Automatic Memory Configuration in RonDB#
This documentation is based on RonDB 22.10 with a few mentions of changes in RonDB 24.10. The main difference to RonDB 21.04 in 22.10 is that the SchemaMemory and ReplicationMemory is now part of the global memory management. In 21.04 the schema memory was by default set to the maximum size of number of tables. This wasted a bit of memory, but made configuration a lot easier. In 22.10 and 24.10 the waste of memory is no longer present since it is part of the global memory manager.
RonDB allocates all its memory at startup. After startup there is no memory allocations or freeing of memory except that new file system threads could be allocated. Most of the memory is managed by the global memory manager in RonDB that ensures that the memory distribution can change over time as different parts require more or less memory.
Automatic memory configuration provides the possibility to scale the memory usage in RonDB up and down. This makes it possible to easily manage RonDB in a cloud setting. When more memory is required by the applications, it allows one to simply move the RonDB data nodes to VMs that have more memory available.
The first section describes the configuration parameters that affect the automatic memory configuration. By default no configuration parameter at all is required. Automatic Memory configuration is default and the default setting is that we use all memory available in the computer or VM. We only leave as much as is necessary for the OS to work properly and some safety levels.
The second section describes how the size of each of the memory parts are calculated.
The third section describes each of the major RonDB memory regions and what they are used for. It also describes how much memory they are allowed to use and how much memory is reserved for each memory region.
The final section describes how automatic memory configuration calculates the memory configuration at startup of a RonDB data node.
Every time a RonDB data node starts up it will log all the important values of sizes of each memory region.
Memory configuration parameters#
The configuration parameters have three levels. The top level is whether automatic memory configuration is used. Most of the documentation will describe this case since this is the normal use case, but we will shortly mention what happens also when this parameter is not set.
The second level is to figure out the total memory usage we are allowed to use. This depends on the configuration parameter TotalMemoryConfig. By default this is set to 0, 0 means that we get the memory size from the hardware portability layer. In Linux the information is found in /proc/meminfo. If set to something else it is the total memory configuration required. It cannot be set lower than 2GBytes and for that to work a few more configuration variables needs to be set. RonDB scales well to using up to 16 TBytes of memory, it has been tested with more than 5 TBytes of memory in a benchmark. Mostly RonDB data nodes use 128 GBytes and more in production use cases.
The third level is that there are a number of configuration variables that affects the calculation of the memory regions.
The memory is affected by the following configuration parameters:
-
MaxNoOfTables (default: 8000)
-
MaxNoOfOrderedIndexes (default: 10000)
-
MaxNoOfUniqueHashIndexes (default: 2300)
-
MaxNoOfTriggers (default: 200000)
-
MaxNoOfAttributes (default: 500000)
-
MaxNoOfConcurrentOperations
-
PartitionsPerNode (default: 2)
-
NoOfReplicas (no default, mandatory to set)
-
SendBufferMemory (default 8 MByte per transporter (usually a socket)
-
Number of nodes in the cluster
-
Number of threads in the data node
-
LongMessageBuffer
-
RedoBuffer
-
UndoBuffer
-
BackupLogBuffer
-
OsStaticOverhead (default: 0)
-
OsCpuOverhead (default: 0)
-
DataMemory
-
DiskPageBufferMemory
-
TransactionMemory
-
SchemaMemory
-
BackupSchemaMemory
-
ReplicationMemory
-
SharedGlobalMemory
This list can be daunting to consider, the good news is that by default not a single one of those need to be set. RonDB is very good at setting the defaults by itself. Additionally almost all the memory is managed by a global memory manager that allows the same memory to be used for many different purposes. Thus memory usage is in no ways static in RonDB, memory will be used by different parts dependent on the current needs.
Examples of when to use configuration variables#
If the application uses a lot of large tables RonDB will use more memory for the SchemaMemory, if the application runs very large transactions RonDB will use much memory in TransactionMemory.
At the same time it is possible to use those parameters to create data nodes with minimal amount of memory. In our test frameworks we usually set a number of those with TotalMemoryConfig set to a few GBytes. The MTR test framework runs with extremely small configurations (not using automatic memory configuration), often using only a few hundred MBytes per node thus making it possible to run functional tests on up to ten RonDB clusters in parallel on a single machine.
If the application requires more than 20.300 table objects one can set MaxNoOfTables to a much larger value (RonDB can support up to at least 200.000 table objects.
ReplicationMemory is used for Global Replication and if the link between RonDB clusters is slow one might need more ReplicationMemory. might require a larger memory buffer
These are a few reasons why a special configuration is required. But for the normal user it should be sufficient to not set a single configuration parameter or possibly the TotalMemoryConfig.
We will now go through the memory regions of the Global memory manager. Next we will describe in more detail how RonDB sets up the memory configuration at startup.
RonDB Memory Regions#
The global memory manager consists of 13 regions as shown in the figure below.
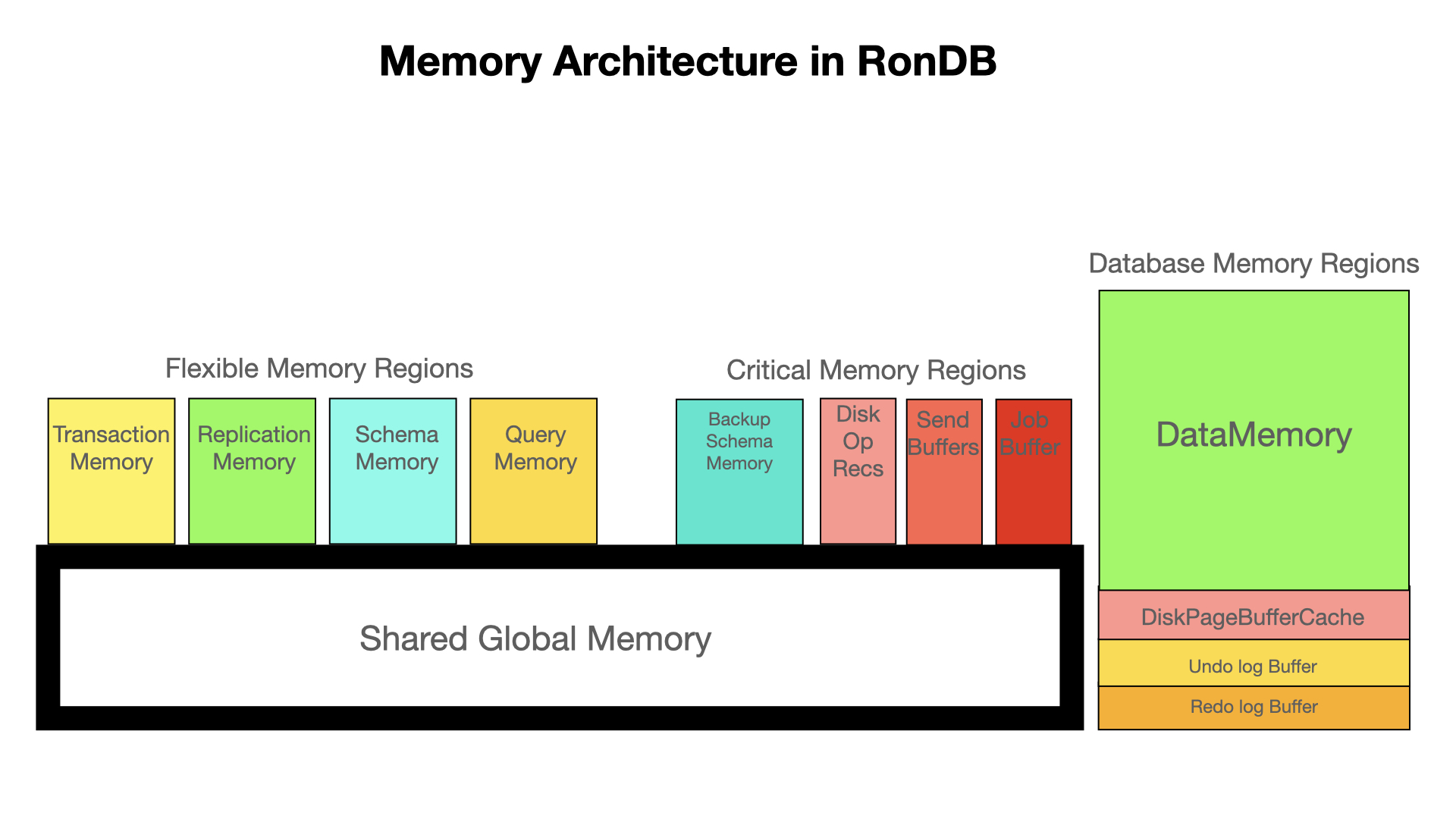
Each region has a reserved space, a maximum space and a priority. In some cases, a region will interpret the maximum space as a threshold upon which its priority is lowered. In the following, we will briefly describe the role of each region.
DataMemory#
This is the most important memory where the actual in-memory rows are stored. It also stores the hash index and the ordered indexes.
The size of the DataMemory is calculated at startup and this memory is for the most part not touched by other areas. RonDB works best if DataMemory is homogenous in all nodes. If one node has a smaller DataMemory than others, it means that the other nodes will not be able to use all of their DataMemory since data is replicated and requires all replicas to store the data. It is however ok to temporarily increase the DataMemory while increasing the storage in the cluster.
Even decreasing size of DataMemory could work, but a node will not be able to startup if it doesn’t have enough memory to store the data recovered from disk. If this happens the node restart fails and the node need to be restarted from the original size again.
DataMemory is fixed in size to ensure that we can always handle recovery. Since recovery can sometimes grow the data size a bit, we don’t allow the DataMemory to be filled beyond 95% in normal operation. In recovery it can use the full DataMemory size. Those extra 5% memory resources are also reserved for critical operations such as growing the cluster with more nodes and reorganising the data inside RonDB.
DiskPageBufferMemory#
This is the page cache used by disk columns in RonDB. Its size is calculated at startup and normally neither grows nor shrinks. Operations towards the disk are queued by using Disk Operation Records.
Transaction Memory#
This memory contains all active transactions and their operations. It is used for all sorts of operations such as transaction records, scan records, key operation records and many more records used to handle the queries issued towards RonDB.
This memory is highly flexible and can grow and shrink quickly. Its minimum size is calculated at startup, but it can grow beyond this if required.
Schema Memory#
This memory is used to store information about tables, columns, indexes, foreign keys, internal triggers. In RonDB 21.04 it is ensured to handle a very large number of tables. In RonDB 22.10 and later RonDB versions the memory is flexible and can grow, using the global pool of free memory as required.
Replication Memory#
This memory holds information used by events in RonDB. Events are changes of rows in RonDB that API nodes can subscribe to. In particular this is used to replicate to other RonDB clusters. It is also used to integrate with OpenSearch in Hopsworks.
This memory contains change events that are in the process of being sent to the API nodes subscribed to it.
Query Memory#
RonDB can handle large parallel join queries. This memory is used to store data used in this query execution. It can grow and shrink very fast and does not use any memory if no join queries are performed. This memory is not configurable, it uses zero memory and will only allow memory allocations if there is enough memory in the data node to handle more critical operations.
Send Buffers#
When sending to another node in the cluster we place the data into a send buffer before sending it. This memory has a minimum size calculated at startup, but can grow beyond this as needed.
Job Buffer#
This is memory used for internal communication channels. Its size is calculated at startup, but there is some flexibility in using it.
Shared Global Memory#
This memory is the amount of memory free to use by other regions. It is a pool of memory available for all the other regions to borrow from when they need more memory than currently available in their region.
The size of this memory is calculated at startup.
Redo and Undo Log Buffers#
These are regions that are fixed in size and allocate memory at startup. There is some functionality to handle overload on those buffers by queueing operations when those buffers are full.
The Undo log is only used for operations on disk pages.
Others#
There is memory used by Backup Schema Memory, Disk Operation Records and Schema Transaction Memory as well.
In contrast to Schema Memory, Schema Transaction Memory is memory used while creating/dropping/altering tables or indexes and is usually set to 2 MB; Schema Memory can be Gigabytes.
Memory Region Classifications#
A memory region is classified by one or more of the following qualities:
-
regions that are fixed in size
-
regions that are critical and cannot handle failure to allocate memory
-
regions have no natural upper limit and are unlimited in size
-
regions that are flexible in size and that can work together to achieve the best use of memory
We can furthermore divide regions based on whether the memory is allocated short term or long term.
These qualities are generally important, as they help assigning the memory regions a priority. The priority can however also be affected by the amount of memory that the region has allocated. In the following, we will describe the qualities in more detail.
Fixed regions#
These have a fixed size, this is used for database objects, the Redo log Buffer, the Undo log buffer, the DataMemory and the DiskPageBufferMemory (the page cache for disk pages). There is code to ensure that we queue up when those resources are no longer available.
Fixed regions: Redo Log Buffer, Undo Log Buffer, Data Memory, Disk Page Buffer Memory
Critical regions#
These are regions where a request to allocate memory would cause a crash. This relates to the job buffer which is used for internal messages inside a node, it also relates to send buffers which are used for messages to other nodes. DataMemory is a critical region during recovery - if we fail to allocate memory for database objects during recovery we would not be able to recover the database. Thus DataMemory is a critical region in the startup phase, but not during normal operation. Disk Operation Records are also a critical resource since otherwise we cannot maintain the disk data columns. Finally we also treat memory used by backups as critical since not being able to perform a backup would make it very hard to manage RonDB.
Critical regions: Job Buffer, Send Buffer, Data Memory, Disk Operation Records, Backup Schema Memory
Flexible regions#
These are regions that can grow indefinitely but that have to set limits on their own growth to ensure that other flexible regions are also allowed to grow. Thus one flexible resource isn’t allowed to utilise all the shared memory resources. There are limits to how much memory a resource can occupy before its priority is significantly lowered.
Flexible regions: Transaction Memory, Replication Memory, Schema Memory, Query Memory, Schema Transaction Memory, Send Buffers, Backup Memory, Disk Operation Records
Unlimited regions#
These have no natural upper limit, thus as long as memory is available at the right priority level, the memory region can continue to grow.
Unlimited regions: Backup Memory, Query Memory and Schema Transaction Memory
Short term versus long term#
Finally we have short term versus long term memory regions. A short term memory region allocation is of smaller significance compared to a long term memory region. In particular this relates to Schema Memory. Schema Memory contains metadata about tables, indexes, columns, triggers, foreign keys and so forth. Once allocated, this memory will stay for a very long time. Thus if we allow it to grow too much into the shared memory, we will not have space to handle large transactions that require Transaction Memory.
Long term regions: Schema Memory
Memory Region Prioritisations#
The memory region prioritisations handle to what extent the regions have access to the shared global memory. Most regions have access to it - however, they only do so once their reserved memory is used up.
4% of the shared global memory is only accessible to the highest priority regions. These are the critical regions. Internally this is called the ultra high priority. The critical regions can allocate from shared global memory as long as memory is available.
6% of the shared global memory is available also to the TransactionMemory and ReplicationMemory. We call this the high priority regions.
8% of the shared global memory is available also to medium priority regions, this is the SchemaMemory.
Finally QueryMemory is a low priority region that can only be used as long as at least 12% of the shared global memory is free.
The actual limits might change over time as we learn more about how to adapt the memory allocations.
In the following we will discuss how the flexible memory regions share their access to the shared global memory.
TransactionMemory#
The TransactionMemory region has a reserved space, but it can grow up to 50% of the shared global memory beyond that.
Failure to allocate memory in this region leads to aborted transactions.
SchemaMemory#
This region contains a lot of meta data objects representing tables, fragments, fragment replicas, columns, and triggers. These are long-term objects that will be there long-term. Thus we want this region to be flexible in size, but we don’t want it grow such that it diminishes the possibility to execute queries towards region. Thus we calculate a reserved part and allow this part to grow into at most 20% of the shared memory region in addition to its reserved region. This region cannot access the higher priority memory regions of the shared global memory.
Failure to allocate SchemaMemory causes meta data operations to be aborted.
ReplicationMemory#
These are memory structures used to represent replication towards other clusters supporting Global Replication. It can also be used to replicate changes from RonDB to other systems such as ElasticSearch. The memory in this region is of temporary nature with memory buffers used to store the changes that are being replicated. The meta data of the replication is stored in the SchemaMemory region.
This region has a reserved space, but it can also grow to use up to 30% of the shared global memory. After that it will only have access to the lower priority regions of the shared global memory.
Failure to allocate memory in this region lead to failed replication. Thus replication have to be set up again. This is a fairly critical error, but it is something that normally can be handled without application downtime.
QueryMemory#
This memory has no reserved space, but it can use the shared global lower priority regions, but at most 30% of the shared global memory. This memory is used to handle complex SQL queries.
Failure to allocate memory in this region will lead to complex queries being aborted.
BackupSchemaMemory#
This memory is used to store metadata used by backups. It is a region that belongs to the very high priority regions and can continue allocating as long as there is at least 4% free memory in the shared global memory.
Memory manager at RonDB startup#
In this section we will describe how RonDB calculates the sizes of the various regions and how the configuration parameters interact with this calculation.
SchemaMemory#
The internal calculations use the size of all the internal memory structures for columns, tables, indexes, fragments, fragment replicas to derive the required schema memory to handle the configured number of schema objects.
In a test setup one can decrease schema memory by decreasing the above parameters. MaxNoOfTables, MaxNoOfOrderedIndexes and MaxNoOfUniqueHashIndexes is mostly simply added together, so it doesn’t matter which of those that are changed, it is the sum of them that matters.
The default setup in a set up with 3 nodes and 3 replicas would use around 1 GByte for schema memory.
It is possible to completely override the calculation and set it explicitly using the SchemaMemory parameter.
A small part (25%) of the calculated schema memory is reserved. Another 25% of it is added to the SharedGlobalMemory. In addition schema memory is allowed to use a lot of memory from the SharedGlobalMemory, up to 20% of it plus the part it added to the SharedGlobalMemory. It can continue to use up to this level as long as no more than 92% of the SharedGlobalMemory has been used.
A part of the schema memory is the memory used by table objects. This is currently allocated at startup and is not part of the global memory manager. This memory size is affected by the number of tables and indexes.
BackupSchemaMemory#
Schema memory used by backups is affected by the same configuration parameters except for SchemaMemory which is replaced by BackupSchemaMemory. Also here 25% of the calculated memory is reserved and another 25% is added to the SharedGlobalMemory. It can use SharedGlobalMemory until 96% of it has been used.
ReplicationMemory#
Replication memory is used for event buffers used among other things by Global Replication. It is affected by the number of LDM threads which in turn is affected by the configuration parameter NumCPUs. See the section on Automatic Thread Configuration.
It reserves 8 MByte per LDM thread in the data node, but it can grow to use up to 30% of the SharedGlobalMemory until it is used up to 96%. The replication memory can be changed through setting ReplicationMemory.
TransactionMemory#
Transaction memory is used for a lot of different temporary memory storage such as transaction records, operation records, changed row storage and so forth. It defaults to 300 MBytes plus 45 MBytes per thread. This can be affected by a number of parameters, most importantly MaxNoOfConcurrentOperations and MaxNoOfConcurrentTransactions. It can also be directly set using the parameter TransactionMemory. All of this memory is reserved as transaction memory. In addition transaction memory can grow to use another 50% of its size from SharedGlobalMemory until 94% of it is used.
LongMessageBuffer#
Sending signals internally in a node requires often the use of long signal memory. This memory defaults to 32 MBytes plus 12 MBytes per thread (minus one). It can be set through the parameter LongMessageBuffer. This memory is not part of the global memory manager.
Job Buffer#
Job buffer memory is affected by NumCPUs as well, it needs about 1 MByte of job buffer for communication with another thread. Thus if the number of threads are 16, each thread will use about 16 MBytes of memory. If the number of threads is 32 or higher, each thread will have 32 MBytes of job buffer memory.
25% of this memory is reserved for job buffers and 25% of it is added to the SharedGlobalMemory. Job buffer memory can be allocated as long as there is free memory in the SharedGlobalMemory.
RonDB Static memory#
Next we compute the static memory, this includes a fair amount of memory used by blocks, stacks and internal data structures. It is again affected by the NumCPUs. This memory is not managed by the global memory manager, it is allocated at startup and never released until the node stops.
OS Static Memory#
If the TotalMemoryConfig was the default (not set) then we need to calculate the memory we need to avoid using to ensure the OS can do its operation.
By default this is 1400 MBytes plus 100 MBytes for each thread in the data node (affected by NumCPUs. These two parameters can be changed through the configuration parameters OsStaticOverhead and OsCpuOverhead. In addition we reserve 1% of the memory in the computer/VM for the OS.
Send Buffers#
Next we calculate the memory required for send buffers. Each data node need a send buffer to communicate with each other node in the RonDB cluster. This is by default influenced by the SendBufferMemory parameter that defaults to 8 Mbytes per node to communicate with, another 2 MByte is added per thread. One can also instead set TotalSendBufferMemory. Half of the memory is reserved for send buffers and the other half added to the SharedGlobalMemory. Send buffers can allocate from SharedGlobalMemory as long as there is free memory there.
BackupLogBufferMemory and LCPs#
Next we calculate the memory used by backups and local checkpoints (LCPs). Most of this are not configurable except for the backup log buffer memory size (BackupLogBufferMemory). These are multiplied by the number of LDM threads in the node. This memory is not managed by the global memory manager and is allocated at startup and never released.
Restore Memory#
Next the memory required by restore is 4 MBytes per thread, this memory is allocated at startup and not released until node stops.
Packed signal memory#
Next we have memory used for sending packed signals, this is affected by the number of LDM threads and TC threads. The memory is allocated at startup and not released until node stops.
RonDB file system memory#
Next we calculate the memory used by the file system threads, this is affected by the number of threads, so mostly it allocates 4 MBytes per thread. This memory is allocated when a file system thread is created and then kept until the node stops.
SharedGlobalMemory#
Next we calculate the the memory for the SharedGlobalMemory. By default this is 700 MBytes plus 50 MBytes per thread. It can be changed by setting SharedGlobalMemory. The global memory also gets incremented from the other parts mentioned above.
RedoBuffer and UndoBuffer#
We also calculate memory for REDO buffers, this memory is all reserved for the REDO buffers although managed by the global memory manager. It defaults to 32 MBytes per LDM thread times the number of log parts (defaults to 4). One can affect these settings through RedoBuffer and FragmentLogParts. The RedoBuffer setting is memory per LDM thread and will also be multiplied by number of REDO log parts.
Similarly UNDO log buffer for disk columns is 64 MBytes of reserved memory per LDM thread. The parameter UndoBuffer can be used to change this, it is the total UNDO log buffer size in this case that is changed through UndoBuffer. All the UNDO log buffer is reserved and maintained by the global memory manager.
DataMemory and DiskPageBufferMemory#
All the above calculations gives us the memory storage required to operate RonDB data nodes for transactions, backups, schema information, checkpointing, signal sending inside nodes and between nodes. The rest of the memory will now be used to store the actual data which the database consists of. These have two parts, the DataMemory which is used for in-memory columns and rows. The second part is the disk page cache which can be set through the parameter DiskPageBufferMemory. Both of those parameters are by default calculated from the remaining memory after calculating the used memory so far and subtracting this from the memory we had at hand.
90% of the remaining memory is used for DataMemory and 10% is used for DiskPageBufferMemory. The memory for those two parts must be at least 512 MByte for RonDB data nodes to start using automatic memory configurations.
The MTR test suite that is testing various functional behaviours in RonDB requires a much smaller setup, thus most of those tests do not use automatic memory configurations.
Example#
In this example we started a single data node on a workstation with 128
GByte of memory. We set PartitionsPerNode to 6 to make most of the
calculations mimic a normal setup with NoOfReplicas set to 3 instead of
to 1. The major difference to a 3-node setup is that a 3-node setup
would use more memory for replication records, around 25 MBytes more
memory would be added to SchemaMemory and SharedGlobalMemory. In
addition we set OsStaticOverhead to 10G, this parameter allows us to
leave some memory for other processes on the machine.
The machine uses a debug compiled RonDB 24.10.8 with some debug flag that prints a bit more information about the sizes of various records and more details on how much memory is allocated in various parts of the node.
The machine represents a fairly standard VM used by RonDB in a Kubernetes running on VMs with 16 CPUs and using a StaticCpuManager to enable locking threads to certain CPUs in the Kubernetes nodes. The amount of OsStaticOverhead would be smaller in a Kubernetes setup.
2025-08-27 12:55:28 [ndbd] INFO -- AutomaticThreadConfig = 1, NumCPUs = 14
2025-08-27 12:55:28 [ndbd] INFO -- Use automatic thread configuration
2025-08-27 12:55:28 [ndbd] INFO -- Auto thread config uses:
6 LDM+Query threads,
4 tc threads,
1 main threads,
0 rep threads,
2 recv threads,
1 send threads
2025-08-27 12:55:28 [ndbd] INFO -- Automatic Thread Config: LockExecuteThreadToCPU: => parsed: main,ldm,ldm,ldm,ldm,ldm,ldm,recv,recv,tc,tc,tc,tc,send
2025-08-27 12:55:28 [ndbd] INFO -- MaxNoOfTriggers set to 200000
2025-08-27 12:55:28 [ndbd] INFO -- Capped BatchSizePerLocalScan to 162 from 384 to avoid very large memory allocations, still possible to set MaxNoOfLocalScans explicitly to go higher
2025-08-27 12:55:28 [ndbd] INFO -- reservedOperations: 12000, reservedLocalScanRecords: 16, NODE_RECOVERY_SCAN_OP_RECORDS: 666
2025-08-27 12:55:28 [ndbd] INFO -- Set not active nodes
2025-08-27 12:55:28 [ndbd] INFO -- Set LocationDomainId's
2025-08-27 12:55:28 [ndbd] INFO -- Automatic Memory Configuration start
2025-08-27 12:55:28 [ndbd] INFO -- num_table_objects: 20312, num_attributes: 500009
2025-08-27 12:55:28 [ndbd] INFO -- num_triggers: 200000, num_replica_records: 121872
2025-08-27 12:55:28 [ndbd] INFO -- num_tables: 17882, num_ordered_indexes: 128
2025-08-27 12:55:28 [ndbd] INFO -- num_unique_hash_indexes: 2300, num_fragments: 20310
2025-08-27 12:55:28 [ndbd] INFO -- num_tot_fragments: 121860, num_replicas: 1
2025-08-27 12:55:28 [ndbd] INFO -- DICT Schema Memory 102 MBytes
2025-08-27 12:55:28 [ndbd] INFO -- DICT Attribute record size: 96
2025-08-27 12:55:28 [ndbd] INFO -- DICT Trigger record size: 120
2025-08-27 12:55:28 [ndbd] INFO -- DICT Table record size: 280
2025-08-27 12:55:28 [ndbd] INFO -- DICT Object record size: 88
2025-08-27 12:55:28 [ndbd] INFO -- DICT Key Descriptor size: 520
2025-08-27 12:55:28 [ndbd] INFO -- ACC Schema Memory 55 MBytes
2025-08-27 12:55:28 [ndbd] INFO -- ACC Table record size: 16
2025-08-27 12:55:28 [ndbd] INFO -- ACC Fragment record size: 464
2025-08-27 12:55:28 [ndbd] INFO -- LQH Schema Memory 94 MBytes
2025-08-27 12:55:28 [ndbd] INFO -- LQH Table record size: 112
2025-08-27 12:55:28 [ndbd] INFO -- LQH Fragment record size: 704
2025-08-27 12:55:28 [ndbd] INFO -- TUP Schema Memory 481 MBytes
2025-08-27 12:55:28 [ndbd] INFO -- TUP Table record size: 848
2025-08-27 12:55:28 [ndbd] INFO -- TUP Fragment record size: 736
2025-08-27 12:55:28 [ndbd] INFO -- TUP Attribute record size: 104
2025-08-27 12:55:28 [ndbd] INFO -- TUX Schema Memory 31 MBytes
2025-08-27 12:55:28 [ndbd] INFO -- TUX Table Memory 10 MBytes
2025-08-27 12:55:28 [ndbd] INFO -- TUX Fragment Memory 9 MBytes
2025-08-27 12:55:28 [ndbd] INFO -- TUX Attribute Memory 12 MBytes
2025-08-27 12:55:28 [ndbd] INFO -- TUX Table record size: 88
2025-08-27 12:55:28 [ndbd] INFO -- TUX Fragment record size: 80
2025-08-27 12:55:28 [ndbd] INFO -- TUX Attribute record size: 26
2025-08-27 12:55:28 [ndbd] INFO -- TC Schema Memory 19 MBytes
2025-08-27 12:55:28 [ndbd] INFO -- TC Table record size: 208
2025-08-27 12:55:28 [ndbd] INFO -- TC Trigger record size: 40
2025-08-27 12:55:28 [ndbd] INFO -- SPJ Table record size: 8
2025-08-27 12:55:28 [ndbd] INFO -- DIH Schema Memory 215 MBytes
2025-08-27 12:55:28 [ndbd] INFO -- DIH Table record size: 4424
2025-08-27 12:55:28 [ndbd] INFO -- DIH Fragment record size: 80
2025-08-27 12:55:28 [ndbd] INFO -- DIH Replica record size: 168
2025-08-27 12:55:28 [ndbd] INFO -- DIH File record size: 40
2025-08-27 12:55:28 [ndbd] INFO -- DIH Page record size: 8196
2025-08-27 12:55:28 [ndbd] INFO -- DIH ZPAGEREC: 12732
2025-08-27 12:55:28 [ndbd] INFO -- PGMAN Schema Memory 10 MBytes
2025-08-27 12:55:28 [ndbd] INFO -- PGMAN Table record size: 12
2025-08-27 12:55:28 [ndbd] INFO -- PGMAN Fragment record size: 72
2025-08-27 12:55:28 [ndbd] INFO -- SUMA Schema Memory 36 MBytes
2025-08-27 12:55:28 [ndbd] INFO -- SUMA Table record size: 48
2025-08-27 12:55:28 [ndbd] INFO -- SUMA Subscription record size: 136
2025-08-27 12:55:28 [ndbd] INFO -- SUMA Subscriber record size: 24
2025-08-27 12:55:28 [ndbd] INFO -- SUMA DataBuffer record size: 68
2025-08-27 12:55:28 [ndbd] INFO -- Table memory 375 MBytes
2025-08-27 12:55:28 [ndbd] INFO -- Fragment memory 268 MBytes
2025-08-27 12:55:28 [ndbd] INFO -- Attribute memory 343 MBytes
2025-08-27 12:55:28 [ndbd] INFO -- Trigger memory 25 MBytes
2025-08-27 12:55:28 [ndbd] INFO -- Fragment map size 3 MBytes
2025-08-27 12:55:28 [ndbd] INFO -- Backup Schema Memory 260 MBytes
2025-08-27 12:55:28 [ndbd] INFO -- Backup Table Memory 23 MBytes
2025-08-27 12:55:28 [ndbd] INFO -- Backup Fragment Memory 22 MBytes
2025-08-27 12:55:28 [ndbd] INFO -- Backup Trigger Memory 16 MBytes
2025-08-27 12:55:28 [ndbd] INFO -- Backup Delete LCP File Memory 6 MBytes
2025-08-27 12:55:28 [ndbd] INFO -- Backup Table record size: 200
2025-08-27 12:55:28 [ndbd] INFO -- Backup Fragment record size: 32
2025-08-27 12:55:28 [ndbd] INFO -- Backup Trigger record size: 48
2025-08-27 12:55:28 [ndbd] INFO -- Backup DeleteLcpFile record size: 56
2025-08-27 12:55:28 [ndbd] INFO -- TUP Trigger record size: 128
2025-08-27 12:55:28 [ndbd] INFO -- Reserved SchemaMemory is 169 MBytes
2025-08-27 12:55:28 [ndbd] INFO -- Reserved BackupSchemaMemory is 65 MBytes
2025-08-27 12:55:28 [ndbd] INFO -- Reserved ReplicationMemory is 48 MBytes
2025-08-27 12:55:28 [ndbd] INFO -- Reserved TransactionMemory is 885 MBytes
2025-08-27 12:55:28 [ndbd] INFO -- Reserved and fixed Redo log buffer size total are 192 MBytes
2025-08-27 12:55:28 [ndbd] INFO -- Reserved and fixed Undo log buffer is 144 MBytes
2025-08-27 12:55:28 [ndbd] INFO -- Reserved and fixed LongMessageBuffer is 176 MBytes, (not in Global Memory)
2025-08-27 12:55:28 [ndbd] INFO -- Reserved Send buffer size is 45 MBytes
2025-08-27 12:55:28 [ndbd] INFO -- Reserved Job buffer size is 50 MBytes
2025-08-27 12:55:28 [ndbd] INFO -- Computed Static overhead is 249 MBytes, (not in Global Memory)
2025-08-27 12:55:28 [ndbd] INFO -- Computed OS overhead is 13453 MBytes
2025-08-27 12:55:28 [ndbd] INFO -- Computed Backup Page memory is 331 MBytes, (not in Global Memory)
2025-08-27 12:55:28 [ndbd] INFO -- Computed Restore memory is 52 MBytes
2025-08-27 12:55:28 [ndbd] INFO -- Computed Packed signal memory is 92 MBytes
2025-08-27 12:55:28 [ndbd] INFO -- Computed NDBFS memory is 32 MBytes
2025-08-27 12:55:28 [ndbd] INFO -- Computed Table memory is 375 MBytes, (not in Global Memory)
2025-08-27 12:55:28 [ndbd] INFO -- SharedGlobalMemory is 1679 MBytes
2025-08-27 12:55:28 [ndbd] INFO -- Total memory is 128217 MBytes
2025-08-27 12:55:28 [ndbd] INFO -- Used memory is 18040 MBytes
2025-08-27 12:55:28 [ndbd] INFO -- Remaining memory is 110176 MBytes
2025-08-27 12:55:28 [ndbd] INFO -- Page entry size per page is 1200 bytes
2025-08-27 12:55:28 [ndbd] INFO -- Setting DataMemory to 99158 MBytes
2025-08-27 12:55:28 [ndbd] INFO -- Setting DiskPageBufferMemory to 10628 MBytes
2025-08-27 12:55:28 [ndbd] INFO -- 389 MBytes used for Page Entry objects
2025-08-27 12:55:28 [ndbd] INFO -- Automatic Memory Configuration done
2025-08-27 12:55:28 [ndbd] INFO -- NDBMT: MaxNoOfExecutionThreads=14
2025-08-27 12:55:28 [ndbd] INFO -- NDBMT: ldm_threads=6 ldm_workers=6 query_workers=13
tc_threads=4 tc_workers=4 send=1 receive=2 main_threads=1
2025-08-27 12:55:28 [ndbd] INFO -- RonDB -- DB node 1
2025-08-27 12:55:28 [ndbd] INFO -- RonDB-24.10.8 --
2025-08-27 12:55:28 [ndbd] INFO -- Memory Allocation for global memory pools Starting
2025-08-27 12:55:28 [ndbd] INFO -- numa_set_interleave_mask(numa_all_nodes) : no numa support
2025-08-27 12:55:28 [ndbd] INFO -- SharedGlobalMemory set to 1679 MB
2025-08-27 12:55:28 [ndbd] INFO -- Reserved and fixed DataMemory set to 99158 MB
2025-08-27 12:55:28 [ndbd] INFO -- Reserved and fixed RedoLogBuffer uses 196 MB
2025-08-27 12:55:28 [ndbd] INFO -- Job buffers use up to 201 MB
2025-08-27 12:55:28 [ndbd] INFO -- Send buffers use up to 90 MB, can overallocate 45 MB more using SharedGlobalMemory.
2025-08-27 12:55:28 [ndbd] INFO -- Reserved and fixed DiskPageBuffer uses 10682 MB
2025-08-27 12:55:28 [ndbd] INFO -- SchemaTransactionMemory uses 4 MB
2025-08-27 12:55:28 [ndbd] INFO -- Reserved TransactionMemory set to 885 MB
2025-08-27 12:55:28 [ndbd] INFO -- Adding 144 MBytes to TransactionMemory for Undo Buffer
2025-08-27 12:55:28 [ndbd] INFO -- TransactionMemory can expand and use SharedGlobalMemory if required until 92% used
2025-08-27 12:55:28 [ndbd] INFO -- QueryMemory can use memory from SharedGlobalMemory until 88% used
2025-08-27 12:55:28 [ndbd] INFO -- Adding 48 MByte for replication memory
2025-08-27 12:55:28 [ndbd] INFO -- MaxBufferedEpochBytes can use memory from SharedGlobalMemory until 96% used
2025-08-27 12:55:28 [ndbd] INFO -- Reserved 169 MByte for SchemaMemory
2025-08-27 12:55:28 [ndbd] INFO -- SchemaMemory can expand and use SharedGlobalMemory if required until 94% used
2025-08-27 12:55:28 [ndbd] INFO -- Adding 65 MByte for BackupSchemaMemory
2025-08-27 12:55:28 [ndbd] INFO -- BackupSchemaMemory can expand and use SharedGlobalMemory if required until 96% used
2025-08-27 12:55:28 [ndbd] INFO -- Total sum of all pages in Global Memory is 3620110, 113128 MBytes
The most important parameters that affects memory calculations are the following:
-
The number of CPUs
-
The number of replicas
-
PartitionsPerNode -
The number of table objects
-
The number of nodes in the cluster
-
MaxNoOfConcurrentOperations -
OsCpuOverhead -
OsStaticOverhead
There are more parameters that can be affect the memory calculations,
but mostly the defaults should be good enough. The number of CPUs
affects the buffers used for communication between threads, but also
parts of the metadata is replicated in the ldm threads.
Changing PartitionsPerNode means more partitions in each table and
thus considerably more fragment records, thus affecting the
SchemaMemory. NoOfReplicas also affect the number of fragments, but
also the replication records in DIH. NoOfReplicas is always set to 3
in our Kubernetes framework, this enables us to increase and decrease
the number of replicas in the RonDB cluster.
The number of table objects (sum of MaxNoOfTables,
textttMaxNoOfOrderedIndexes, MaxNoOfUniqueHashIndexes) is directly
affecting the amount of SchemaMemory in the node. The default settings
means we can have 20300 table objects, this can be increased using the
MaxNoOfSchemaObjects configuration parameter.
Supporting large transactions can be done by changing
MaxNoOfConcurrentOperations, this will however require more
TransactionMemory.
OsStaticOverhead and OsCpuOverhead is mainly intended when you want
to avoid using a part of the memory to give other processes running on
the same VM a chance to also use a bit of the memory. By default in the
above setup the RonDB would avoid using 4550 MBytes of the memory that
the OS makes available. This is calculated as 1400 MBytes plus 100
MBytes per CPU and finally 1.5% of the available memory.
Setting TotalMemoryConfig will mean that no memory is saved for OS
overhead.
History of Memory management in RonDB#
RonDB is based on NDB, and NDB was developed on top of a model where all modules handled their own memory. This memory mostly consisted of arrays of structs. The internal memory references used indexes in those arrays.
Thus to map to a real memory address we needed the start of the array and the index. This was translated using macros that also efficiently checked that all accesses were within the array, thus validating every access of each data structure in NDB.
This model was very CPU efficient, leading to a very good performance of NDB Cluster. However it also meant that hundreds of arrays had to be configured and the memory became inflexible. This lead to overcommitting many memory resources.
This started to change around 2012 and with RonDB the process has completely changed. Currently there is no longer any memory that requires configuration, and any arrays not handled by these dynamic memory structures and still using fixed size arrays, have hard-coded sizes that are known to work for the use cases of RonDB.
All major memory regions are now handled by a global memory manager. The architecture still uses an index in an array to access our data structures. But now the arrays are implemented using dynamic arrays that allow holes in the arrays, and memory freed from one array can soon be reused by another array.
This increase in the memory management’s flexibility also means that less memory requires to be allocated in general or that more memory can be used for storing the actual data of the application.
RonDB has many different internal data structures to handle memory. Most of the time RonDB allocates memory of a C++ struct. We have fixed size ArrayPools, short term memory using TransientPools and more long term storage using RWPool and RWPool64. These use templates that will check that each access of a struct is an allocated, thus checking the validity of the memory both by checking that index is within limits and that the magic number of the struct is the correct one.
Lately RonDB also added a normal malloc interface connected to the various regions that can be used to allocate memory sizes of up to 1 MByte.
DiskPageBufferMemory, DataMemory, SendBufferMemory and JobBuffer allocates pages that are 32 kByte in size in RonDB. All the memory in the global memory manager is maintained per 32 kByte page.
Allocation and deallocation from the global pools happens in sets of pages most of the time. These allocations are maintained per thread, thus avoiding mutex contentions on the memory allocator.