fragment.
Many such signals can be outstanding at a time, they are queued up if
DBLQH isn’t ready to execute them. DBDIH will send lots of those signals
to give DBLQH the chance to control the speed of executing the local
checkpoint.
Whenever DBLQH finishes the execution of a local checkpoint for a table
fragment it will send the signal LCP_FRAG_REP to report about the
completed checkpoint. This signal is sent to all DBDIHs (one per node).
When the master DBDIH has completed sending all LCP_FRAG_ORD to all
nodes, it will send a final LCP_FRAG_ORD with the last fragment flag
set to true. This indicates to all DBLQHs that no more checkpoint
requests will be sent. Thus when DBLQH finishes executing the last
checkpoint in the queue and this signal has been received, it knows that
its part of the local checkpoint execution is completed.
After the local checkpoint execution in a DBLQH, it will send the signal
LCP_COMPLETE_REP to all DBDIH blocks. This signal will first go to the
DBLQH proxy block, only when all local DBLQH instances have sent this
signal will the proxy block send this to the local DBDIH block, which in
turn will broadcast it to all DBDIH blocks. This signal will be marked
by DBLQH completing its part of the local checkpoint execution.
When a DBDIH block has heard this signal from all nodes and it has
completed saving the changes to the distribution information from local
checkpoint executions, it will send LCP_COMPLETE_REP to the master
DBDIH block. This signal will be marked that DBDIH has completed its
part of the local checkpoint execution.
When the master has received this signal from all DBDIH blocks, it will
send LCP_COMPLETE_REP to all DBDIH blocks with a 0 indicating that now
the entire local checkpoint execution is completed in all nodes.