Setting up Active-Passive replication between RonDB Clusters#
This chapter will describe an example providing all the details required to setup an Active-Passive replication between two RonDB Clusters. To setup more complex setup will be based on this setup with additional features described in the previous chapters.
The setup uses two replication channels, a primary channel and a standby channel ready to take over replication if the primary channel fails. This means that we need two MySQL Servers in the primary cluster and two MySQL Servers in the replica cluster.
It is recommended to use separate MySQL Servers for the replication. These MySQL Servers have not any large requirements on memory and CPU. Thus one could place them in a VM with 2-4 CPUs most of the time.
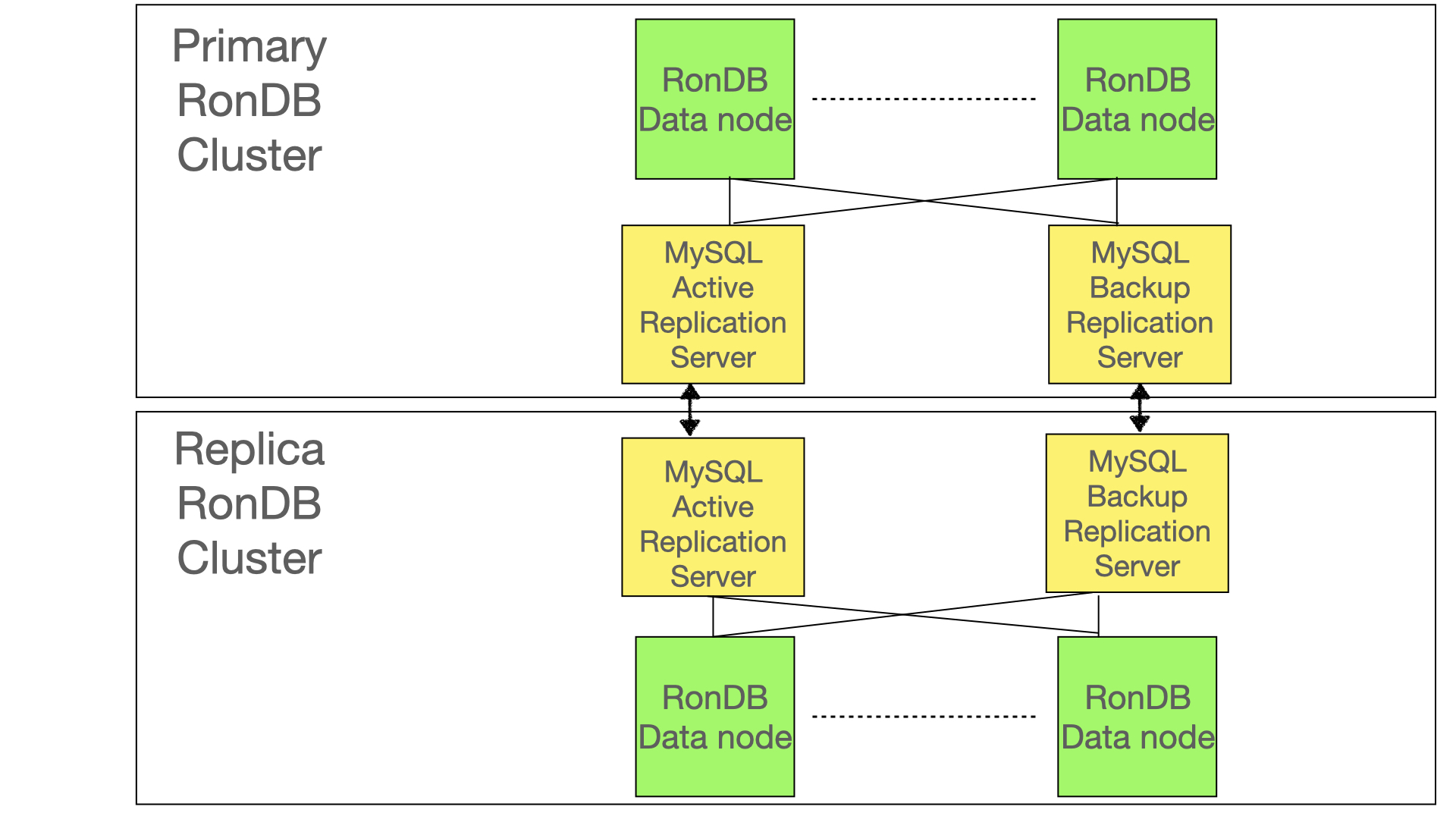
The image above shows how the setup of the MySQL Servers is done. There are two sets of MySQL servers. Each set implements one replication channel. If any of the MySQL Servers in the channel fails, we will failover to the other replication channel. If both channels fail this could be caused by multiple reasons.
One reason could be that the primary cluster failed in which case we need to fail over to the backup cluster.
The second option is that at least one of the MySQL Servers in each replication channel failed leading to both replication channels failing. In this case it is likely we need to start up the replication again from a backup of the primary cluster.
The third option is that we could have a failure of both replication channels if the replication cannot keep up with the write rate of the primary cluster. This also requires starting up the replication again from a backup of the primary cluster.
Thus in all cases we need to restart the replication from a backup in both cases, but failure of primary cluster is more involved.
Failing over to another Cluster isn’t covered by this description. Failover to another cluster requires moving applications to a new RonDB Cluster. This requires changes of lots of things outside of RonDB control such as load balancers, DNS servers and other means of routing application requests to the correct RonDB Cluster.
MySQL users required for a replication setup#
The replication between RonDB Clusters uses MySQL Servers, MySQL users have a set of permissions, we need permissions to do the actions we need for replication. Given that writing scripts for setting up and monitoring replication channels requires handling of passwords we will show the recommended method to handle this in the MySQL Server.
Password handling#
MySQL have a tool that can be used for password handling. This tool is called mysql_config_editor. The tool edits a file called .mylogin.cnf placed in the users home directory.
The example below shows how to add an entry to this file such that we can login to the local root user without displaying the password. The password is not provided on the command line, it is entered directly into the tool. The password is written in an encoded format in the .mylogin.cnf file.
After this code has been entered we can login to the local root user through the following command.
No password is required, it will be fetched from the .mylogin.cnf file in the users home directory.
To show the users entered into this file one can see this using the following command.
It will print ****** instead of the password. The user name and the hostname will be printed in clear text.
It is possible to use also to set up login to remote hosts. If you want to set up mysql_config_editor to login to the MySQL Server in the primary cluster (in this example we place this server on 192.168.0.111) use the following command. We assume the user name here is repl_hb.
mysql_config_editor set --login-path=repl_hb --user=repl_hb --host=192.168.0.111 --password
PASSWORD
Local root user#
To setup things we need a local root user that have permissions to set up users and setup replication. This is normally created when initialising the MySQL Server at initial startup.
Replication user#
The replication user is setup in MySQL Servers in the primary cluster. Since we want to be able to handle Cluster failover, we will create this user in all MySQL Servers used for replication. We need to provide at least the REPLICATION SLAVE permission, but also REPLICATION CLIENT and REPLICATION_SLAVE_ADMIN can be useful additions.
The following SQL statements adds this user and his permissions to the local MySQL Server.
CREATE USER 'repl_user'@'HOSTNAME' IDENTIFIED WITH mysql_native_password BY 'password';
GRANT REPLICATION SLAVE ON *.* TO 'repl_user'@'HOSTNAME';
GRANT REPLICATION CLIENT ON *.* TO 'repl_user'@'HOSTNAME';
GRANT REPLICATION_SLAVE_ADMIN ON *.* TO 'repl_user'@'HOSTNAME';
The HOSTNAME should be hostname or IP address of the MySQL Server applying the changes in the replica cluster. Thus it should be created in the MySQL Servers in the primary cluster and used from the MySQL Servers in the replica cluster.
Each MySQL Server only need to access one other MySQL Server, so it is possible to use separate passwords without any extra work.
Heartbeat user#
The replication is only active when there is something written to the databases replicated. To ensure that there is always activity we use a replication table that is defined in the primary cluster and all writes are replicated to the replica cluster.
The writes are issued from the scripts running in the replica cluster. Each such VM sends updates through both MySQL Servers in the primary cluster to ensure that the write is actually performed as part of the replication monitoring scripts.
This means that we need to define a user that can be accessed from all MySQL replication servers in the replica cluster. To prepare for cluster failover we also setup this user for replication in the other direction.
In preparation for this user creation we should create a database housing the heartbeat table. We should also create the heartbeat table. This is a very simple table with 2 columns and two rows. There is a primary key and a counter incremented on each write (to ensure that the row changes and thus gets replicated to the other side).
In our examples we will use the following table definition in the database called heartbeat_db.
The user in the MySQL replication servers in the primary cluster should be created with privileges to SELECT and to UPDATE this table. The scripts on the replica cluster will send UPDATEs on this table to the MySQL Servers in the primary cluster.
A common password for these users will be a bit simpler, but not very problematic to use different passwords either.
Setting up the replication in the replica cluster#
Activating binlog#
The first step in setting up replication is to ensure that all the MySQL replication servers have been started with binlog active. If it isn’t started yet, then set up the configuration to activate the binlog and restart the MySQL replication servers.
To check if the binlog is active use the following command in the MySQL Server:
This command will provide the value of this configuration variable with OFF if it is not active and ON if it is active.
Set replication source in replica cluster#
Next step is to set up the replication source in the replica cluster (as usual set up in all MySQL replication servers). Below is a command to do this. This command sets the user name and password to be used and points to the MySQL Server in the primary cluster in the SOURCE_HOST below.
CHANGE REPLICATION SOURCE TO
SOURCE_HOST='PRIMARY_CLUSTER_HOST',
SOURCE_USER='repl_user',
SOURCE_PORT=3306,
SOURCE_PASSWORD='password',
SOURCE_LOG_FILE='binlog.000001',
SOURCE_LOG_POS=4;
The above command sets up replication to start from the initial position in the binlog position (it always start at position 4). The only time we use this starting binlog position is when the replication is set up from a cluster that was started from initial start.
In most cases we will set up a new SOURCE_LOG_FILE and SOURCE_LOG_POS since the cluster is already active. This change have to happen before we start the replication through the START REPLICA command. But this can wait until we know where to move the position before activating the replication.
Backup in primary cluster#
If we start both clusters from an initial state there is no need to transfer any data from the primary cluster to the replica cluster. They are already in synch and the replication source will work fine.
However in most cases we will start up the replica cluster when the primary cluster is already running. In this case the first step is to take a backup in the primary cluster. This is performed using the RonDB Management client (ndb_mgm) with the following command.
The 1 here is the backup id, this can be set to any 32-bit number. The command here waits for the backup to complete. The SNAPSHOTEND means that the backup will use a REDO log to ensure that the consistency point is at the end of the backup. The backup will be transaction consistent to a specific point. This point is stored in the backup and makes it possible to figure out from where to start the replication.
The backup files will be spread in all data nodes in the primary cluster. These files need to be copied over to the computers or VMs in the replica cluster from where the restore is done.
To copy over the files the backup files is normally placed in the RonDB data directory in the directory BACKUP. In this directory there will be a directory called BACKUP-1 in the above case where 1 is the backup id.
So one method to copy the files is to execute the following commands in each data node.
cd RONDB_DATADIR/BACKUP
tar cfz BACKUP_NODEID.tar.gz BACKUP-1
scp BACKUP_NODEID.tar.gz REPLICA_CLUSTER_HOST:/RESTORE_DIR/.
RONDB_DATADIR is the data directory used by the RonDB data nodes. NODEID is the node id of the data node from which we copy the files. REPLICA_CLUSTER_HOST is the hostname of the computer or VM in the replica cluster from which we will restore the backup. RESTORE_DIR is the directory we place those backup files. 1 is the backup id used when creating the backup.
In a large cluster it could be necessary to run the restore of the data from more than one VM in the replica cluster. In this case the above REPLICA_CLUSTER_HOST will be spread onto several VMs that will receive the restore data to restore different nodes from the primary cluster.
Restoring the backup in the replica cluster#
Now we are ready to restore the backup in the replica cluster. If the replica cluster is started from an initial state we can simply start restoring the data. If the cluster contains data, we need to remove this data. The simplest method to remove this data is to remove all user databases.
The first step is to restore the tables, however one thing to consider here is how to handle tablespaces and the logfile group used for disk columns. If those already exists or if they were created as part of the initial start of the cluster then we need to ensure that we don’t attempt to create those as part of restore. We will assume here that they already exist, if not simply remove the parameter no-restore-disk-objects.
The restore-meta command#
The following command needs to be executed on one of the hosts in the replica cluster that have access to at least one of the backup tarballs sent from the primary cluster.
cd RESTORE_DIR
tar xfz BACKUP_NODEID.tar.gz
rm BACKUP_NODEID.tar.gz
ndb_restore --ndb-connectstring=NDB_CONNECTSTRING \
--restore-meta \
--no-restore-disk-objects \
--nodeid=NODEID \
--backupid=1 \
--backup-path=RESTORE_DIR/BACKUP-1
Here the NDB_CONNECTSTRING is the host(s) where the RonDB Management server is running. This will restore all tables, indexes and foreign keys. Some things such as VIEWs, TRIGGERs are only defined in individual MySQL servers. Thus if these need to be replicated as well one would use mysqldump for that purpose.
The restore-epoch command#
The next step in restoring is to restore the epoch that is used to synchronize the backup and the replication.
ndb_restore --ndb-connectstring=NDB_CONNECTSTRING \
--restore-epoch \
--nodeid=NODEID \
--backupid=1 \
--backup-path=RESTORE_DIR/BACKUP-1
This command should also be executed only once, so preferrably immediately after the restore-meta command.
The restore-data commands#
Now time has come to restore the data in the backup. This has to be performed for each data node tarball. It can be executed in parallel for all data nodes or serially, one by one.
ndb_restore --ndb-connectstring=NDB_CONNECTSTRING \
--restore-data \
--nodeid=NODEID \
--backupid=1 \
--backup-path=RESTORE_DIR/BACKUP-1
As mentioned this command needs to be executed for each NODEID in the primary cluster.
As mentioned in the chapter on restore one could disable indexes before restoring the data and after completing the restore of the data enable the indexes again. This could potentially make the restore go a bit faster. The disable index and enable index commands only need to be executed once for one of the NODEID’s of the primary cluster since all nodes store the meta data of the RonDB cluster.
Starting the primary replication channel#
With the backup restored in the replica cluster and the binlog activated in the primary cluster we are ready to start the primary replication channel now.
To start the primary replication channel we need to find the binlog position to start from. As part of the backup we stored the epoch that is restored by the backup in the ndb_apply_status table with the column server_id set to 0.
Thus we execute the following commands to retrieve the epoch from which we need to start the replication channel. This command is executed by the primary MySQL replication server in the replica cluster.
The result of this query should be piped into a file we call TMP_FILE (it could be placed anywhere with any name). Use the following command to store the epoch number in a shell variable.
Now armed with the restored epoch number we need to get the binlog position. We get this by querying the ndb_binlog_index table in the primary MySQL replication server in the primary cluster. This table maps the epoch to a binlog position.
This is a bit complicated, it is explained by Frazer Clement in the MySQL bug report 110785. The epoch created by the backup is on the form where the lower 32 bits is the Global checkpoint identifier that will be restored by the backup. The higher 32 bits is 0xFFFFFFFF. This epoch id will never exist in reality. Thus it is a logical epoch where we should start at the first epoch which is higher than this pseudo epoch number.
To get hold of the starting binlog position we can find this in two ways.
First by using the following query:
SELECT SUBSTRING_INDEX(next_file, '/', -1) AS file,
next_position AS position
FROM mysql.ndb_binlog_index
WHERE epoch <= $RESTORE_EPOCH
ORDER BY epoch DESC LIMIT 1;
or by using the following query:
SELECT SUBSTRING_INDEX(File, '/', -1) AS file,
position AS position
FROM mysql.ndb_binlog_index
WHERE epoch > $RESTORE_EPOCH
ORDER BY epoch ASC LIMIT 1;
Thus either find the epoch just before the pseudo epoch and go to the position of the next epoch in the binlog. Or go to the first epoch after the pseudo epoch and start from the position of this epoch.
The strategy should be to first try with the first query, if this succeeds then we have found the binlog position to start from. However it is not certain that the ndb_binlog_index table has any epochs that satisfy the query. In this case we will attempt to use the second query. The second query often does not have any returned rows, thus it is better to start with the first query. This will lead to finding the binlog position as quickly as possible.
These queries must be sent to the MySQL replication server that is our channel partner as shown in the figure in the beginning of this chapter. The MySQL replication servers are not necessarily synchronised in the binlog index positions, so this query must be issued towards the correct MySQL replication server.
Now we will retrieve the binlog file and position from the above query again by piping the result of this query to a TMP_FILE using the following commands.
FILE=$(cat TMP_FILE | awk '(NR>1)' | awk -F "\t" 'print $1)')
POSITION=$(cat TMP_FILE | awk '(NR>1)' | awk -F "\t" 'print $2)')
Armed with the binlog position we can now use this to set up the replication source in the primary MySQL replication server in the replica cluster using the following command.
CHANGE REPLICATION SOURCE TO
SOURCE_LOG_FILE='$FILE',
SOURCE_LOG_POS=$POSITION,
IGNORE_SERVER_IDS=(21,22);
server_id is a MySQL Server configuration setting required to handle replication between RonDB clusters. If not using the MySQL Server for replication, it is not necessary to set server_id, it will default to 0, but won’t be used for anything.
For replication between RonDB clusters the server_id is used to break circular replication. All replication records have a note about which server_id they originated from. Thus when a replication record is to be applied we can see if the replicated record originated in this RonDB cluster. If so the replication record can be safely ignored.
The server_id is set in the MySQL Server configuration file. It is important that all MySQL Servers have different server_id’s. In our example we assume that the Primary RonDB cluster use server_id 11 for the active MySQL replication server and 12 for the backup MySQL replication server in the primary RonDB cluster. In a similar fashion we set the server_id to 21 and 22 in the replica RonDB cluster.
Since we want to prepare for failover handling, we set the IGNORE_SERVER_IDS to ignore both the MySQL replication servers in the primary cluster and not just our MySQL server.
We don’t need to provide the hostname, username, password and port in this command since these were set up earlier in the process.
This command needs only to be executed for the channel where we are aiming to activate the replication. The above command is always preceding activation of a replication channel to ensure that we start from the correct position.
At this point everything is ready to start the replication process now which is done through the following command.
Now the replication starts up and the replica cluster should soon have catched up with the primary cluster and every change in the primary cluster will soon after also be applied in the replica cluster.
Handling failover of replication channel#
The previous section showed how to setup the primary replication channel. The backup replication channel need not be set up yet. However as soon as we start the primary replication channel we need to start monitoring the replication channel.
This monitoring should be done in both replication channels to ensure that we have dual checks that the primary cluster is still operational. We will treat a failure of both replication channels as a failure of the primary cluster that requires a failover to the replica cluster.
Failing over to the replica cluster will not be covered here, it involves a lot of actions that are application specific. It probably includes redirecting some load balancers, redirecting applications to the replica cluster. This part is specific to the RonDB application and can thus not be covered here.
However failing over to the backup replication channel is fairly straightforward, so we will cover how to monitor the replication channel and how to fail over the replication channel.
Monitoring replication channel#
The indication of that the replication channel is working can be seen through the ndb_apply_status table. This table is updated each time an epoch is applied in the replica cluster. There is one entry in this table for each MySQL replication server in the replica cluster.
However epochs are only applied if there is some transaction to replicate from the primary cluster.
RonDB has the ability to replicate also empty epochs, but epochs happens at intervals of around 100 milliseconds and can be even smaller than this. Thus it is better that the monitoring is done through a table that is constantly updated by the monitoring of the replication channel.
For this purpose we use the heartbeat user that updates the table heartbeat_table in the database heartbeat_db at regular intervals.
There will be only 2 rows in this table, the primary replication channel uses the first row and the backup replication channel uses the second row in the table.
The monitoring happens at regular intervals, e.g. every 5 seconds. Remember that a broken replication channel will not cause any application issues since the replica cluster is in passive mode. Thus detecting the failure of the replication channel isn’t very urgent. It is more related to how fast we want to detect failure of the primary cluster.
The query thus looks like this, applied to any of the MySQL replication servers in the primary cluster.
Here the UPDATE_COUNTER is loop counter in the monitor, pk=1 for the primary replication channel monitor and pk=2 for the backup replication channel monitor.
At each interval the heartbeat_table is updated using the primary MySQL replication server in the primary cluster. If this update fails, use instead the backup MySQL replication server in the primary cluster. The monitoring in the backup MySQL replication server in the replica cluster does the same thing every interval.
As part of each interval one should also check that the replication has progressed since the last interval. To handle this the monitor keeps track of the epoch applied in the replica cluster using the ndb_apply_status table. This is also monitored by both replication channels.
The query to check this looks like this:
Here we assume that the server id’s of the MySQL replication servers in the primary cluster are 11 and 12, obviously these numbers need to be replaced with the correct server ids. The result is piped into a TMP_FILE as above and the below command gives use the last epoch number applied in the replica cluster.
The script to handle the replication channel monitoring and takeover should setup the various hostnames, server ids, port numbers and file directories in a configuration file. Thus these variables could be exported shell variables if shell scripts are used.
The content of the TMP_FILE will look like below when executed from script.
Thus we simply need to remove the first line and we have the desired epoch.
Below is an example of the output produced by querying this table in one of the MySQL replication servers in the replica cluster. At the initial start there will only be one record in the table for the active server_id, after a failover there will also be an old record for the now passive server_id. This is why we select the MAX(epoch). We are not interested in the server_id, we are only interested in finding the epoch that has been replicated to the replica cluster.
mysql> SELECT server_id, epoch FROM mysql.ndb_apply_status WHERE server_id IN (11,12);
+-----------+---------------+
| server_id | epoch |
+-----------+---------------+
| 11 | 1653562408963 |
| 12 | 1803886264321 |
+-----------+---------------+
2 rows in set (0.00 sec)
If this LAST_EPOCH is the same as the previous interval the replication channel didn’t progress during the last interval. If a number of interval in a row fails then we declare the replication channel as broken and start the failover handling of the replication channel. The time to detect a failure is the time per interval multiplied by the number of intervals without progress before we declare the replication channel as broken.
The monitoring is performed in both channels. But the action on broken channel is different. The primary replication channel will only stop the replication and will not do any action to start the replication in the backup replication. This uses the STOP REPLICA command in its local MySQL replication server.
Actions to take over as primary replication channel#
At first the backup replication channel also issues the STOP REPLICA command to the primary MySQL replication server in the replica cluster. This is simply a safeguard to ensure that we don’t run two replication servers in the replica cluster.
The take over processing is the same as the start of a replication channel. We already know the epoch to start from. This is the LAST_EPOCH that was the last epoch applied in the replica cluster.
Using this epoch we need to issue the query to retrieve the binlog position in the backup MySQL replication server in the primary cluster.
Note that the binlog position in the replication servers in the primary cluster are not synchronised. Thus the binlog position of the primary replication channel is unrelated to the binlog position of the backup replication channel.
Thus the commands to take over as primary replication is the following commands:
The first query is towards the backup MySQL replication server in the primary cluster.
SELECT SUBSTRING_INDEX(next_file, '/', -1) AS file,
next_position AS position
FROM mysql.ndb_binlog_index
WHERE epoch <= $LAST_EPOCH
ORDER BY DESC LIMIT 1;
The ndb_binlog_index table should always contain some row smaller or equal to the epoch unless the table has been purged more than allowed. In the case of a channel failover it should more or less always contain an epoch equal to the one we are continuing the new channel with.
To safeguard against the case that the ndb_apply_status table has recorded some empty epochs not listed in the ndb_binlog_index table we use the less than or equal and select the epoch with the highest epoch. Normally thus this should be the epoch number we are searching for.
The following commands analysing the output of the above query are executed in the local MySQL replication server of the new primary MySQL replication server in the replica cluster (the previous monitor of the backup replication channel).
An example query shows how for each epoch completed an entry is made in the ndb_binlog_index table providing the next binlog file and position for this epoch number. The epoch used in the query is the epoch that was the last epoch already replicated.
mysql> SELECT epoch,
SUBSTRING_INDEX(next_file, '/', -1) AS file,
next_position AS position
FROM mysql.ndb_binlog_index
WHERE epoch <= 3182570766345
ORDER BY epoch DESC LIMIT 4;
+---------------+---------------+----------+
| epoch | file | position |
+---------------+---------------+----------+
| 3182570766345 | binlog.000005 | 107493 |
| 3182570766344 | binlog.000005 | 107007 |
| 3173980831744 | binlog.000005 | 106521 |
| 3169685864457 | binlog.000005 | 106035 |
+---------------+---------------+----------+
4 rows in set (0.01 sec)
Important here is that in this query we can select the epoch equal to the LAST_EPOCH. It is safe that this exists in the ndb_binlog_index table since we know that this epoch was replicated to the replica cluster. Since we picked the next file and position, this means that it will start replicating from the first epoch after the epoch already replicated.
The output is sent to the TMP_FILE and processed like below to get the FILE and POSITION from where to start the replication.
We remove the first line again and find the binlog file in the first word in the line and binlog position in the second word. We use those values in the CHANGE REPLICATION SOURCE command.
FILE=$(cat TMP_FILE | awk '(NR>1)' | awk -F "\t" 'print $1)')
POSITION=$(cat TMP_FILE | awk '(NR>1)' | awk -F "\t" 'print $2)')
CHANGE REPLICATION SOURCE TO
SOURCE_LOG_FILE='$FILE',
SOURCE_LOG_POS=$POSITION,
IGNORE_SERVER_IDS=(21,22);
START REPLICA;
At this point the replication channel has switched role and we need to ensure that the monitor is aware of the role it now has. This means that the script has to have a variable that indicates whether it is the active replication channel or the passive replication channel. At channel takeover the passive replication channel changes this variable to indicate it is now the active replication channel. The active replication channel changes the variable to become the passive replication channel.
If the script is started while the other replication channel is active, then it should be initialised as the passive replication channel.
At initialisation of both replication channel one first activates the active replication channel. After activation one starts the script initialised as active replication channel. In the other MySQL replication server in the replica cluster one starts the script as the passive replication channel.
Failure of replication#
One manner which replication can fail is that the replication cannot keep up with the primary cluster updates. This could lead to that we lose some replication events. In this case the replication channel cannot be restored, the replication has to be restarted using a backup from the primary cluster.