Architecture Overview#
This chapter describes the RonDB’s distributed architecture. A typical small cluster setup is illustrated below.
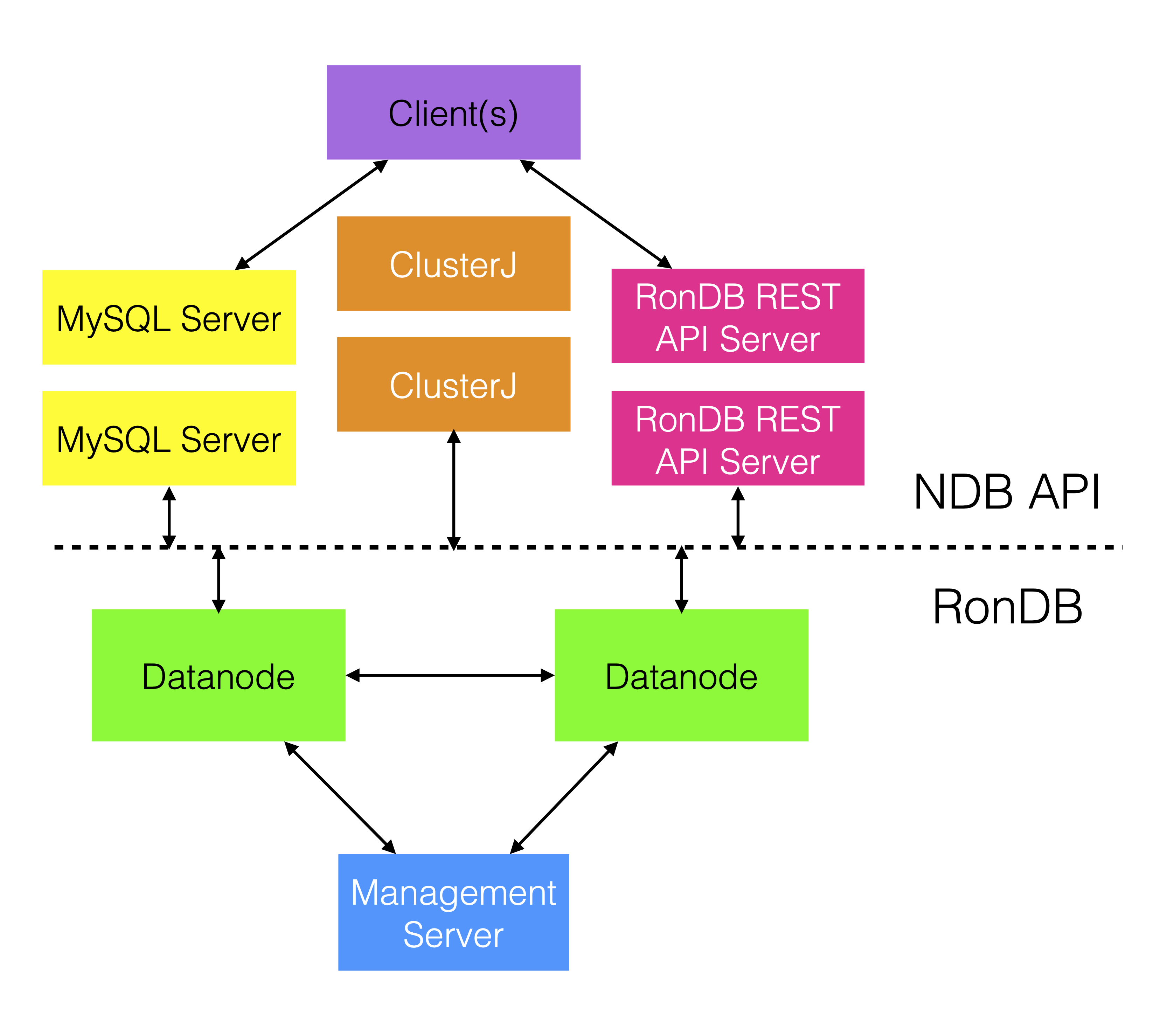
In this architecture, the web client interacts with the Web Server, which queries the MySQL Server. The MySQL Server parses these requests and communicates with data nodes for data retrieval or modification. Additionally, a management server stores the cluster configuration. Upon startup, each node retrieves its configuration from the management server (ndb_mgmd).
Cluster nodes are categorized into three types: data nodes, management servers, and API nodes. Each node, identified by a node id, uses the NDB protocol for communication.
The data node executable, ndbmtd, is a multi-threaded program containing all the data. The management server, ndb_mgmd, is essential for node startup and cluster logging. Once nodes are operational, the management server’s role is primarily for logging, allowing the data and API nodes to function independently even if the management servers are offline.
API nodes vary; the most common is the MySQL Server (mysqld). Other application-specific API nodes use different NDB API variants. The communication between MySQL Server and data nodes is further optimized. The prevalent use case also involves RonDB with MySQL Servers.