Globally Distributed RonDB#
In this chapter we will describe a scenario where RonDB is used to implement a globally distributed database with a set of clusters that can even be on different continents.
This scenario supports updates made in any cluster, thus it is a multi-primary solution on a global scale. The problem with this scenario is that the latency to detect conflicting updates is on the order of a second for a truly global case due to the speed of light.
In a truly globally distributed database it is not a good idea to use strong consistency as we do internally in one cluster in RonDB. We need to use a model for eventual consistency. So we could have conflicting updates in this setup.
It is still a good idea to limit the possibility of conflicts by routing queries and transactions to clusters dependent on the data to be read or written. The responsibility of this is on the application.
The ideas for a globally distributed database does not cover cases where we support transactional consistency on a global scale. The latency in a globally distributed database makes that not tractable.
Instead we solve the problem on a row-by-row basis.
RonDB does support a transactionally consistent method, this is only intended for short duration where we have network partitioning or are performing a switchover from one cluster to another or extremely rare conflicts. We will cover this in the next chapter.
The question is how to handle conflicts that will occur in such a setup.
RonDB supports a number of ways to handle conflicts.
-
Most recently updated wins (Automated conflict resolution)
-
Conflicts require manual resolution
-
Primary cluster wins (Automated conflict resolution)
NDB$MAX_DELETE_WIN(column_name)#
This option is to have a simple decision based on a value of a specific column that acts as a timestamp. The update with the highest timestamp or value of this column will win. This requires adding such a timestamp column to each table that requires conflict detection. Decision is done on a row level.
The timestamp column is updated by the user and maintained by the application developers.
The conflict logic is very simple, when a replication event for an update comes and there is an existing row already, the update will be applied if the value of this column is higher than the value in the existing row. If it is not higher, a conflict occurred and the update or write is not applied. The conflict is logged in an exceptions table (explained later in this chapter) if one exists.
This is by far the simplest conflict handling function. The user need to ensure that the timestamp column is properly set and deletes must be handled with care. The conflicts are automatically resolved, the conflicts can in parallel be logged to an exceptions table.
There is no special significance in this scheme for where the update comes from. All clusters are equal in priority. Thus we can have any number of clusters in this setup and they can be organised in a lot of different configurations.
Insert-Insert conflicts#
If an insert is replicated into a cluster where the row already exists we have a conflict. This is a bit special, Insert-Insert conflicts should always be worked around. One manner this can be done in MySQL is using autoincrement functionality where different clusters will never generate the same key.
Delete-Delete conflicts#
A delete in this case is treated as if the timestamp column is always higher than the existing row. Thus deletes will always succeed.
There is also an old variant called NDB$MAX(column_name) that treats deletes as if they always have a lower timestamp column compared to the existing one. Thus deletes never succeeds. We don’t recommend using this variant.
NDB$OLD(column_name)#
When checking if an update is in conflict using NDB$OLD(column_name) we get the before value of the row from the updating cluster, we get the current value of the row from our cluster. If those two values differ we have a conflict.
This conflict handling function doesn’t automatically perform conflict resolution. It is expected that the application have defined an exceptions table and that the application uses this table to resolve the conflicts.
As an example if the row version is 2 and now both Cluster A and Cluster B wants to update the row to version 3. Thus both clusters will have a success in executing this change in their own cluster. When the replication event arrives in the other cluster both those events will see a conflict. Both clusters will have a logged entry in the exceptions table. The end result of these two transactions is that the clusters have different data. The application logic using the information in the exceptions table is required to bring the database back into a consistent state.
To use NDB$OLD(column_name) without defining any exceptions table doesn’t make sense.
NDB$OLD(column_name) can be used in many different replication configurations. It can be used in circular replication setups with more than two clusters involved.
Insert-Insert conflicts#
If an insert is replicated into a cluster where the row already exists we have a conflict. The before value in this case is NULL, it is clearly different from whatever value we are inserting in the timestamp column.
Update-Update conflicts#
In this case we have a before value from the originating cluster and the row to be updated have a value in the current cluster updated. If these values are the same no updates have interfered and caused any conflict. If the values differs it means that some other update successfully changed the row in this cluster and thus we have a conflict.
Delete-Delete conflicts#
If we are trying to delete and find that the row is already deleted, we can deduce that the value of the column have changed and thus we have a conflict.
NDB$EPOCH2#
The previous conflict detection function only uses a special column set by the application to deduce whether conflict occurs or not. NDB$EPOCH2 discovers conflicts based on a timestamp generated by RonDB internally through our epoch based timestamps. If epochs are generated at intervals of 100 milliseconds we get a conflict window that is 200 millisecond for a circle of two clusters.
Now NDB$EPOCH2 uses a Active-Standby approach. There is always one primary cluster and the rest of the clusters are secondary clusters. Updates applied in the Active cluster, the primary cluster, cannot conflict. Only updates that originates in a secondary cluster can be in conflict. Thus the rule is that the primary wins all conflicts.
NDB$EPOCH2 can only be used with two clusters, one acting in the role as primary cluster and one acting in the role as secondary cluster.
NDB$EPOCH2 is still a row-based conflict detection mechanism. Thus only the rows that conflict are affected by the conflict detection.
There is an older variant called NDB$EPOCH, this doesn’t handle delete conflicts properly. This is solved in NDB$EPOCH2 by keeping track of deleted rows for some time before removing them completely. There should be no need to use the NDB$EPOCH method any more.
Conflict detection tables#
Before conflict detection can be activated we must create a number of tables to handle conflict detection. It is mandatory for NDB$EPOCH2 since the existence of an exception causes a number of extra hidden columns to be added to the table when created. The exceptions table must always be created before the table itself is created.
For NDB$OLD(column_name) there is no practical use without it. For NDB$MAX_DELETE_WIN(column_name) it is optional to create an exceptions table.
These tables should all be defined as using the NDB storage engine.
Exceptions tables#
If the name of the user table is my_example_table, the table name of the table that stores the conflicts must be named my_example_table$EX. A $EX is added at the end of the table name. The table and the exceptions table should be in the same database.
This table have four mandatory columns that are defined first. It is strongly recommended to call those NDB$server_id, NDB$source_server_id, NDB$source_epoch and NDB$count. The server id is the id of the MySQL replication server where the conflict was detected. The source server id is the server id where the conflicting operation was inserted into the binlog and source epoch is the epoch number that was used when this was inserted into the binlog. The count is a simple counter to ensure that each conflict is a unique entry in the exceptions table. These four columns are the primary key of the exceptions table.
Next we have three optional columns, the first one is called NDB$OP_TYPE. This is an ENUM that lists the operation type of the conflict. It can be either of WRITE_ROW, UPDATE_ROW, DELETE_ROW, REFRESH_ROW and READ_ROW.
The second is another ENUM that lists the cause of the conflict. It can be any of ROW_DOES_NOT_EXIST, ROW_ALREADY_EXISTS, DATA_IN_CONFLICT, TRANS_IN_CONFLICT. It is called NDB$CFT_CAUSE. TRANS_IN_CONFLICT can only occur in the NDB$EPOCH2_TRANS method we will discuss in the next chapter.
The third is a BIGINT that is unsigned. This column is called NDB$ORIG_TRANSID. It is a 64-bit value and represents the transaction id in the originating cluster. This is only interesting for conflict handling using transactions that we will discuss in the next chapter.
Now after those optional columns we need to list the primary key columns in the order they are created in the original table. They should use the same data type in the exceptions table as in the original table.
Now for each column in the table that isn’t a primary key one can define an additional 2 columns. The first is the original column value ($OLD). The second is the after value of this column ($NEW).
Now let us show an example. We have a table defined as below:
CREATE TABLE test.my_example_table (
pk int unsigned not null,
data varchar(255) not null,
) ENGINE=NDB;
In this example we only want to use a simple conflict detection based on the row value. Thus no need for the transaction id in the conflict table.
We define the exceptions table as:
CREATE TABLE test.my_example_table$EX (
NDB$server_id int unsigned,
NDB$source_server_id int unsigned,
NDB$source_epoch bigint unsigned,
NDB$count int unsigned,
NDB$OP_TYPE ENUM ('WRITE_ROW', 'UPDATE_ROW', 'DELETE_ROW',
'REFRESH_ROW', 'READ_ROW'),
NDB$CFT_CAUSE ENUM ('ROW_DOES_NOT_EXIST', 'ROW_ALREADY_EXIST',
'DATA_IN_CONFLICT', 'TRANS_IN_CONFLICT'),
pk int unsigned not null,
data$OLD varchar(255) not null,
data$NEW varchar(255) not null,
PRIMARY KEY (NDB$server_id,NDB$source_server_id,
NDB$source_epoch,NDB$count)
) ENGINE=NDB;
Now equipped with this information about a row conflict the application developer can write code that uses data from the exceptions table to resolve the conflict.
The primary key of the exceptions table are mandatory columns. At least a part of the primary key of the table is mandatory. The remainder of the columns are optional. What columns that are stored in the exceptions table depends on what is needed to resolve the conflicts. This is defined by the users requirements and thus these columns are optional all of them.
ndb_replication table#
To setup conflict detection handling we need a row in the ndb_replication table. The columns in this table was presented earlier. To use conflict detection we need to have an entry in this table for each table involved in conflict detection (one row can handle multiple tables).
The binlog_type column should contain a 7. Thus updates are logged as updates and thus the entire before and after image is logged. This setting is used with NDB$OLD(column_name), NDB$MAX_DELETE_WIN(column_name).
The column conflict_fn contains the selected conflict function. The ones that we should select are either of: NDB$OLD(column_name), NDB$MAX_DELETE_WIN(column_name), NDB$EPOCH2, NDB$EPOCH2_TRANS (handled in the next chapter).
The server id in this table should be set to 0 to ensure that all MySQL replication servers in the cluster handle conflict detections.
Setup for circular replication#
The setup for circular replication is very similar to setting up a primary and standby replication channel.
IGNORE_SERVER_IDS#
The first major difference is that circular replication means that the changes in one cluster will eventually return to the cluster. In MySQL replication this is handled by checking the originating server id of a transaction to be applied, if the server id is our own id we will ignore the transaction since it originated in the MySQL Server we’re in and thus is already in the database.
Now with RonDB we need to check that the originating server id isn’t in the list of server ids used by MySQL replication servers in the cluster.
We show an example here. In the figure below we have a cluster A with four MySQL replication servers with server ids 1 through 4. We have a cluster B with four MySQL replication servers with server ids 5 through 8. Cluster C also have four MySQL replication servers with server id 9 through 12.
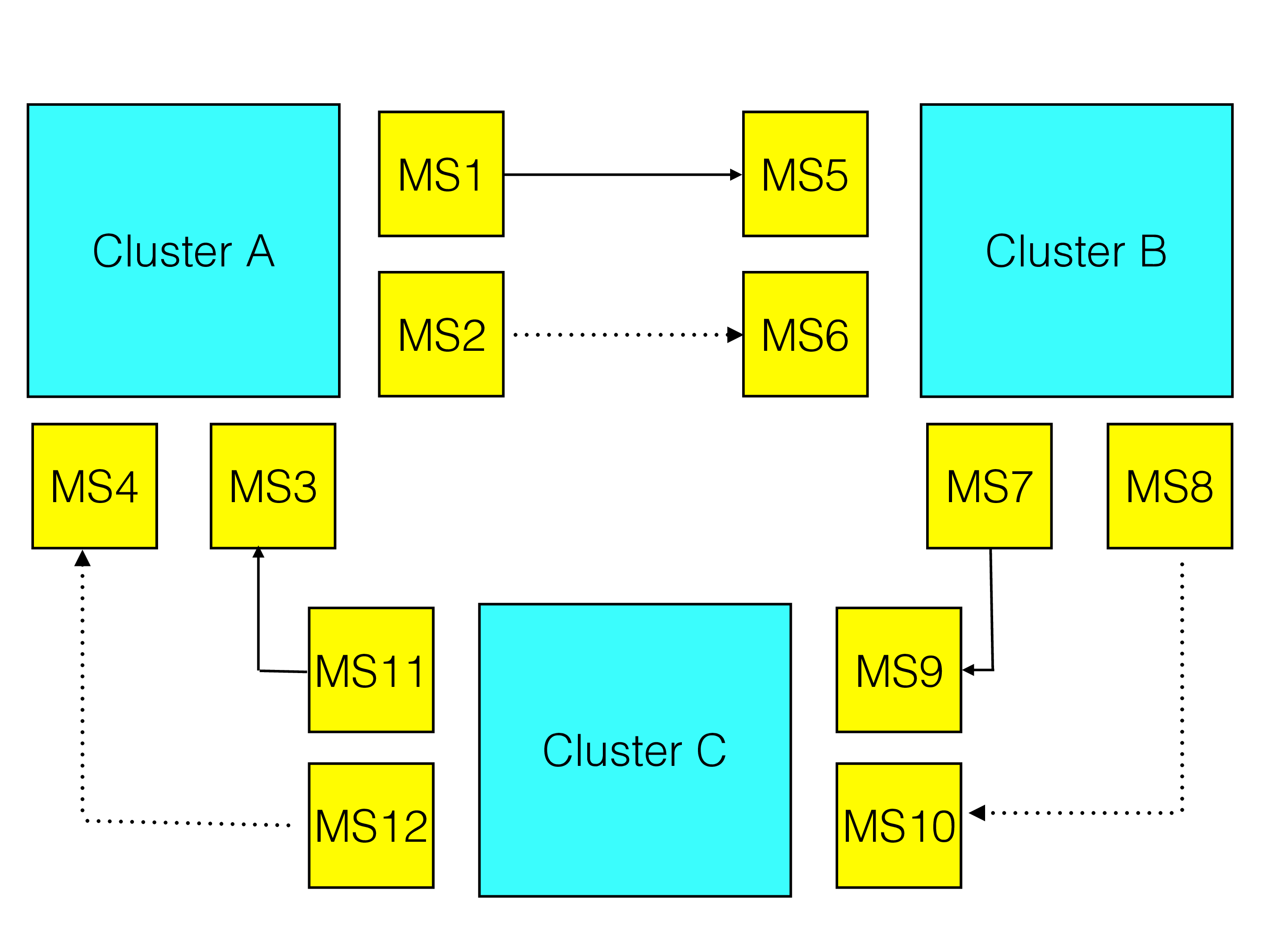
As shown in the figure we have setup a primary replication channel between cluster A and cluster B using MySQL replication servers with server id 1 and 5, the backup replication channel uses server ids 2 and 6.
The cluster B and cluster C has a primary replication channel setup between MySQL replication servers with server id 7 and 9, the backup replication channel use server ids 8 and 10.
Similarly cluster C is connected to cluster A through a primary replication channel between MySQL replication servers with server id 11 and 3, the backup replication channel use server ids 12 and 4.
Thus in cluster A we have two replica appliers, one of which is active at a time. These are using server ids 3 and 4. However the originating server ids is either 1 or 2. Thus we have to add a list of server ids to ignore.
The easiest manner is to simply ignore all MySQL replication servers that is connected to this cluster. When setting up the replica in cluster A for server id 3 and 4 we will use the following CHANGE REPLICATION SOURCE TO command.
In reality one could have settled for server id 1 and 2. But setting it to 3 and 4 means that we are prepared if we start using those servers as binlog servers as well.
CHANGE REPLICATION SOURCE TO
SOURCE_HOST='source_host',
SOURCE_PORT=source_port,
SOURCE_USER='replica_user',
SOURCE_PASSWORD='replica_password',
SOURCE_LOG_FILE=@file,
SOURCE_LOG_POS=@pos,
IGNORE_SERVER_IDS(1,2,3,4);
This command will ensure that the replica applier will break all cycles by avoiding to accept any replication events that originated from server ids 1 through 4.
The other replicas in this example requires a similar CHANGE REPLICATION SOURCE TO command, listing the server ids present in their cluster.
ndb-log-orig#
By default the ndb-log-orig option in the MySQL Server isn’t set. If a MySQL Server is used to write the binlog in a circular replication setup for RonDB it is essential that this variable is set. It ensures that the ndb_binlog_index is updated with one entry for each epoch that is propagated from other clusters to this cluster in addition to the entry for the part of the epoch originating in this cluster.
Thus if for example we have 3 clusters in a circular replication we will have 3 entries per epoch in each MySQL replication server that writes the binlog.
log-replica-updates#
In a circular replication setup we must set the option log-replica-updates on all MySQL Servers acting as binlog servers. Thus on server id 1,2,7,8,11 and 12 in the above example.
ndb-log-apply-status#
In a circular replication using conflict detection we need to see the full view of all cluster’s apply status. To handle this we will replicate any changes to the ndb_apply_status table, they will be logged with the same data except that the originating server id will be changed into the server id that writes the binlog in the replicating cluster.
Thus it is very important to ensure that this option is set in all binlog servers in the circular replication setup.
ndb-log-update-as-write#
When not using conflict detection it is recommended to use writes for updates to make the updates idempotent. With circular replication channel we should not use writes for updates. Thus we need to set ndb-log-update-as-write to OFF for circular replication setups in all binlog servers.
ndb-log-update-as-minimal#
When using the NDB$EPOCH2 or NDB$EPOCH2_TRANS function it is not necessary to record the entire before image. It is sufficient to record the primary key of the before image and it is enough to record updated columns in the after image. To achieve this behaviour we set the ndb-log-update-as-minimal to ON. This MySQL option should only be used for those two conflict detection setups.
NDB$OLD(column_name) and NDB$MAX_DELETE_WIN(column_name) requires the full before image and it requires updates to be recorded as updates. Therefore this option cannot be set for those conflict detection functions. Normal replication between clusters requires only the changed columns of the updated row and record those as a write row. So one should not use this option for this setup either.
Insert-Insert conflicts#
Two inserts trying to insert the same primary key value will always be treated as if they are in conflict. The conflict will be logged in the conflict detection tables.
Using autoincrement#
Autoincrement have a feature that is intended for insertion into multiple clusters active at the same time. We allocate autoincrements with a certain step between id allocation. The step should be equal to the number of clusters we are using. Next we specify the autoincrement offset, this describes the number of the cluster. Thus if we have 3 clusters they should all have autoincrement step set to 3, the offset they should have is 0, 1 and 2. All MySQL Servers in each cluster should use the same numbers.