Benchmark RonDB using Dolphin PCI Express#
This benchmark shows the impact of using an interconnect with very low latency and very high bandwidth compared to using a standard 10G Ethernet interface. We had access to two x86_64 servers equipped with both a Dolphin PCI Express card and a 10G Ethernet card.
We used the Sysbench setup in 2 configurations. The first configuration uses a single node of each type. This means that we have to pass between the servers for each communication. This gives a good idea of a fully distributed architecture even with more replicas in the cluster. Thus the positive impact of using Dolphin SuperSockets in this environment would be even greater than what we find in those benchmark results.
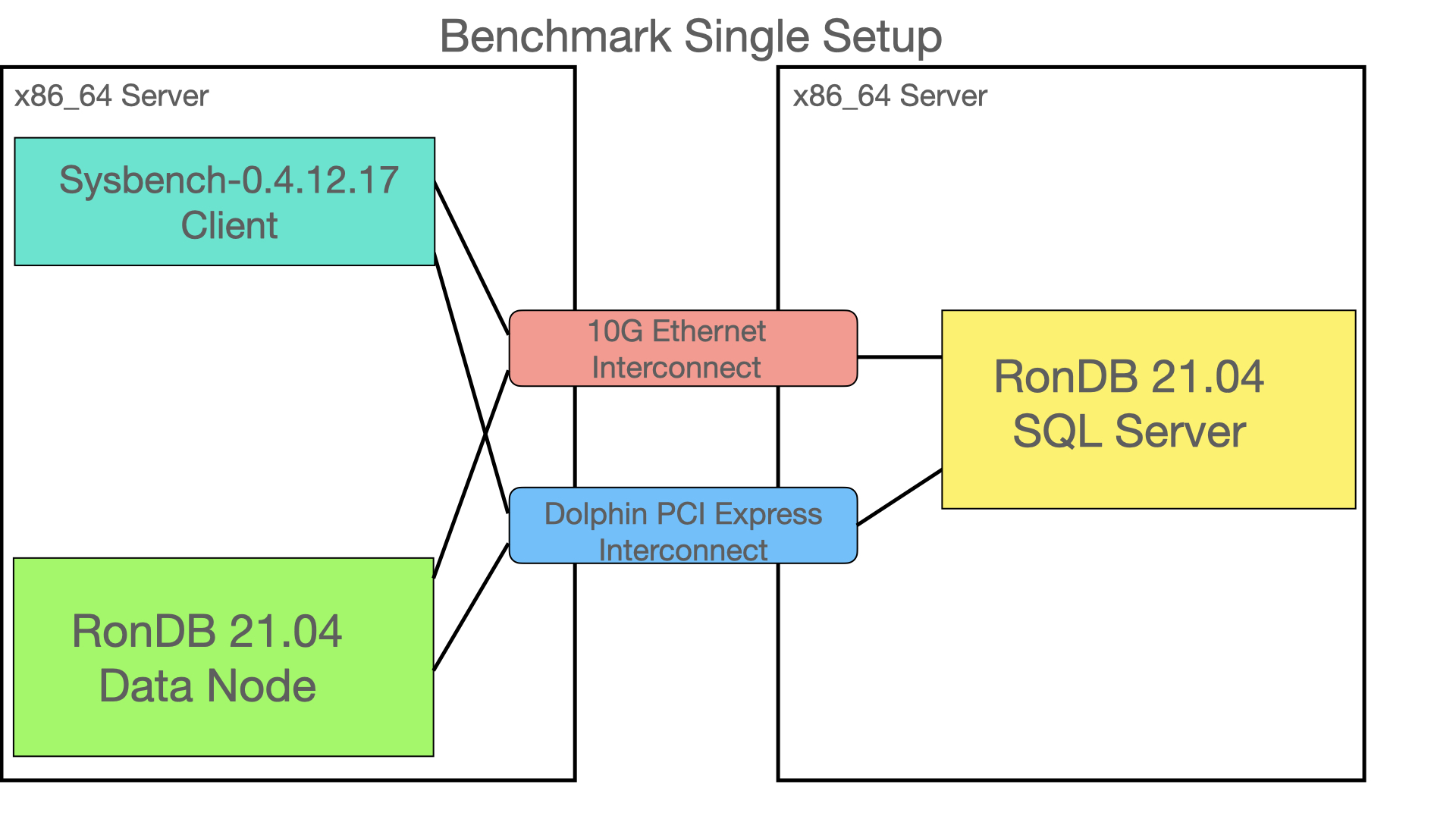
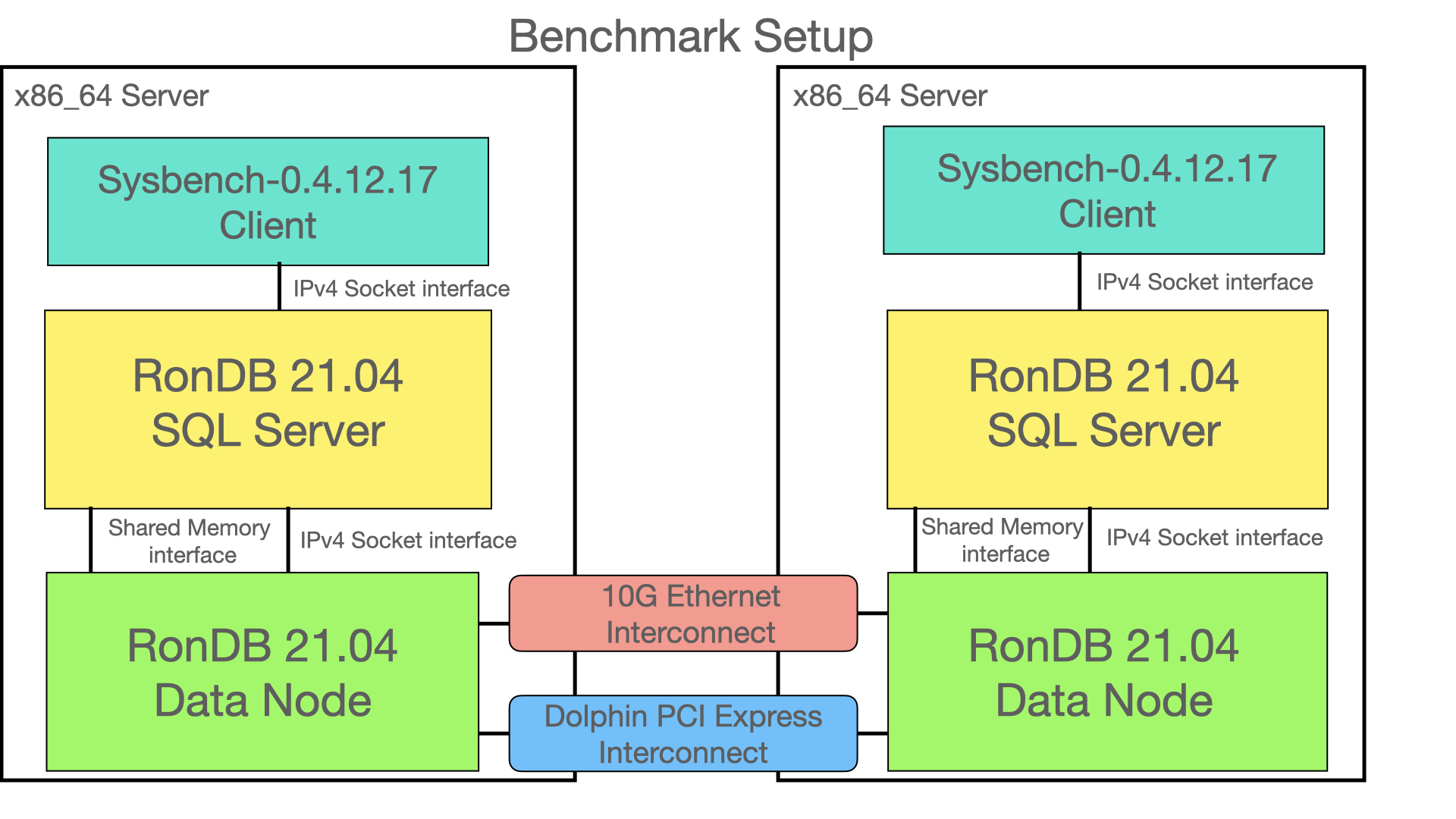
The second setup has two nodes of each type, thus only communication between data nodes will pass between the servers. We tested two cases for communication between MySQL Server and the RonDB data node in this setup. One uses a normal IPv4 socket and the other one uses a shared memory connection when the nodes are in the same server.
This architecture represents a colocated setup where RonDB data nodes is colocated with the MySQL servers and possibly even the application is colocated. In this setup we can improve throughput and latency by using the shared memory transporter for communication between nodes that are located on the same server.
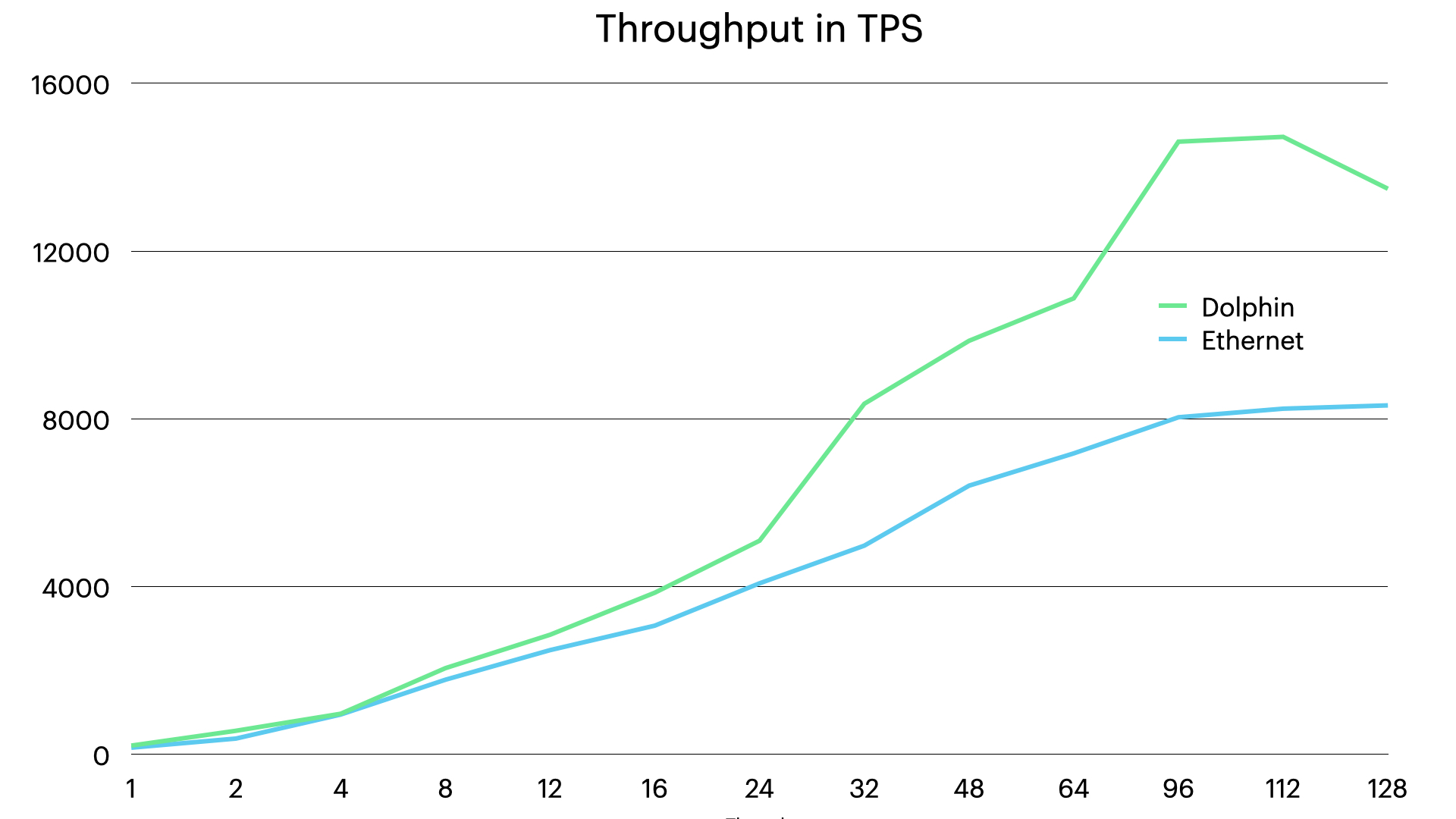
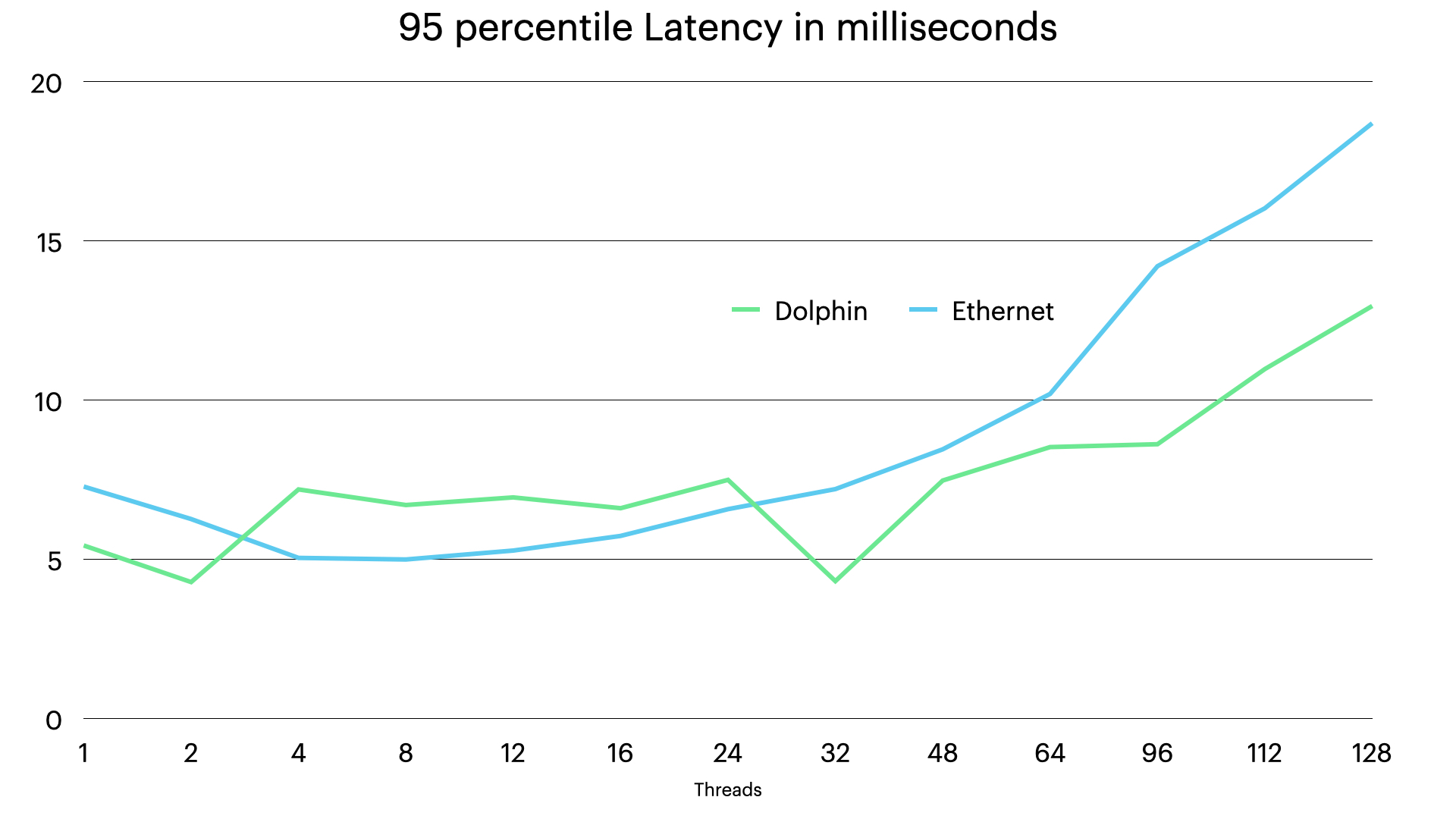
The first benchmark shows the throughput and latency of the setup with single nodes of each type. In these graphs we see immediately the impact of two of the three main reasons why the Dolphin interconnect can bring benefits.
To prepare the discussion I will go through those three reasons.
The first reason is very simple, the Dolphin interconnect has higher bandwidth. In this benchmark setup using Sysbench OLTP RW it is actually not sufficient even with 10G Ethernet. Each transaction in Sysbench OLTP RW consists of 20 SQL queries. There are 10 key lookups, there is two update queries, one insert and one delete query, there is a begin and a commit query and finally there are four range scan queries.
The bandwidth user is mainly the range scan queries. These queries fetches 100 rows each, this means that each such query fetches around 15-20 kBytes of data from RonDB and even more with UTF8 encoding. This means that 10.000 TPS will require transportation of 800 MBytes of user data and with overhead even more. Thus 10G Ethernet sees the upper limit here at around 8300 TPS simply due to lack of bandwidth whereas the Dolphin interconnect simply continues to scale since it can handle around 50 Gbit/second.
In the above figures we start to see the impact of this already at 32 threads and after that it just widens.
The second issue that differentiates the Dolphin interconnect from Ethernet is found in the device driver. The wake up latency is essential to latency in a distributed system. The solution in Dolphin SuperSockets device driver is that there is a single thread that is executing 100% of the time when the communication is active. This can decrease the time for wake up with up to 25 microseconds for each wake up. However there is one problem that we have to deal with here. The OS doesn’t know that this thread needs to always execute for best performance.
Thus to get the best performance we need to lock the Dolphin device driver thread to a specific CPU and ensure that the other processes in the machine stays away from this CPU. In this first benchmark setup we didn’t do that.
This is the reason why we get good numbers at 1-2 threads, but already with 4 threads we see the performance going up and down a bit randomly. A bit dependent on random decisions of where to place the Dolphin device driver thread we get good or bad performance.
The final issue that impacts performance is how much CPU time one needs to spend in the device driver and in the operating system. With a normal IPv4 socket we have to perform calculations of checksums and other tasks that are part of the TCP/IP stack. The Dolphin device driver shortcuts the TCP/IP stack since it handles checksums in the hardware and this makes it very much more efficient. This is not seen in those numbers where the bandwidth and the placement of the Dolpin device driver thread is mostly seen.
Now let’s see the impact of locking the Dolphin device driver thread to a specific CPU and see how this impacts throughput and latency.
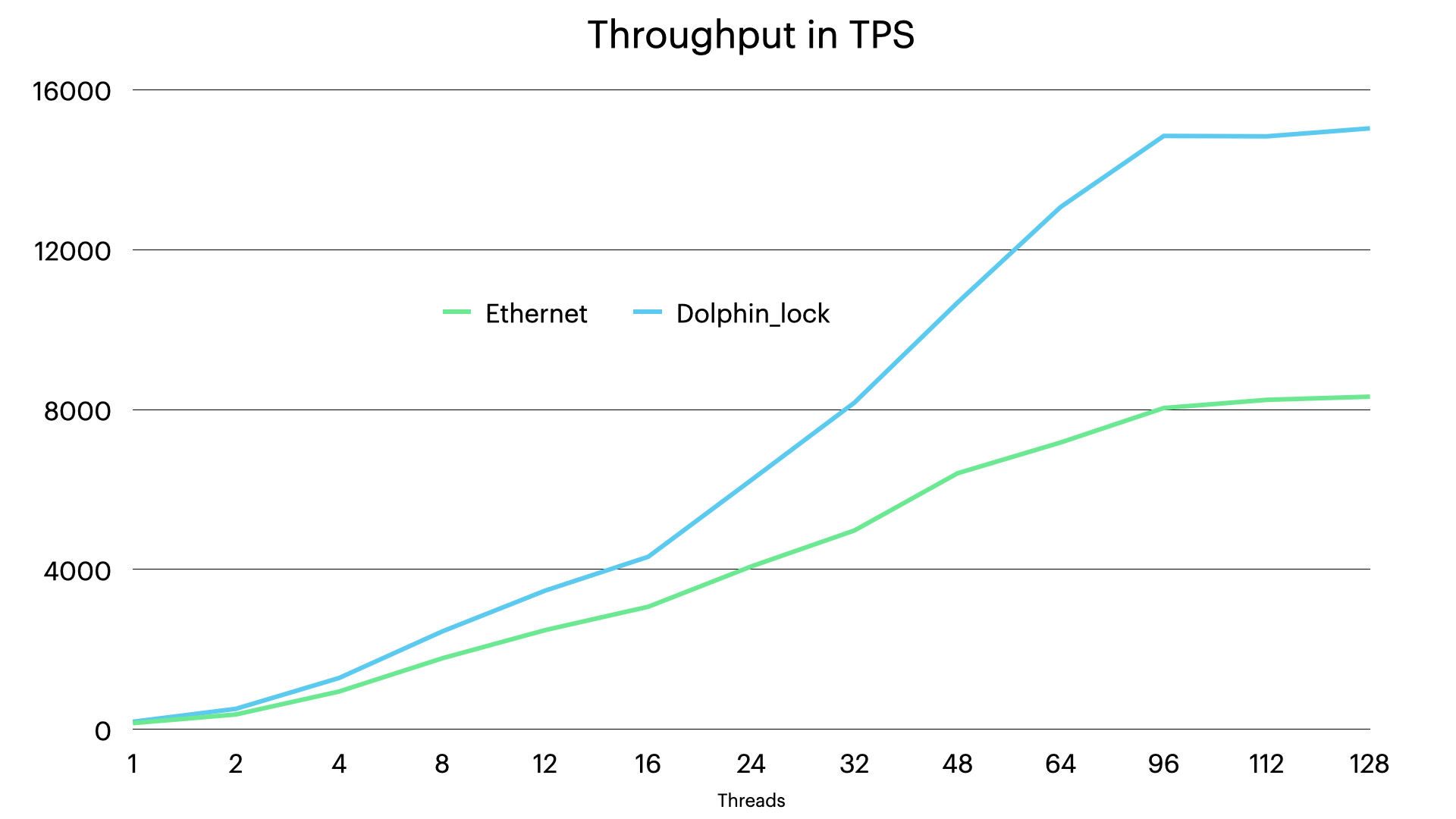
As can be seen the throughput now scales in a linear scale until it reaches a limit where all CPUs are fully at work.
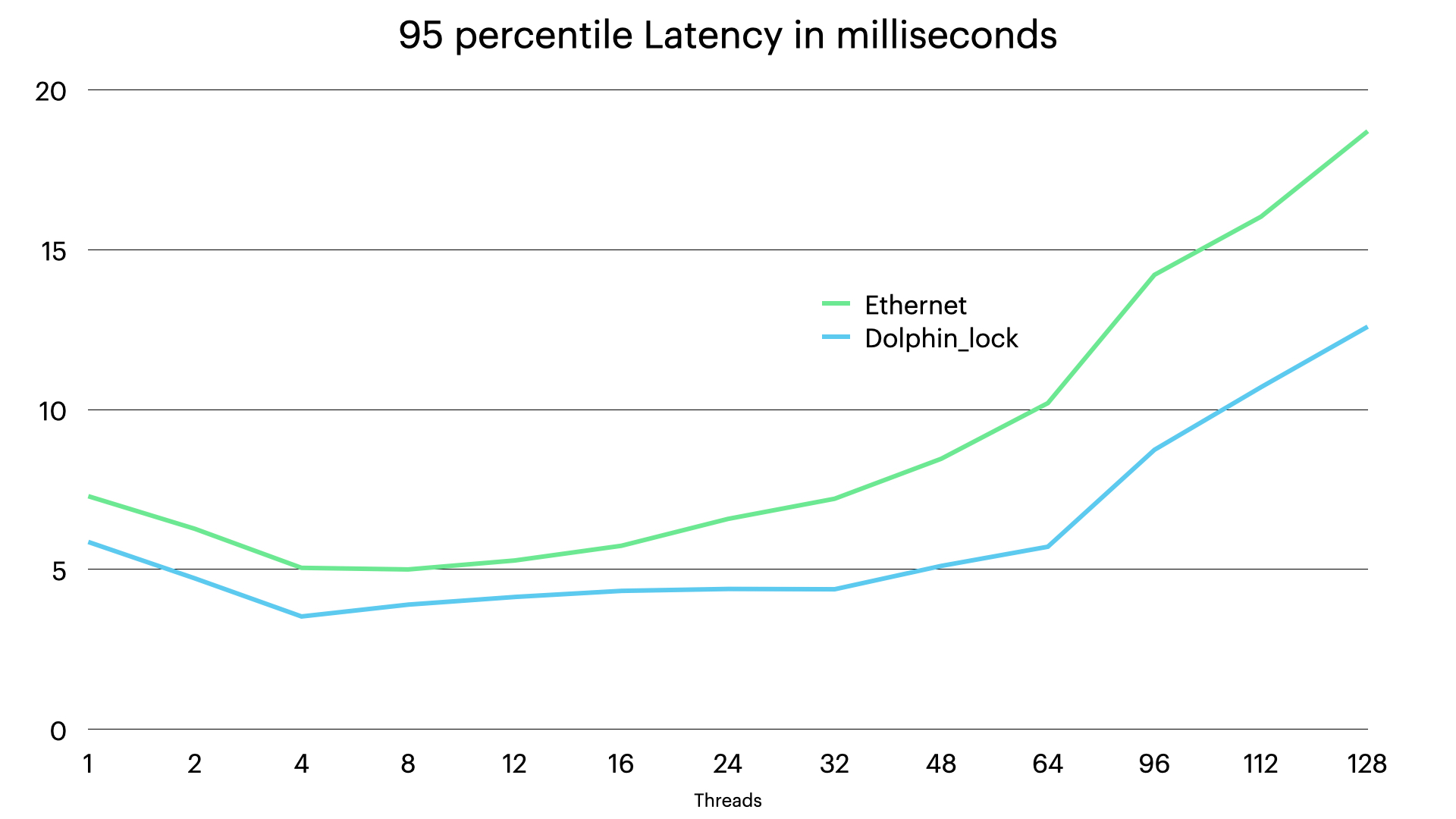
In the latency numbers we see that the latency doesn’t start to increase substantially until the CPUs are fully occupied. Thus latency numbers are very good all the way up to 64 threads. We see a pattern where 1-2 threads have a bit higher latency. The reason for this comes from how wake ups are handled in RonDB.
RonDB has an adaptive CPU spinning, this works in such a way that it measures whether it makes sense to keep CPU spinning by comparing the costs of CPU spinning and comparing them to the gains of CPU spinning. RonDB can be configured with 3 different levels of how aggressive we are in CPU spinning. However with only a single thread it would require extremely aggressive CPU spinning to decrease the latency for those setups. However with 6 milliseconds of latency for the entire transaction we are down at 300 microseconds in latency per SQL query which should be good enough for most applications.
Now the next step is to remove the bandwidth issue from the benchmark to see how the use of CPU time impacts throughput and latency.
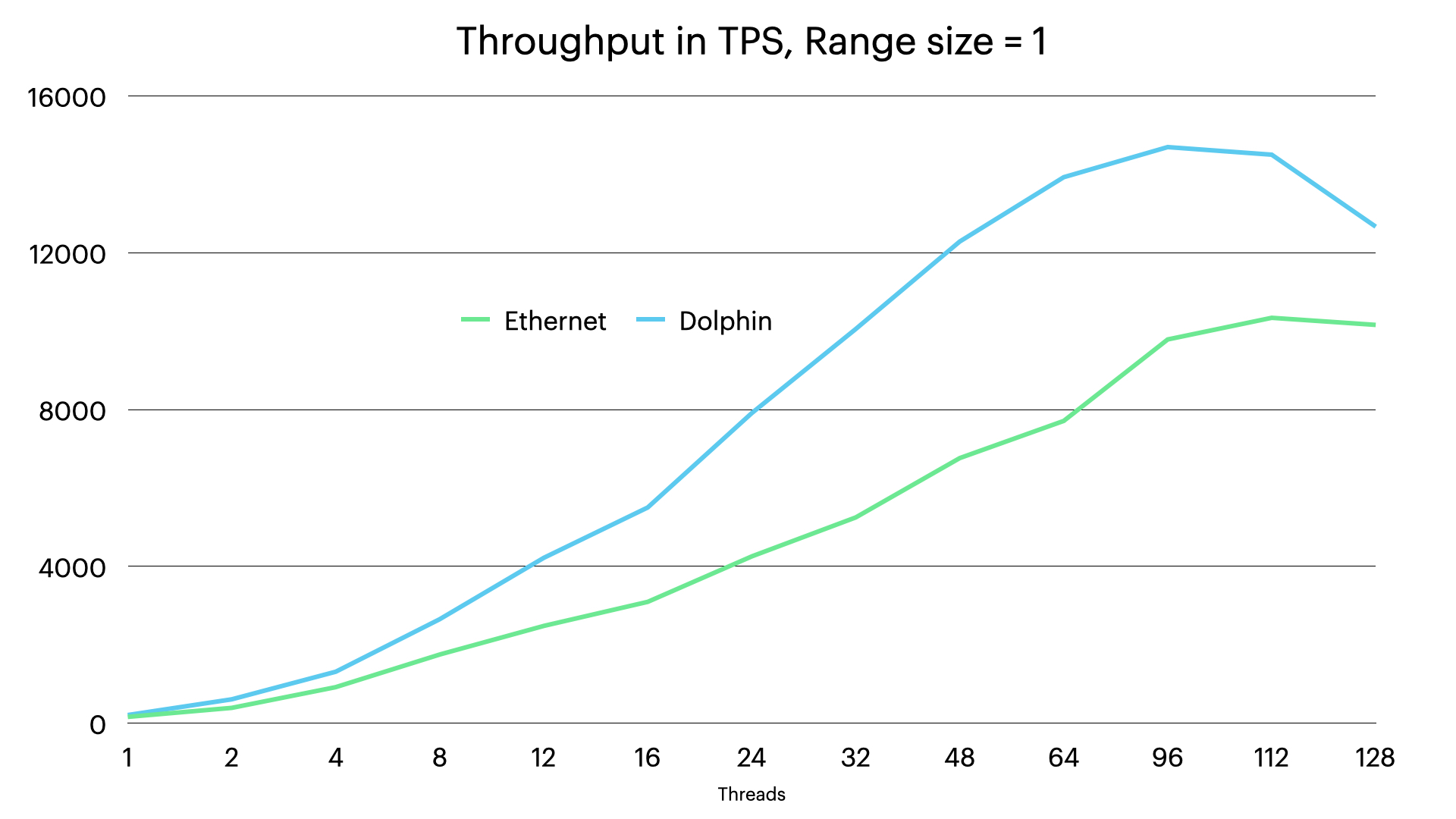
We see that with smaller ranges the bandwidth issue disappears, this means that Ethernet scales better. But we still see that the CPU overhead in the Ethernet setup still limits throughput by 10-20%.
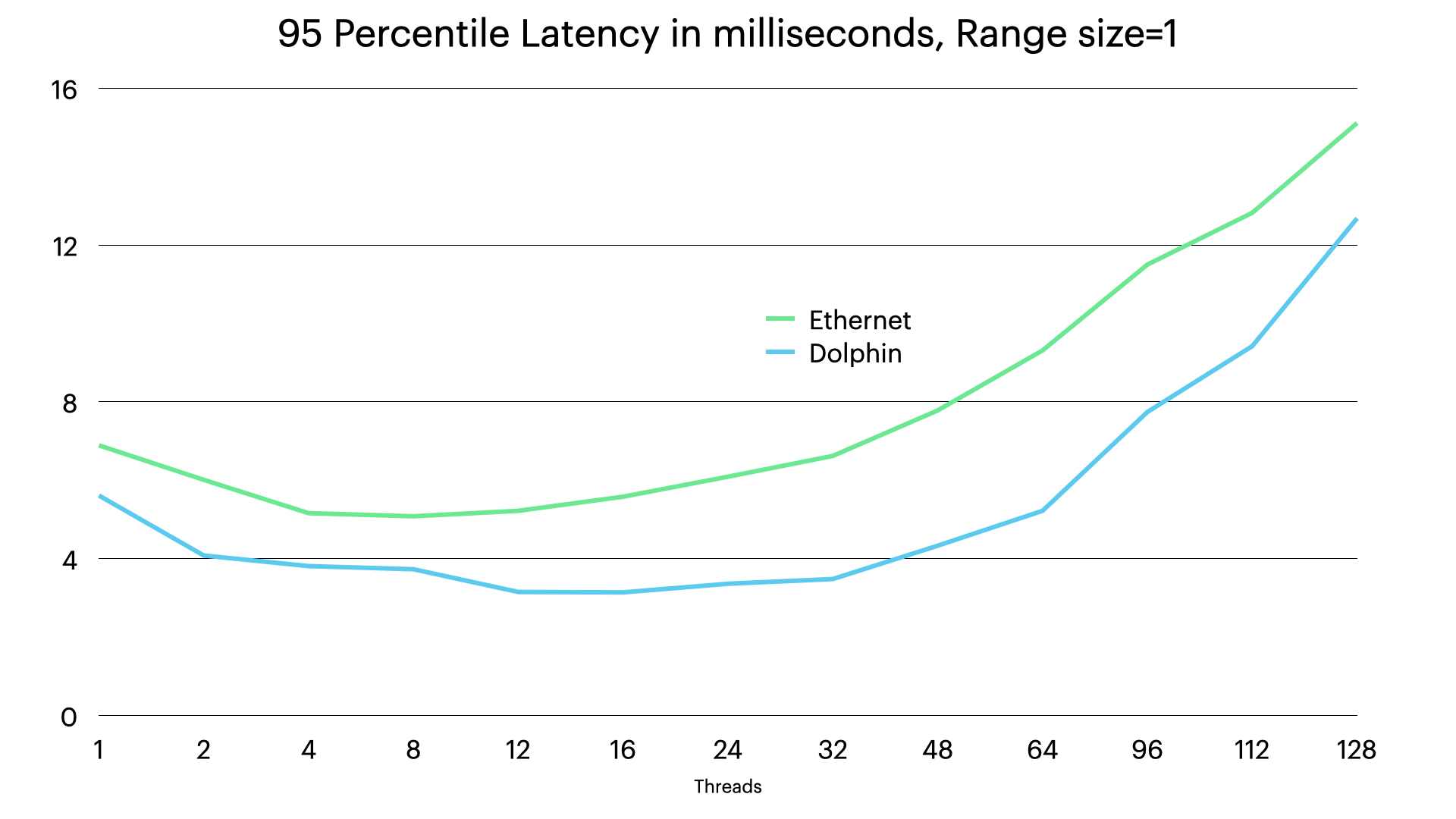
For latency we see that the difference decreases as load increases, at high load it is mainly the CPU overhead that impacts the latency. The wakeup latency is no longer present for neither Dolphin setup nor the Ethernet setup and we also removed the bandwidth limitation from the equation.
Now we move onto the benchmark setup with colocated application, MySQL Server and RonDB data node. In this case it is only communication between data nodes that requires using the Dolphin interconnect. In the previous case we didn’t have any communication between data nodes since there was only one RonDB data node in the previous setup.
Thus in a distributed setup with more than 1 replica and no colocation, we will see the gains from both setups added on top of each other.
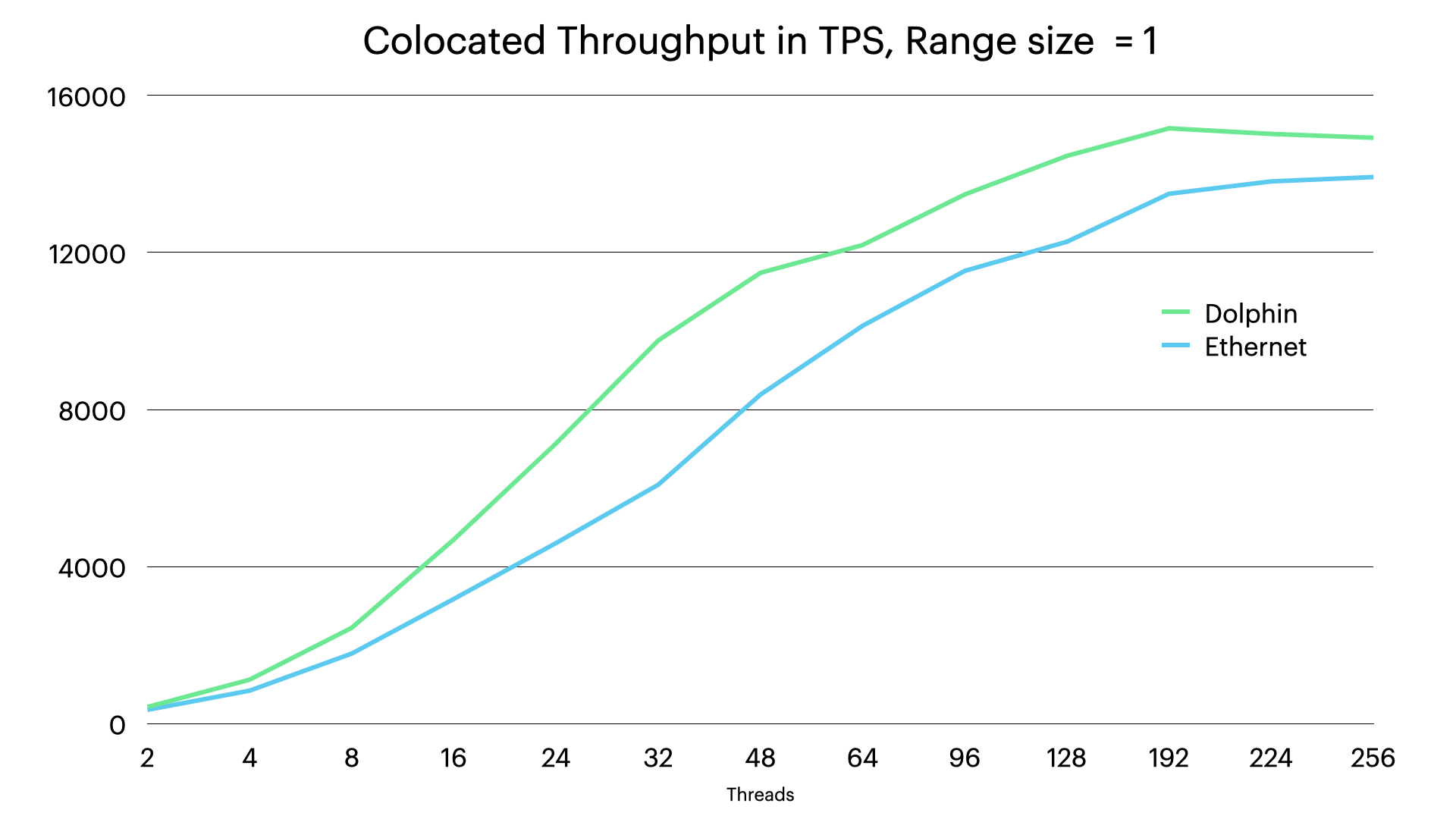
As can be seen even in this setup we see a major difference between Dolphin and Ethernet. There is a fair amount of communication to handle replicated updates, thus it is of great value to have a much smaller wakeup latency.
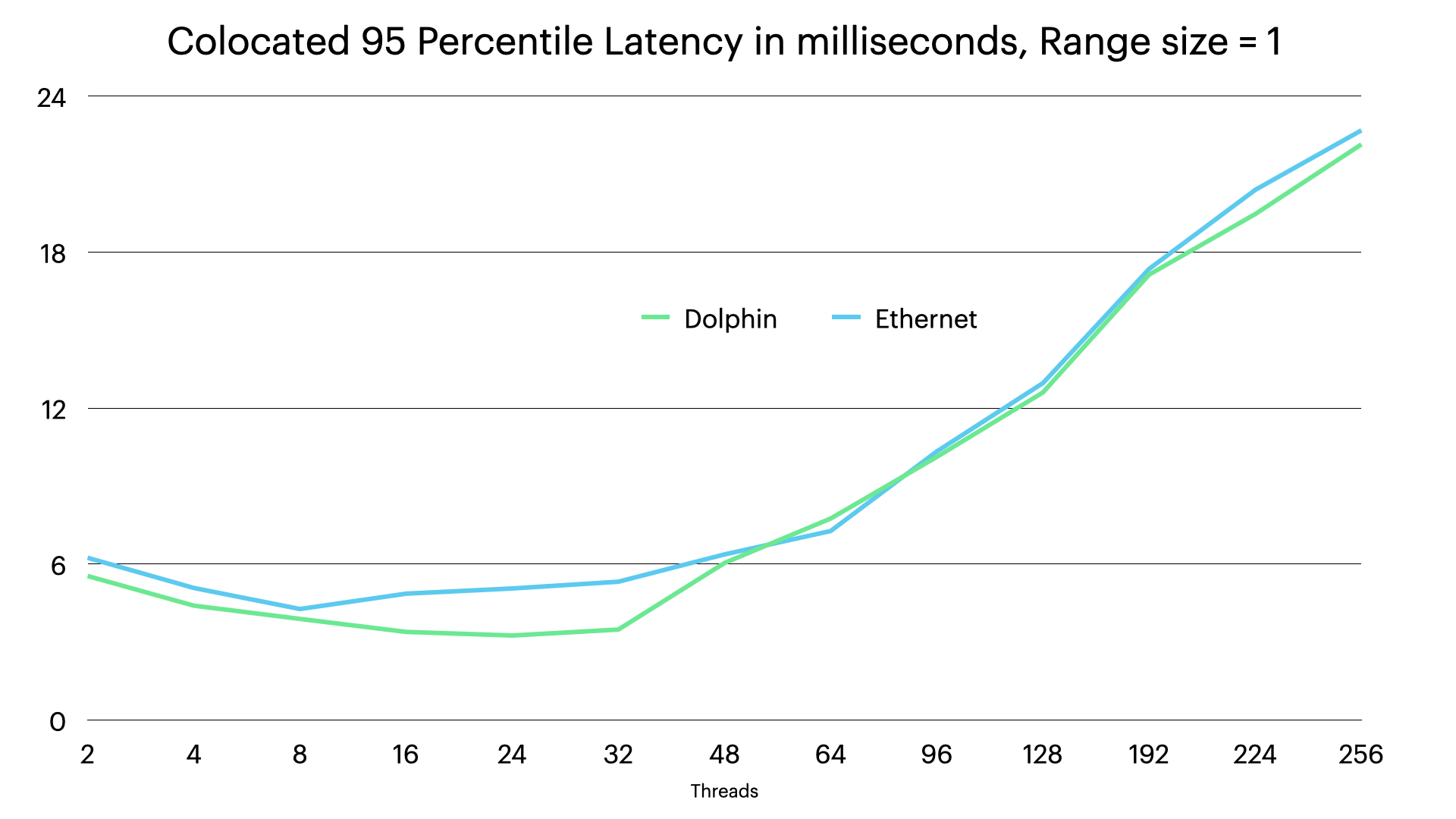
In latency we see that the latency variation is fairly high for Dolphin interconnect.
The next step we want to see the throughput and latency when using shared memory interconnect for communication between nodes in the same server.
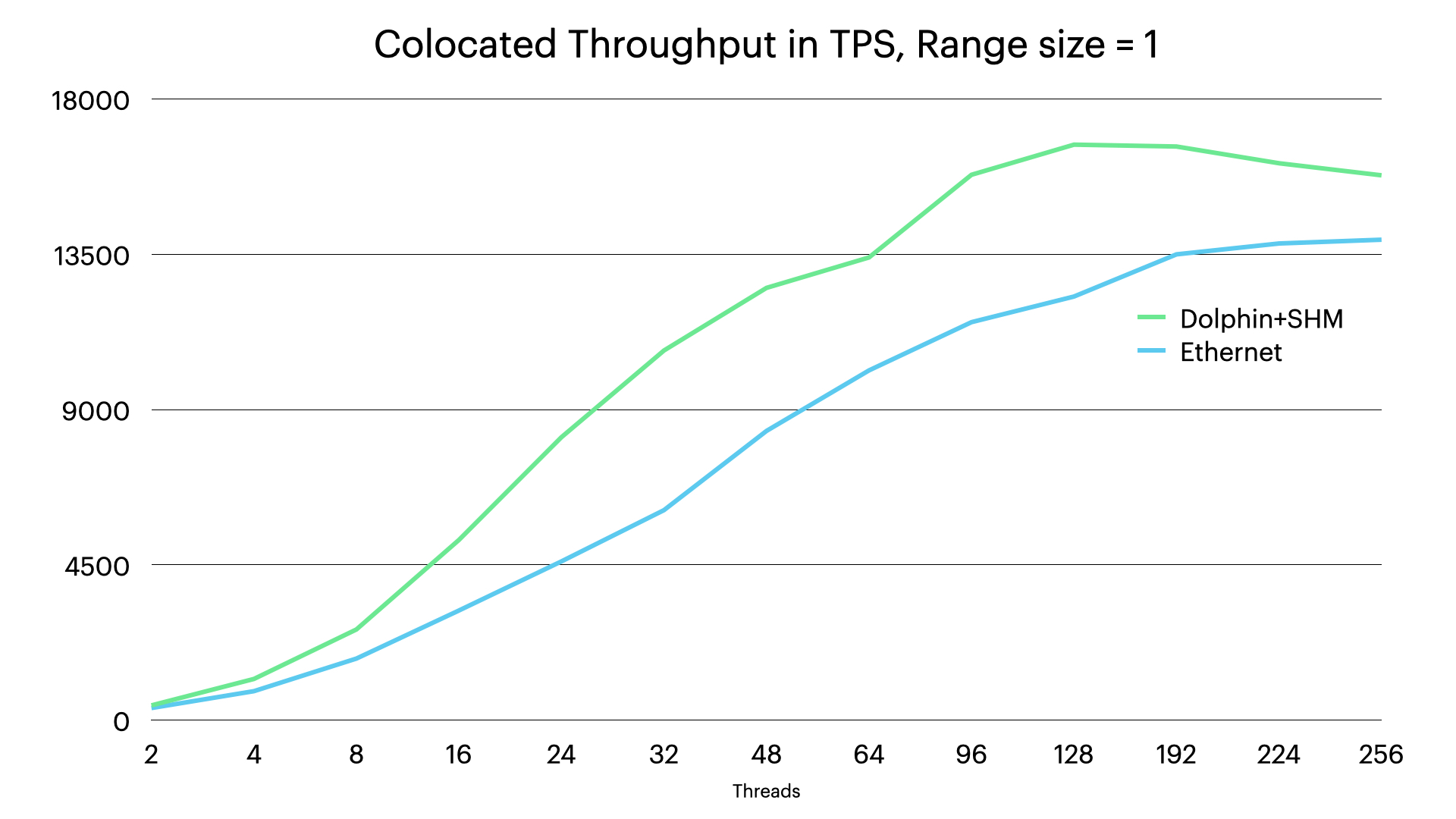
We can see that the performance goes up and it is also pretty clear how the shared memory decreases the CPU overhead, thus ensuring that the throughput increases further, thus providing an extra 10% extra throughput.
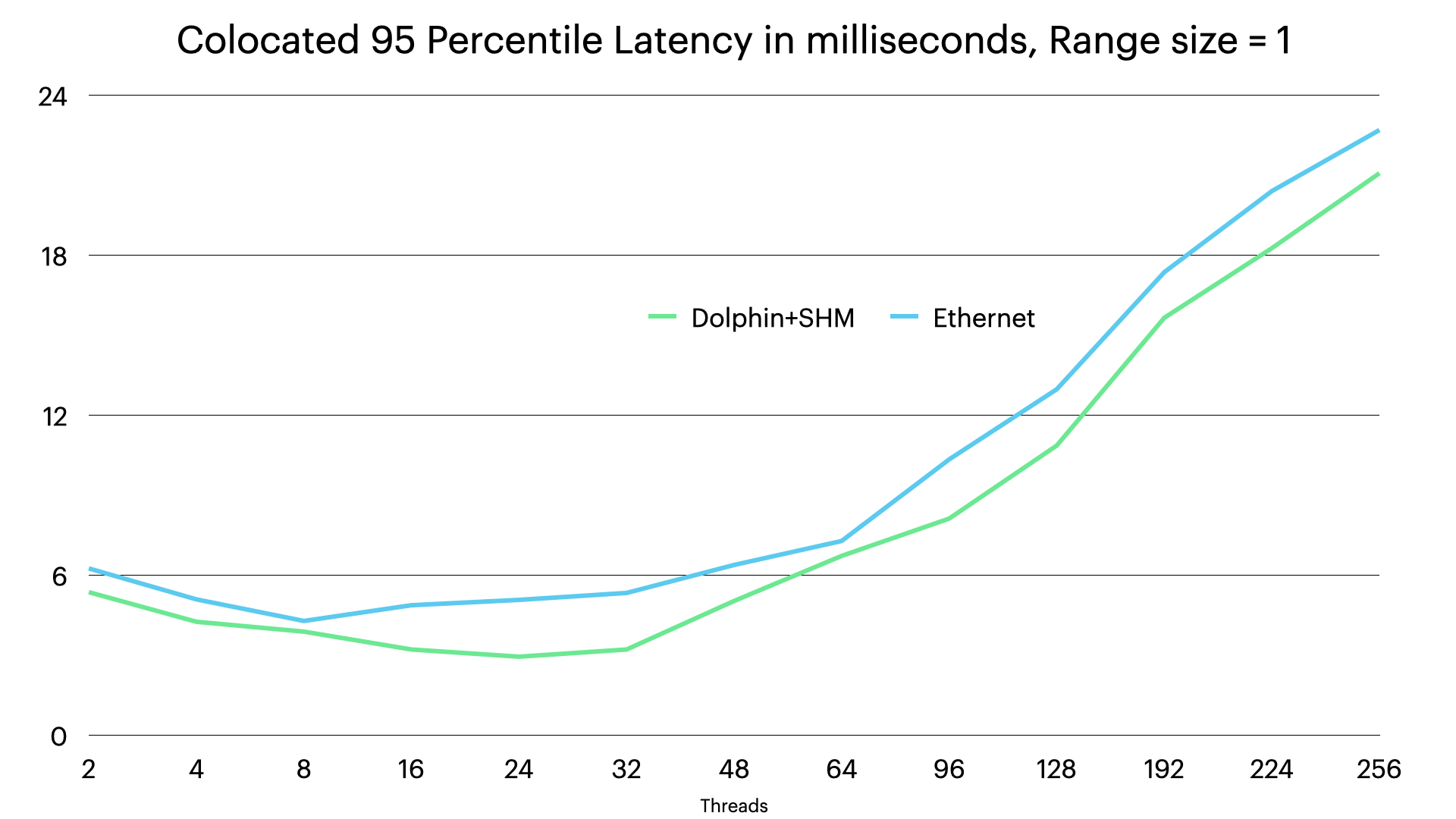
Here we see that the latency improves a bit with shared memory transporter, but the main reason for the improvement of shared memory transporter is the decrease of CPU usage for the shared memory transporter.
Conclusion#
Dolphin interconnect delivers solutions to all three things that can be improved using a high-end interconnect. It delivers 5x higher bandwidth compared to 10G Ethernet, it delivers immediate wakeup by using one CPU to always watch for events arriving on the interconnect and finally by substantially decreasing the amount of CPU usage.
This leads to improvements all the way up to almost 100% better throughput and cutting latency almost in half in the best cases. The experiments had access to 2 servers, we used those to show the improvements separately for communication between application and MySQL Server and separately the communication between the RonDB data nodes. Both those things have a large impact on performance and combining them will bring even more improvements than seen in those benchmarks.
So the expectancy is that the improvements at lower thread counts can be more than 100% and the highest throughput is likely to go up around 20-30% due to lower CPU usage for the interconnect.
The benchmark servers were provided at courtesy of Intelligent Compute for these benchmarks.