Use cases for RonDB#
One very important use case for RonDB is obviously as part of the data infrastructure of Hopsworks. RonDB is the backend database used to store metadata in HopsFS in a scalable manner. HopsFS is a distributed file system that can be used to store many petabytes of data used in various machine learning applications.
On top of HopsFS runs Hudi, Hudi implements complex query logic that makes it possible to do massive data analysis.
RonDB is an integral part of the Feature Store in Hopsworks, Hopsworks is the management framework to manage AI applications developed by the company Hopsworks AB. The feature store has two parts, the offline feature store that can be used to train machine learning models. This runs on top of Hudi which runs on top of HopsFS that uses RonDB heavily.
The second part is the online Feature Store which is implemented directly on top of RonDB to achieve the lowest latency, the highest availability and very high throughput and scalable storage size.
The Hopsworks Feature Store is documented at https://docs.hopsworks.ai/latest.
Thus future development of RonDB is targeted to make it an integral part of the modern AI applications where it can be used to assist in both training AI models and to assist in online analysis for things such as Fraud Analysis, automated driving and many more AI applications.
In this chapter we will also discuss the traditional use cases for RonDB in HA applications.
You might wonder how many people are using RonDB and NDB Cluster which RonDB is based on. In reality billions of people on the earth is using NDB indirectly. You might be using NDB when doing any of of the following: placing a phone call (HLR), starting your computer (DHCP), opening up a web page (DNS, Web Server, ..), logging into an on-line computer game, playing an on-line computer game, placing a stock order, watching some video service, paying for a service on the internet, shopping in a store, placing a bet in an online betting service, handling documents on the internet, reading online news, anything related to phone call services.
The list of things that could invoke usage of NDB is long. In this chapter we will describe a few of the use cases and what characteristics of NDB that makes developers select it as their data management solution.
NDB was originally developed at Ericsson for telecom database requirements, these requirements included Class 5 availability, high update rates and low latency operations in a distributed system.
Class 5 availability means that it is available 99.999% of the time, available means that both reads and writes are possible. This means no more than 5 minutes downtime per year. To reach this requirement the database must be both readable and writeable during all normal management actions. This includes during software upgrade, computer upgrades, application upgrades, and most common schema changes.
The only downtime allowed is when the entire cluster fails. To reach the highest availability one needs to combine RonDB in two data centers with Global Replication between the data centers. Using this setup it is possible to reach Class 6 availability (less than 30 seconds downtime per year) and higher.
In the IT world a system that can reach Class 4 availability (no more than 50 minutes downtime per year) is considered a high availability system. Most cloud vendors doesn’t promise more than 99.95% availability even when using replication in several availability zones (thus an application in the cloud will have to live with up to 260 minutes of downtime per year for the cloud itself).
Given that most applications would define their system as an HA application (HA = high availability) already when reaching Class 4 availability (almost an hour downtime per year), I use a new term for RonDB, the term is AlwaysOn, this is the most important unique selling point of RonDB. Thus to be an AlwaysOn system requires reaching Class 6 availability. This can only be reached by combining very high availability inside one cluster combined with replication to other regions of the world.
Quite a few database management systems can handle millions of reads per second. There are very few systems that can reach millions of writes per second. NDB has demonstrated 205 million reads per second and around 20 million writes per second. This benchmarks was performed almost five years ago.
RonDB can perform distributed transactions involving hundreds of rows being read and written in a few millisecond and a single simple transaction can complete in much less than 100 microseconds.
Finally some words on use cases where RonDB normally would not fit. If your application doesn’t require high availability and simply requires low latency and high throughput and the database fits in one machine. In this case it is difficult for RonDB to compete since a database that runs everything in memory with no context switches is difficult to beat with an architecture designed for a distributed system.
Even in such scenarios RonDB have decent performance and latency. We have worked hard in every version to minimise the latency and maximise the throughput while at the same time allowing the architecture to scale towards extreme transaction rates.
RonDB is mainly intended for OLTP applications that does a bit of analytical queries. The performance of complex queries depends a bit on how well the query integrates with the RonDB architecture.
As soon as some sort of replication comes into play RonDB have a large advantage with its efficient replication solution. Traditionally NDB have been a perfect fit for use cases with high update rates. With the introduction of the possibility to read any replica in RonDB is a much better fit for use cases with high read rates.
The feature introduced in RonDB to have tables that are replicated in all data nodes in the cluster means that you can build cluster scenarios where we use RonDB for read scaling of one data set with up to 48 machines that can handle tens of millions of SQL queries for one data set of sizes up to many terabytes.
Networking applications#
Networking applications was the first category where NDB found market success. The first user that put NDB into production was the company Bredbandsbolaget in Sweden. They used (and still do as far as I know) NDB for a networking application to support their Internet access service. NDB was used as the data layer in a DNS and DHCP infrastructure. Interestingly I used this service myself personally for about 10 years. The service is still operational and have used NDB from version 3.4 and up.
Networking infrastructure requires a number of services to map names to numbers, lease addresses and various authorization and authentication services.
All of those are fairly mild in their requirements on throughput and scalability, but they have tough requirements on availability and predictable response times. It is a natural fit for RonDB.
DNS Server#
We start by showing the simplest possible application which is a DNS Server. The DNS server performs translation from web addresses to IP numbers. As an example one might come in with www.dn.se and get back 169.123.124.55 (not any real IP address). Thus the web server (or some more local DNS server) does a DNS lookup to the DNS server. This arrives at the DNS Server that looks it up using some kind of database query (most likely a simple primary key lookup in this case) using the web address as key and retrieving one or more IP addresses. The DNS server will then package a response package to the requester.
In the figure we have only shown the DNS Server computers and the data nodes. Most likely there are computers handling management queries, a computer handling one or more RonDB management servers. There could be more than 2 DNS server computers, and there could be more than 2 data nodes. There could be other applications running in the same cluster to handle other service types.
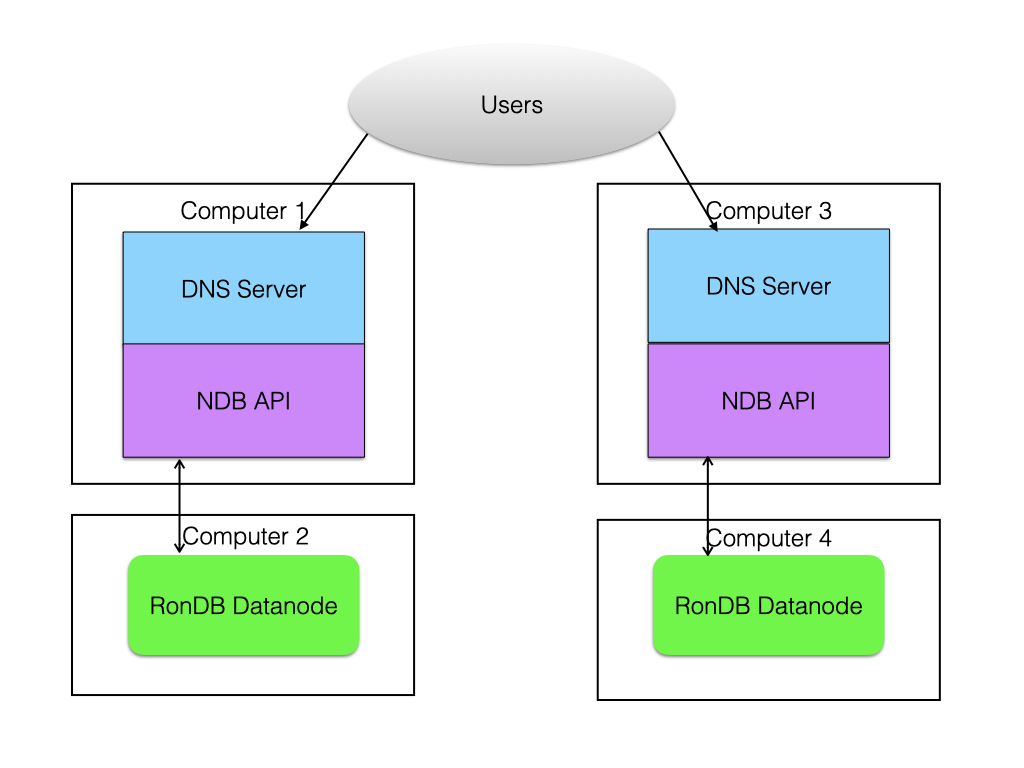
A DNS server is a fit for NDB and was actually one of the first applications where NDB was brought into production usage. The benefit that RonDB provides is the high availability story. A DNS server that is down will be quickly noted by the customers of the ISP. DNS Servers higher up in the DNS caching chain will have even more impact. It is essential that DNS servers are developed with high availability in mind.
The DNS server application is mostly about reading the data. This means that we could make use of the feature to fully replicate the data and thus have the DNS server scale to 48 data nodes and in this case it makes sense to colocate the DNS servers and the data nodes such that the DNS server only reads from its local data node.
In the figure we have shown a case where the DNS server and the data nodes are placed on separate machines. This is probably easier to manage since one can upgrade the DNS server more independently of the RonDB data nodes, MySQL Servers and RonDB management servers.
DHCP Server#
The figure above for how to handle a DNS server using RonDB works for a a DHCP server as well. A DHCP server handles short term leases of IPv4 addresses. A computer that starts up (or a router even more likely) will send a request for a lease of an IPv4 address. The DHCP server will look for a free IP address and return an IP address that the requester can use.
One major difference is that this application will make updates to its data on most requests. This makes it even more important to handle high availability. A DNS server could possibly get away with a short read-only mode. But for a DHCP server a read-only mode or server being down is the same thing since a DHCP server needs to write data as part of most user requests.
A DHCP server is a good example of an application that can use RonDB and was part of the first use cases in production for NDB.
An open source DHCP Server called Kea have tested and verified all sorts of failure scenarios with multiple DHCP servers working together in a cluster using NDB. To find descriptions of these and documentation on how to set it up for use with Kea simply google with key words NDB+Kea.
RADIUS server#
Another common service used in both IT environments as well as telecom environments is AAA servers (Triple A). This stands for Authentication, Authorization and Accounting.
RADIUS is a protocol that implements the requests for AAA services.
A RADIUS server uses a database in most cases to provide its services and it is important that this database is highly available since otherwise it is not possible to authenticate and authorize the users.
Thus it is a similar service to DNS server and DHCP server where there is both a read part and an update part and the service need to be AlwaysOn.
An example of a product in this category using NDB is the Juniper product SBR Carrier. It makes use of all the benefits of NDB by providing a set of applications that directly access the data through the NDB API, they have LDAP access using an LDAP server, storing data in NDB accessed through the NDB API, they can also access data through SQL and the MySQL Servers.
Telecom servers#
DNS and DHCP servers are good examples coming from the IT world. There are many examples coming from the telecom world as well. Most of the original requirements on NDB came from this application category. Thus there is an obvious fit for many telecom applications.
The decision process to bring in a new product into a telecom network is a bit longer than in the networking area, but the market success for NDB in the telecom sector have been excellent and in a number of categories NDB is the market leader.
The name NDB originally came from Network DataBase. Network databases started appearing as separate telecom nodes in the 1980s beginning with the introduction of 800-numbers in the US. 800-numbers was numbers where the receiver of the call always paid for the call. These numbers were popular for companies since they made it easy to get in touch with its customers for all sorts of reasons.
When 800-numbers was introduced there was a need to make an intelligent translation of this 800-number to a real phone number. It was possible to use time of day, originator of the call and many other aspects to calculate the number.
What happened was that the telecom operator had to handle a large database with number translation information. The first network databases were written as applications bundled with the data. This meant that the application was harder to manage than necessary. Thus it was desirable to put the data into a real database and thus make it possible to manage its data using standard interfaces such as SQL queries.
Traditional databases didn’t qualify for this task since availability requirements was higher than what could be provided by the traditional DBMS vendors.
This led to the development of a new category of DBMSs that all originated from telecom vendors and from telecom operators. NDB was one of those DBMSs developed, but there were many other competing implementations, in Ericsson alone there were a number of competing solutions.
The combination of the characteristics of NDB and the characteristics of MySQL and the market success of MySQL made NDB the market winner in this application category.
Thus many other applications can ride on the benefits of this development in the telecom industry to develop many other applications. The first benefactor was the IT sector that got a number of network applications that made good use of the high availability features of NDB.
There are many different types of network databases using NDB in use today in all sorts of telecom networks using many thousands of servers.
The newest development in the telecom industry that happened in the first years of the new millenium is that the telecom vendors realised that it was time to ensure that many of those telecom applications should use a common database.
The availability requirements on this common database is even higher than the individual applications. This was a good fit for NDB. It was an early market success for NDB.
The variety of applications and how they are implemented in the telecom network is simply to great to put into one picture. There are examples using only SQL for the entire application, there are examples using the NDB API for most of traffic use cases and SQL for management use cases and there are use cases involving Java APIs and LDAP APIs.
I will provide a few example applications from the telecom sector. A few examples can also be found at the MySQL home page, such as the Myriad use case of NDB.
Number Portability Demo#
The origin of NDB is an Ericsson project that started in 1997 (thoughts on NDB started already in 1991). The original aim of this project was to develop a prototype of Number Portability for a telecom vendor.
At the time most phones were still fixed phones and the numbers were connected to the telecom switches. The first few numbers in the telephone number assisted in deciding where to connect the call. This prevented telephone users from keeping the same telephone number when they moved to a new region of their country. In a similar fashion to mobile phones there was a need to develop a more flexible numbering scheme. The idea here was to use a database to translate from the users telephone number to the physical telephone number, the physical telephone number still pointed out which switches to use in the connection setup.
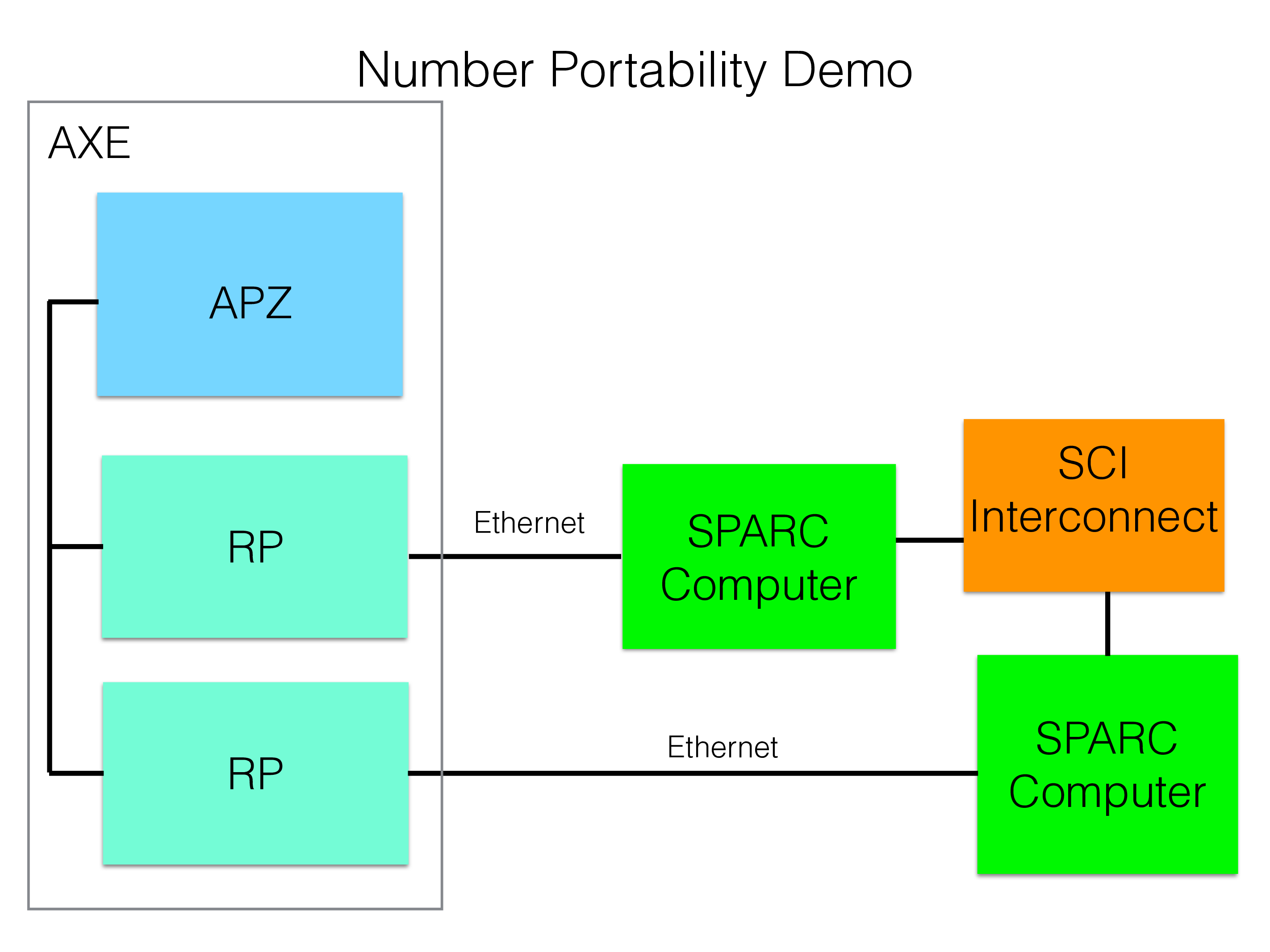
NDB was developed to provide this number translation through a database table. By making this database table external to the telecom switch and by providing a database interface the management of the number portability application became much easier compared to executing proprietary commands towards the telecom switches.
The prototype was built using the telecom switch from Ericsson called AXE. The AXE had a central processor called APZ and many assisting regional processors (RPs). Some of those regional processors had the ability to connect via Ethernet and TCP/IP.
The first prototype of NDB connected two regional processors in AXE to two SPARC machines that contained the database as seen in the figure above. As part of a call setup a message was sent from the APZ to one of the RPs connecting to a SPARC server over Ethernet. Next the message was sent over Ethernet to the SPARC and there an application program accessed one of the database servers over SCI using an early version of the NDB API. Finally the message was delivered back to the APZ in the same fashion to enable the use of portable telephone numbers.
Updates of the data in this application was done only when people moved, so it was a management procedure that happened outside of the telecom switch. There was a lot of work done in the 1990s to standardize management of telecom switches and the introduction of network databases was one such trend that is nowadays a standard part of any telecom network.
The project as such was a success and we managed to prove that one could access an external DBMS within 4 milliseconds as part of setting up a connection. The success of NDB came later since there was intense competition at this time at Ericssson in this area. Another popular open source database Mnesia (part of Erlang) also originated from Ericsson in those days and also two other internal database projects within Ericsson.
Availability and response time were the two main requirements on the database product used in those cases. To provide response time we used Dolphin SCI cards to connect the nodes in the cluster. At this time the TCP/IP interface was only a debugging interface used in development whereas the Dolphin SCI cards provided the communication between ths SPARC servers in this Number Portability Demo.
The software architecture of NDB internally borrowed a lot of ideas from the AXE and this is a major reason why we have been able to build a DBMS that can handle hundreds of millions of reads per second.
Juniper SBR Carrier Database#
Juniper offers a solution for various needs in telecom networks. The product has extensive documentation freely available.
This product implements among other things a RADIUS server, a DIAMETER server, access directly from MySQL Server using SQL, an HLR and many other telco services. NDB serves all these applications with a highly available data service with many different APIs.
This is another important application category for NDB. It is used as a high availability session store. This was a first use of NDB in web applications.
The large variety of ways to access to NDB was an important reason for developing NDB. The management of telecom networks are using a flurry of standard interfaces. The ability to combine access using standard interfaces such as SQL and LDAP combined with low level APIs that can be used for traffic parts of the application is an important combination that solves a real problem in telecom networks.
The management applications are often costly to develop and requires the use of standard interfaces to make it easy to use various 3rd party tools as part of the application development.
At the same time the traffic applications have stringent needs on predictable latency, high throughput and very high availability. Here the use of a low level API can be used to squeeze out a lot more performance from small servers.
This combination was an integral part of the thoughts that led to the development of NDB.
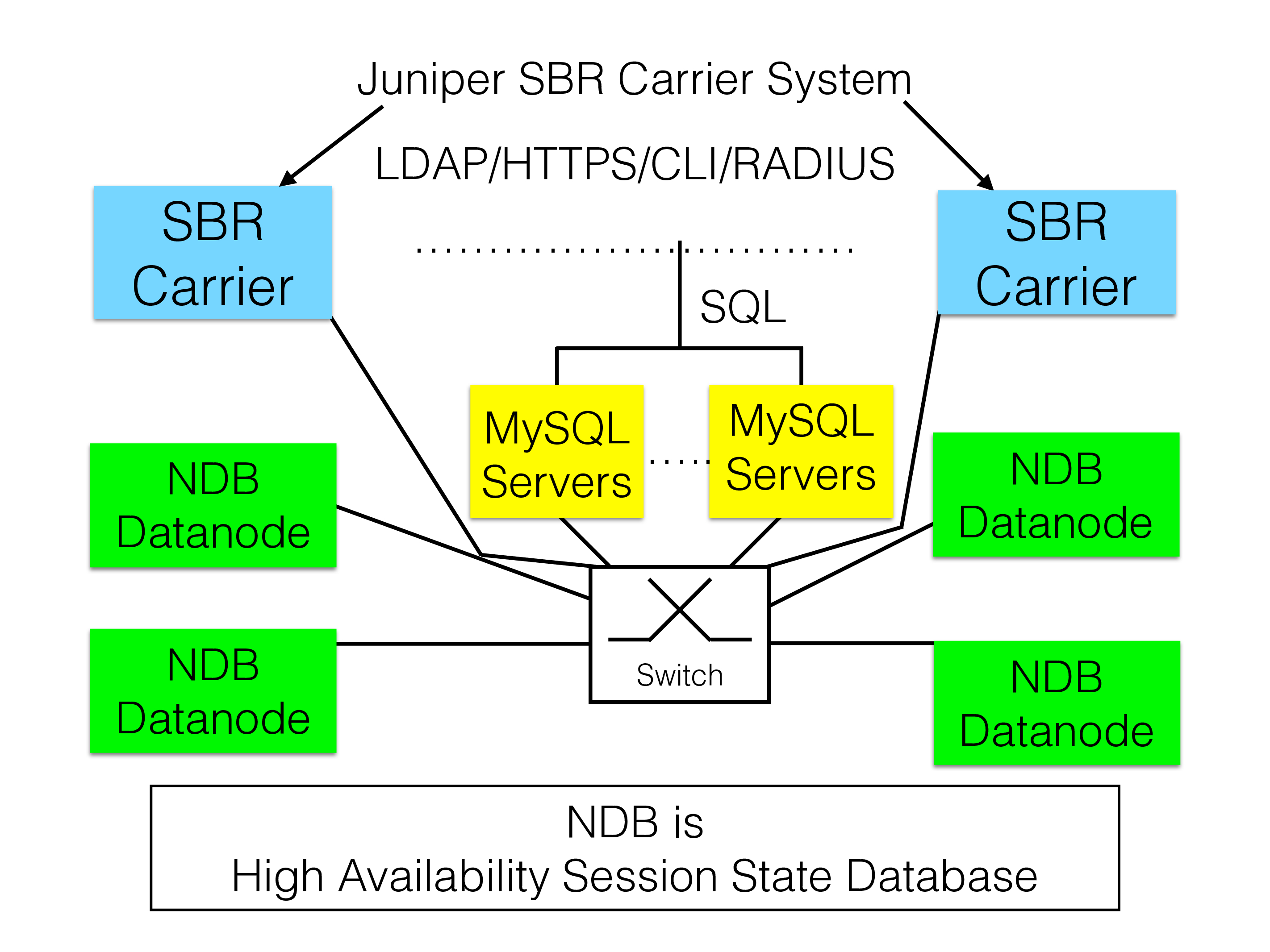
The database can here be accessed using various means, through an LDAP interface, there is the traditional MySQL interface that carries SQL, there is application programs that uses NDB API to implement the RADIUS server parts, the DIAMETER server and the HLR parts and many other parts.
This service is an integral part of a telecom network that provides authentication and authorization of users entering a private network.
It is implemented in hundreds of networks world-wide at places like airports in large parts of the world.
Most applications of NDB have an international presence since it is possible to have high availability of the cluster combined with geographical replication to other sites as well.
Universal Database#
This is a product that has different names from different vendors. It makes it possible to store data about users and their services in a stand-alone system that all other systems can use (HLR, AAA, Number Translation) and so forth. It is a system that has the absolutely highest availability requirements and NDB is a fit for these systems and is heavily used in this category by major telco vendors such as Alcatel (nowadays Nokia).
HLR#
An HLR (Home Location Register) is used in a call setup to find out where a mobile is currently located. Thus each time the mobile is changing location area the HLR needs to update the location information of the mobile. The HLR also keeps track of various telecom services of the mobile subscription.
This is a important and key part of the mobile telecom network and requires the outmost availability. Many operators implement their own services using NDB such as Italtel.
Video services#
A more recent example in the telecom industry is using NDB for various video on demand (VoD) services.
Other telco services#
Here is a list of a few other telecom services that benefits from using RonDB.
-
Service Delivery Applications
-
Mobile Content Apps
-
Online mobile portals
-
Payment Gateways
-
Software Defined Networking (SDN)
-
Network Function Virtualization (NFV)
-
Voice over IP applications
Gaming systems#
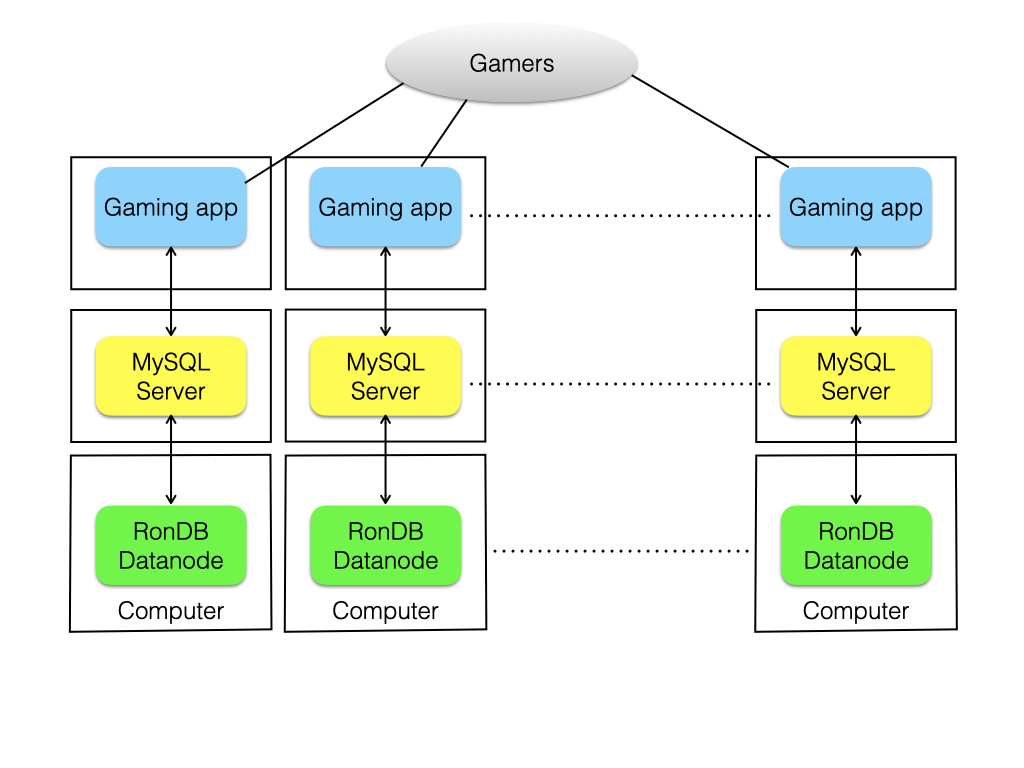
One category of applications that have found a fit with NDB is gaming applications. I often used this example to describe my work for my kids when they were small since they played a lot of the games that was supported in various ways by NDB.
The developers of gaming applications differ quite a lot from the telecom developers. Telecom developers are used to developing applications at a low level and they are used to long development cycles with extensive testing. This means that they are often more willing to commit to developing on a lower level where they can get gains of up to 10x better performance by doing more development work.
The gaming industry requires more online development and much faster reaction to the needs of the gamers. Thus this category of developers often use more hardware and larger clusters than the telecom sectors. They are much more inclined to use the MySQL Servers as front-ends to the NDB data nodes rather than an NDB API application or the Java API towards NDB.
The figure above shows the three levels of servers involved in the gaming applications. First we have the gaming apps themselves, second we have a set of MySQL Servers and lastly we have a set of NDB data nodes.
The application parts that makes use of NDB differs wildly. One example could be to handle the gamer profiles when the gamer logs into the application. Another use case could be maintaining various statistics about the game and another use case could keep the real-time status of the ongoing games in the database.
Gaming applications make a lot of updates as part of all those parts of the applications. There is a great variety of complex read queries originating from this type of applications. Thus our pushdown of join queries into the data nodes is an important feature for this type of applications.
A gaming company will receive lots of bad marketing if the gaming applications are not working properly due to some type of outage. In this application the high availability is a key differentiator to make use of RonDB, but also its write scalability as well as its ability to run many parallel complex queries on the data.
RonDB makes it easy to scale the application since the application layer, the MySQL Server layer and the data node layer can be scaled independently of each other.
Gaming applications is one of the most demanding applications on the scalability of RonDB. A case study of how BigFish, a gaming company, uses NDB is available on the MySQL web site.
Financial applications#
Financial applications was the first focus areas for NDB around the years 2000-2002. We actually delivered a working solution to a customer in this area using version 1.1 of NDB. The focus at the time was mostly on being able to handle the throughput requirements of the combination of a busy stock feed and the many queries in real-time to find out what stocks are available for buying. To meet those requirements was hard at the time.
The IT crash delayed our entry into this area considerably. The applications in this category have requirements that make NDB a very good fit in some cases.
The figure below shows how this application can make use also of the ClusterJ interface. The ClusterJ is an interface that uses Java and object-mapping to work with RonDB. This makes it easy to develop applications using this interface that have very good performance.
It is possible of course to replace ClusterJ by JDBC and a MySQL server if it is desirable to use SQL for queries.
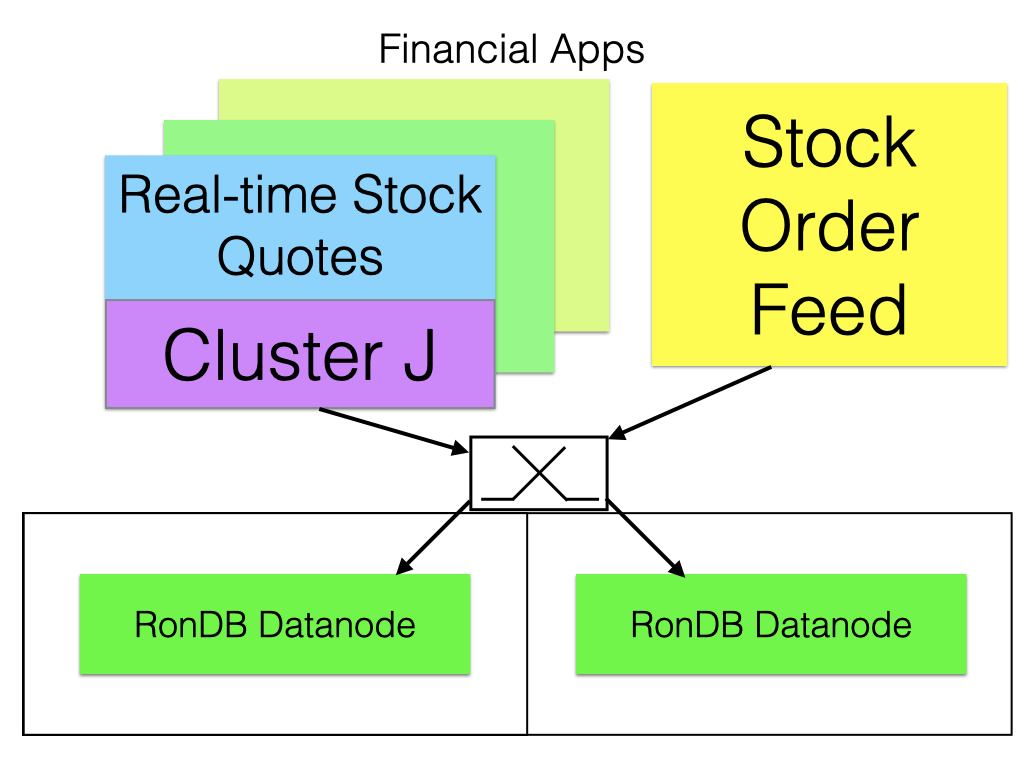
There are many potential use cases around payment services. One could use RonDB for whitelists and blacklists, one could use RonDB to handle various micro payment services. This is an important area also for Hopsworks using the Online Feature Store.
In this category many applications are developed using Java and ClusterJ, our Java NDB API, that gives direct access to cluster data is an important part of use cases in this category.
Trading application#
In a trading application as shown above, there is a stream of updates coming from each new stock order. These updates have to be applied at a high speed with low delay. At the same time it is important to deliver reads of this data as well with predictable response time.
This application requires high availability during the time the stock exchange is open, but when the stock exchange shuts down the system can be stopped. NDB have been shown to handle a million transactions per second while at the same providing room for other types of analytical queries as well in use cases like this one.
The reason to choose RonDB for this application is its ability to deliver predictable response time. We had a user some years ago that used all real-time options of RonDB and real-time options on the applications side. They were able to perform 100% of the read operations returning in a few hundred microseconds or less. RonDB can handle millions of transactions per second which is a requirement in a busy stock exchange that could have large peak loads.
Payment services#
There are many parts of a payment service where RonDB can be used in an efficient manner. Examples are handling micro payments and fraud detection. Any payment services of eCommerce on the internet is required to have high availability since a payment service being down leads to lost revenue quickly.
At MySQL Connect 2012 PayPal gave a keynote presentation about their reasons for choosing NDB for a global fraud detection service. This application category has quite a few use cases for RonDB.
Online banking services#
A current trend in banking is to provide online banking services without having any physical offices of the bank to visit. Many such banking services rely on a high availability data store and we have a number of examples of such users using NDB.
Fraud Detection#
A white paper on MySQLs home page shows how Anura.io use NDB for fraud detection.
Web applications#
MySQL has been traditionally used for all sorts of web applications. This hasn’t been an area where NDB had a lot of impact in the past. Our initial success in this category was where NDB was used as a session database for e-commerce applications and in various other parts of the e-commerce applications.
Interestingly the first prototype application in this category was developed already in 1999, it was a web cache server based on an old implementation of the NDB API in Java. This development was important since it brought NDB into the presence of Ericsson Business Innovation where NDB matured from an innovation into a product ready for market launch.
With RonDB, it is easy to setup a set of computers that all acts as primaries where you can read all data locally. This is a good fit for many web applications where MySQL is traditionally used with MySQL replication. The benefits of using NDB in those cases comes from the ease in setting up replication and that data changes are synchronous so there is never any need to worry about replication lags, there will never be any lag.
In the past most people that tried to use NDB with Wordpress had performance issues since most of the complex queries had to go over the network. Now by using a setup with full replication combined with colocating each data node with a MySQL Server means that all reads will be local and will not require to use the network. At the same time any update is immediately seen by all MySQL Servers at once. With this setup in RonDB it should be possible to get good scalability.
The benefits of using RonDB here is that all MySQL Servers see the updates immediately, it is easy to continue scaling the cluster by simply adding more data nodes and MySQL Servers. One could easily start with e.g. 3 replicas of the data and continue in steps of 3 servers at the time to grow the number of servers up to 48 servers. No downtime is needed during this scaling process, only a number of rolling restarts where the cluster is still fully operational and with 3 replicas it will be replicated during the rolling restarts (e.g. by restarting 1/3 of the servers at a time).
Examples of web applications that would benefit from using RonDB:
-
eCommerce Applications
-
Session Databases
-
Enterprise Application Servers
-
User Profile Management
-
Highly available Web sites
-
Online Gaming State
-
Virtual Reality Worlds
Soft real-time applications#
The development of various control applications requires a real-time database with very high availability. RonDB have a good fit thus for controlling trains, cars and many other vehicles. Predictable response time with very high availability of the service is again a key factor in choosing RonDB here.
This is a new category of applications that is still in its infancy and will continue to develop over the coming years.
Oracle OpenStack#
OpenStack is a framework developed by a large number of corporations to develop applications for various cloud environments, both private and public.
Part of the OpenStack framework is a database that contains various configuration data and other information. The various components of OpenStack all make use of this database.
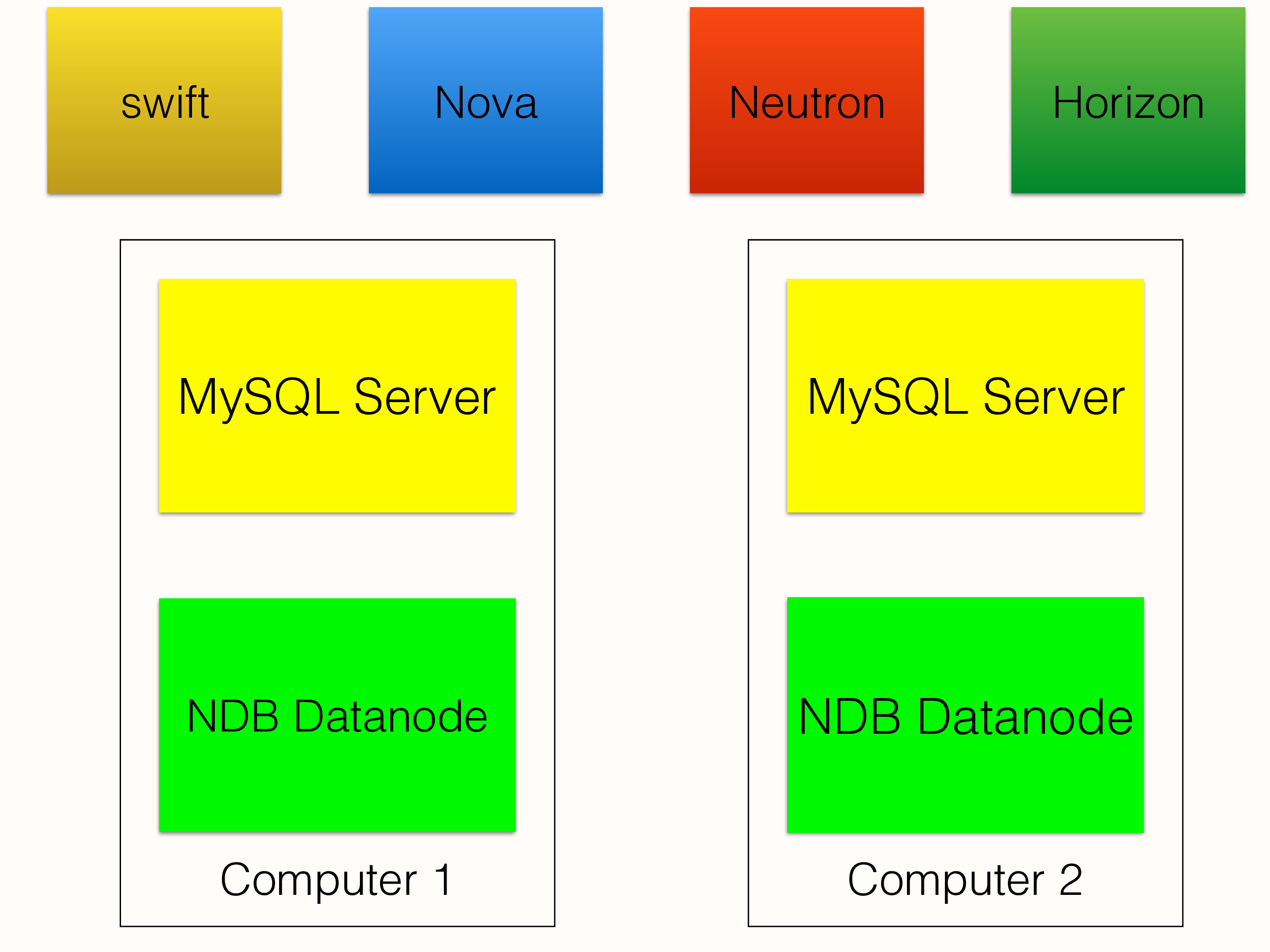
In the Oracle solution for OpenStack there is a high availability configuration where NDB is used for this database. The reason for NDB is the simplicity in setting up a highly available environment where all MySQL servers can be used for both updating and reading. There is no need to specifically handle primary and backup roles of the MySQL Server since the data in NDB is updated using transactions and thus all MySQL Servers acts as primaries.
The same database can also be used for application data of the OpenStack installation.
GE#
General Electric presented a number of templates for how GE applications should setup data services as part of the keynote session on MySQL Central, a recent MySQL Conference held in conjunction with Oracle Open World 2015. They all included using NDB. They used synchronous replication inside each cluster, but they also used replication between the clusters and made use of multi-primary support for MySQL replication using NDB.
In the selection of DBMS to use the following requirements was placed on the DBMS:
-
Available across regions
-
Scalable Data Store
-
Class 5 availability (less than 5 minutes downtime per year)
-
Quick deployment and ease of use
-
Performance and Productivity
-
Time to market and cost
Many different solutions was tested ranging from SQL databases, NoSQL databases, MySQL with replication and NDB. NDB was selected among other things for its solutions for redundancy, ACID compliant and its auto-sharding features.
GE developed a number of templates for how to use NDB in GE applications.
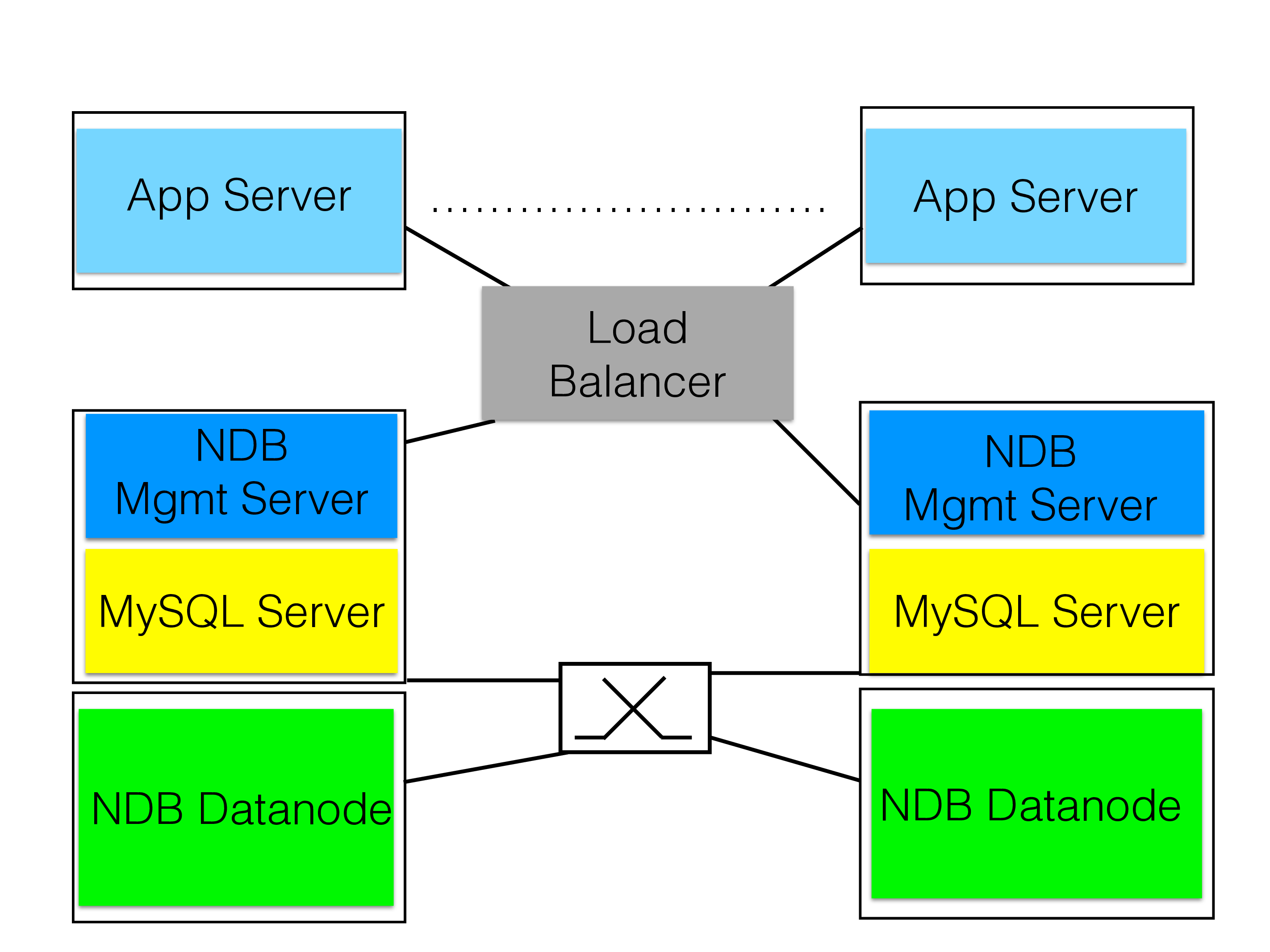
The first template shows how to setup a local cluster. It uses a standard HA setup for NDB where two computers are used for the data nodes and two computers for the MySQL Servers. NDB management servers are placed on the MySQL Server computers. This architecture can survive all single failures of one computer. It is easy to scale up both the MySQL layer (no need for extra NDB management servers though when adding more MySQL Servers) and the Data node layer.
On top of this local cluster the applications access a load balancer that will balance requests between the MySQL Servers. The NDB API contains similar functionality to ensure that data nodes are used in a balanced manner.
Takeways that GE had was to not colocate data nodes and NDB management servers. They saw the need to organize nodes correctly and to consider carefully the size of RAM to avoid running out of memory in the database.
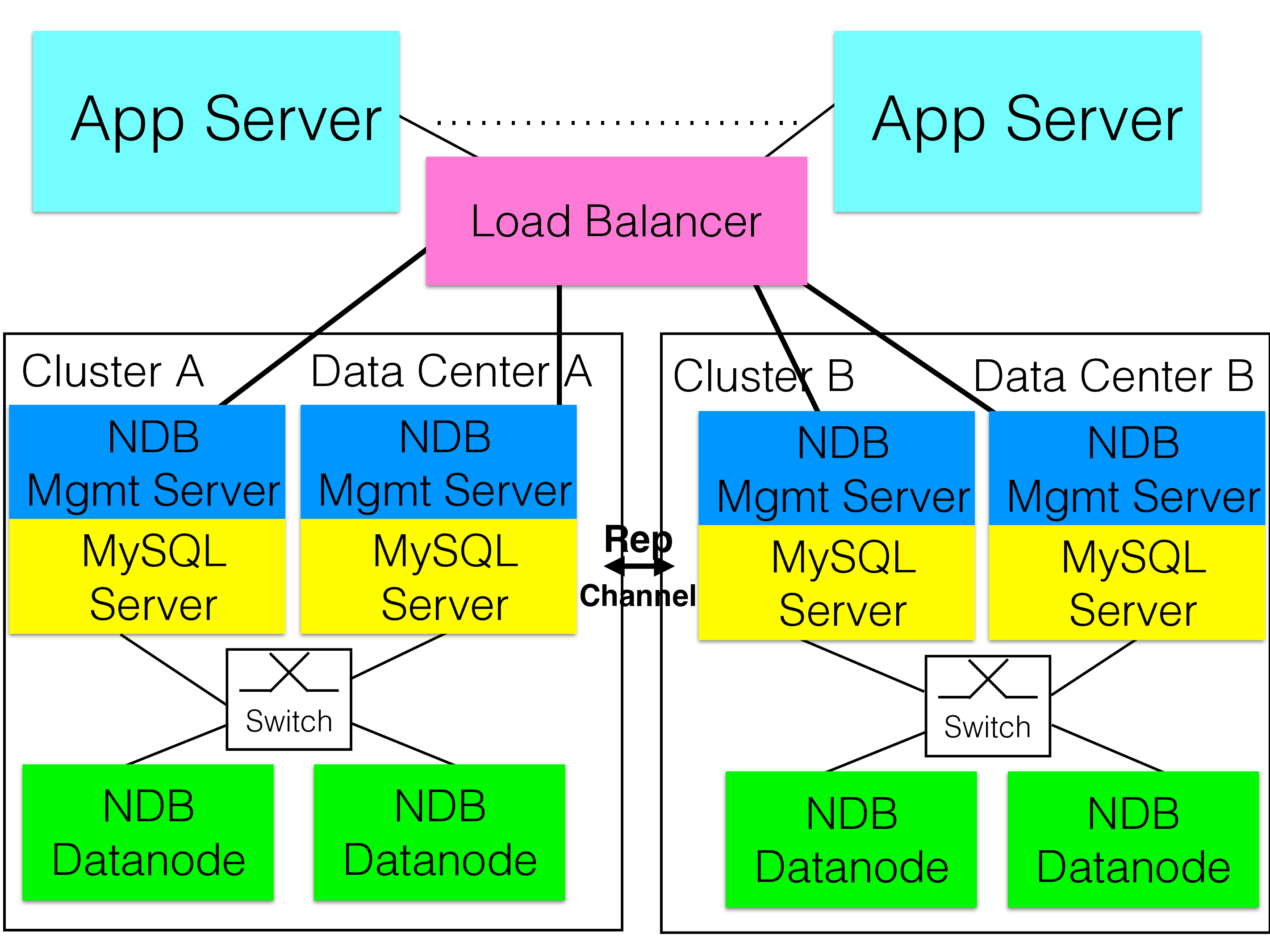
The next template uses MySQL replication combined with NDB to provide availability across regions of the world. In this case both MySQL Servers have a replication channel to the other cluster and these can be used to fail over to another replication channel in case of failure of a MySQL Server.
The MySQL replication can be extended in NDB to handle multi-site replication with more than two sites. It can handle updates coming from any of those sites. In this case there are conflict detection mechanisms available to select which transaction that should survive in case of conflicts. A number of different methods exist here that will be presented in the part on Global Replication.
Hadoop File Server#
An interesting use case for RonDB is to implement a file system upon RonDB. This is an idea I pursued myself in a hobby project of mine, iClaustron. Another example is HopsFS which is an implementation of a Hadoop File Server where the metadata servers are using MySQL Cluster to store the metadata of the file system. Another prototype have been built where NDB is used as a block device, this used the disk data parts of NDB.
NDB fits very well to implement a transactional file system. NDB can handle millions of updates per second, it can use the disk data implementation to handle parts residing on disk. The low level APIs ensure that the overhead of SQL isn’t bothering the implementation. It solves the problem of redundancy internally in RonDB, file system implementors can focus on the interface issues and solving problems with a relational database to implement a hierarchical file system. The main problem here comes when moving entire parts of the file system from one place to another.
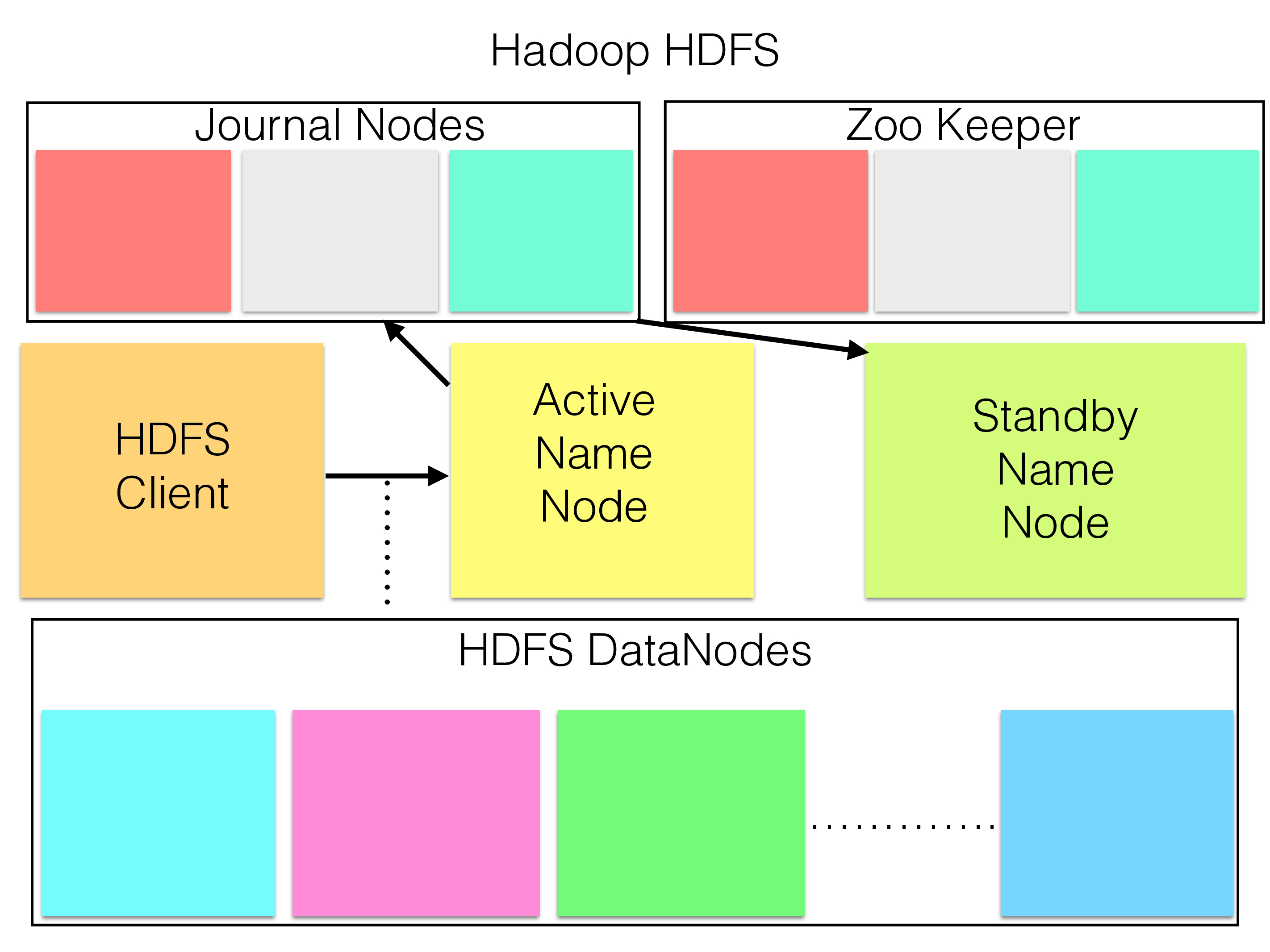
In a traditional implementation of Hadoop HDFS there is only one active Name Node handling the metadata of HDFS. Thus the file system cannot sustain more than about 75k file operations per second and the total metadata size can only grow to around 100 GBytes.
The single name node makes use of three journal nodes to replicate the changes to a stand-by name node. In addition three Zone-keeper nodes are used for heartbeating. A total of 8 nodes are needed to provide high availability of the meta data in Hadoop HDFS. This provides no scalability, only availability.
Another problem is that a large part of the files used are small files that are only a few kBytes in size. To access those through the name nodes and HDFS data nodes introduces a lot of extra latency in their access.
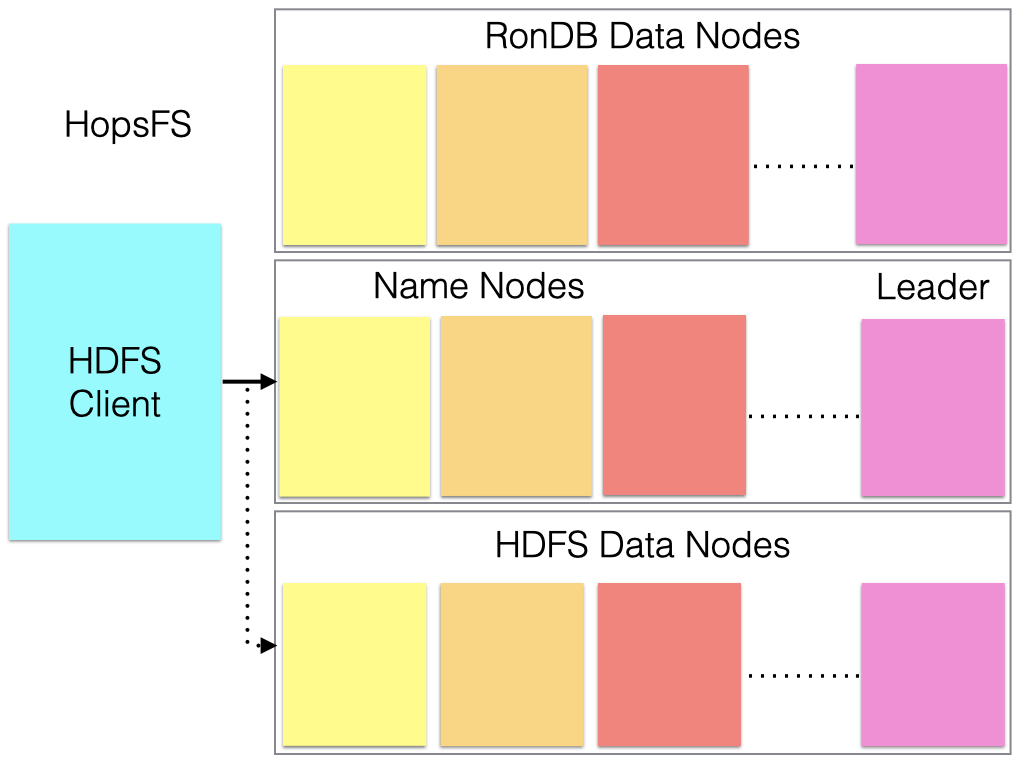
With HopsFS using RonDB the file system can scale to at least 1.4M file operations per second and given enough machines it is likely that it can scale to about 5M file operations per second. The total metadata size can scale to many tens of terabytes and it is possible to store a part of the files in RonDB. The remainder of the larger files are stored in the Hadoop Data Nodes.
SICS, a research instititute have developed HopsFS and it was presented at USENIX in early 2017. It has been proven to scale to 60 Name Nodes with 12 NDB data nodes used to store the actual data. It is now used in Hopsworks, a Feature Store for machine learning applications developed by Hopsworks AB.
HopsFS is implemented in Java and uses the ClusterJ, the native NDB API accessible from Java.
HopsFS won the IEEE Scale Challenge Award in 2017 and was presented at Usenix the same year.
Using RonDB provides better scalability compared to a centralised metadata server, it provides better availability compared to a replicated centralised meta data server.
In iClaustron the idea is to store both metadata and file data in RonDB.
HopsYARN#
Another part of the Hops infrastructure that uses RonDB is HopsYARN. It implements scheduling and resource handling services in the Hadoop framework.
Again the simplicity of getting high availability together with predictable response time is the key factor in choosing RonDB.
LDAP Server#
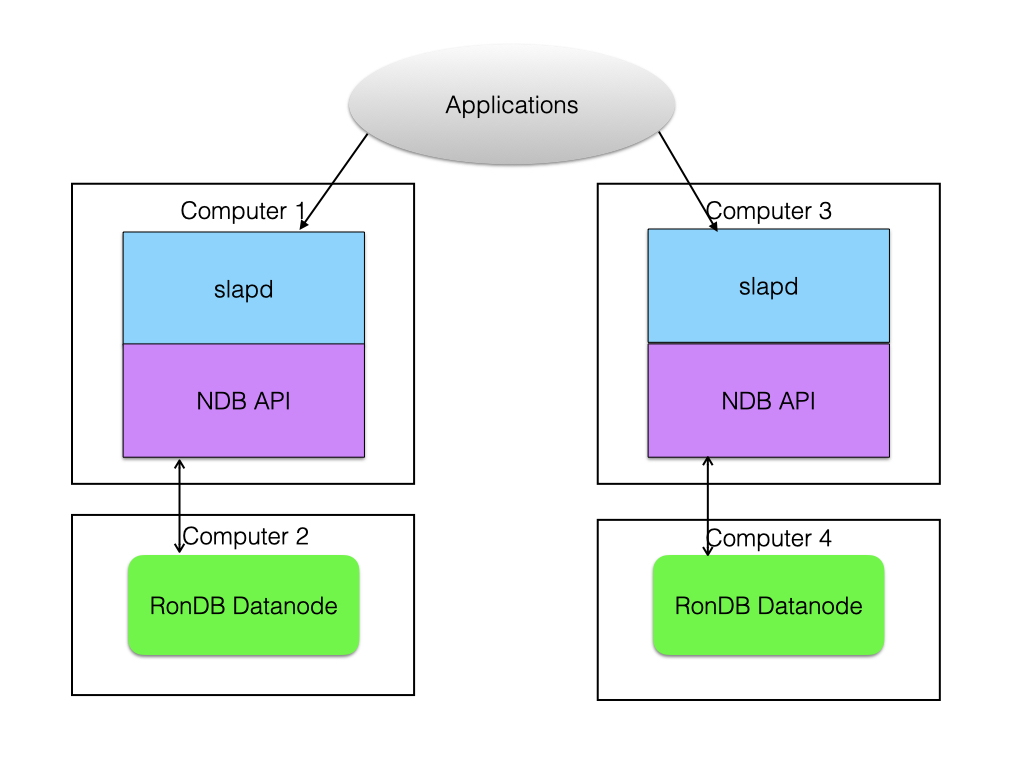
It is possible to implement an LDAP server on top of RonDB. Some users implement their own LDAP servers, but there is also a back end interface to RonDB for the OpenLDAP server that works. Using LDAP on top of RonDB provides highly available solutions for various security services.
NoSQL Applications#
Using RonDB as a key-value store by using the asynchronous API of the NDB API provides a clustered key-value store that can handle hundreds of millions of key-value lookups per second.
There are many other NoSQL applications where RonDB will be a good fit as well. It was designed for scalable and networked applications.
Conclusion#
RonDB and NDB is used in a lot of applications that requires having data always available. Most of those applications require response time to be predictable. Most of them fit into sizes of memory in modern servers.
The range of applications is very wide showing that RonDB is now a mature product that have been applied in so different application types as telecom applications, networking applications, gaming, betting, file services, LDAP servers, web sessions, web applications, real-time financial applications, medical applications and much more.
The most common reasons for not selecting RonDB is requiring bigger data sizes, or simply not being able to afford memory as data storage. RonDB have an option that one can store non-indexed attributes on disk using a page cache. This option makes it possible to store bigger data sets in RonDB. The other nice thing for RonDB is that memory is getting more and more affordable and the development of new memory types such as the new 3D XPoint by Intel promises to deliver almost 10x more memory for the same price with only slightly worse performance. Thus as technology develops, more and more applications will be able to use RonDB.
We have made prototypes running in a machine using Intel Persistent Memory with 6 TB of memory and having more than 5 TB of data stored in a single data node in memory. In another example we stored around 30 TB of data in the disk data parts in a single data node.
It is important to remember that RonDB is a fully recoverable DBMS. This means that a consistent database is restored in cases of a full cluster crash.
As a conclusion we can see that the decision in NDB to divide the Data Server from the Query Server is an important choice that allows NDB to be used in many other areas other than as an SQL database.
We can build an SQL Server on top of the Data Server as has been shown in NDB. We can similarly build a file server on top of NDB as has been shown by HopsFS in developing a Hadoop File Server based on NDB. Similarly we can build an LDAP Server on top of NDB as has been shown in OpenLDAP and by numerous telco users of NDB.
Thus the architecture of RonDB makes it useful for many types of data services requiring high scalability, high performance and high availability.
Personally I am looking forward to seeing RonDB used to implement various genealogical databases.