Resiliency Model#
RonDB’s resiliency model is strongly based on the setup of partitions and the different replication modes. In the following, we will discuss how these factors define what type and how many crashes we can handle without experiencing downtime.
Rationale for Node Groups#
The details of how RonDB implements node groups and partitioning are explained here. In this section, we will be discussing why we use node groups and how they affect the resiliency model.
Even if RonDB is only running with a single node group, the data nodes will split their data into partitions ("fragments"). This increases manageability and performance since the data node can assign the fragments to different threads and cores.
Partitions are controlled by PartitionsPerNode in the config.ini -
if a cluster has 3 data nodes and PartitionsPerNode=2, each table will
be split up into 6 partitions.
Now RonDB however also supports replication. The following image shows how other distributed databases such as CockroachDB or Aerospike distribute partition replicas across a cluster. Note that replicas of the same partition share the same color.
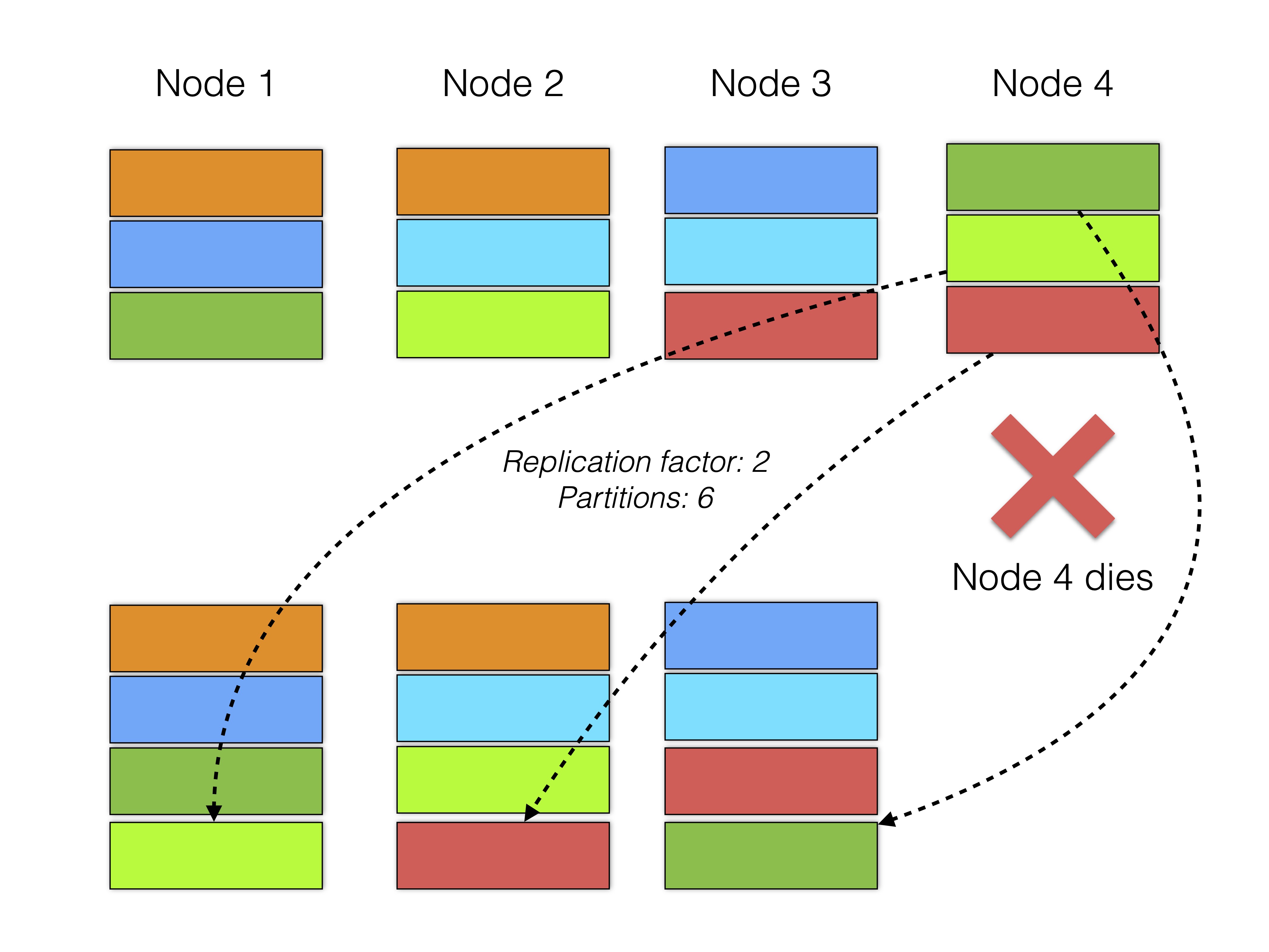
As one can see, the partition replicas are distributed evenly across all nodes in the cluster. Usually, as shown in the figure, this setup also accommodates that a node failure will cause data to be re-distributed across the cluster, given that the other nodes have enough free capacity. This has the advantage that all partitions always reconcile towards a fixed replication factor.
However, this way, the cluster can only survive (replication factor - 1) crashes at a time. In the example of the figure above, every two combinations of nodes contain all replicas of one partition. If two nodes fail simultaneously, the cluster will crash.
Since the requirement for RonDB was maximum availability, we decided to separate partitions into node groups to survive as many simultaneous crashes as possible. By introducing node groups, RonDB can therefore survive (NoOfReplicas - 1) * NoOfNodeGroups crashes. As long as at least one node per node group is still alive, the cluster can continue operating. The following image shows this:
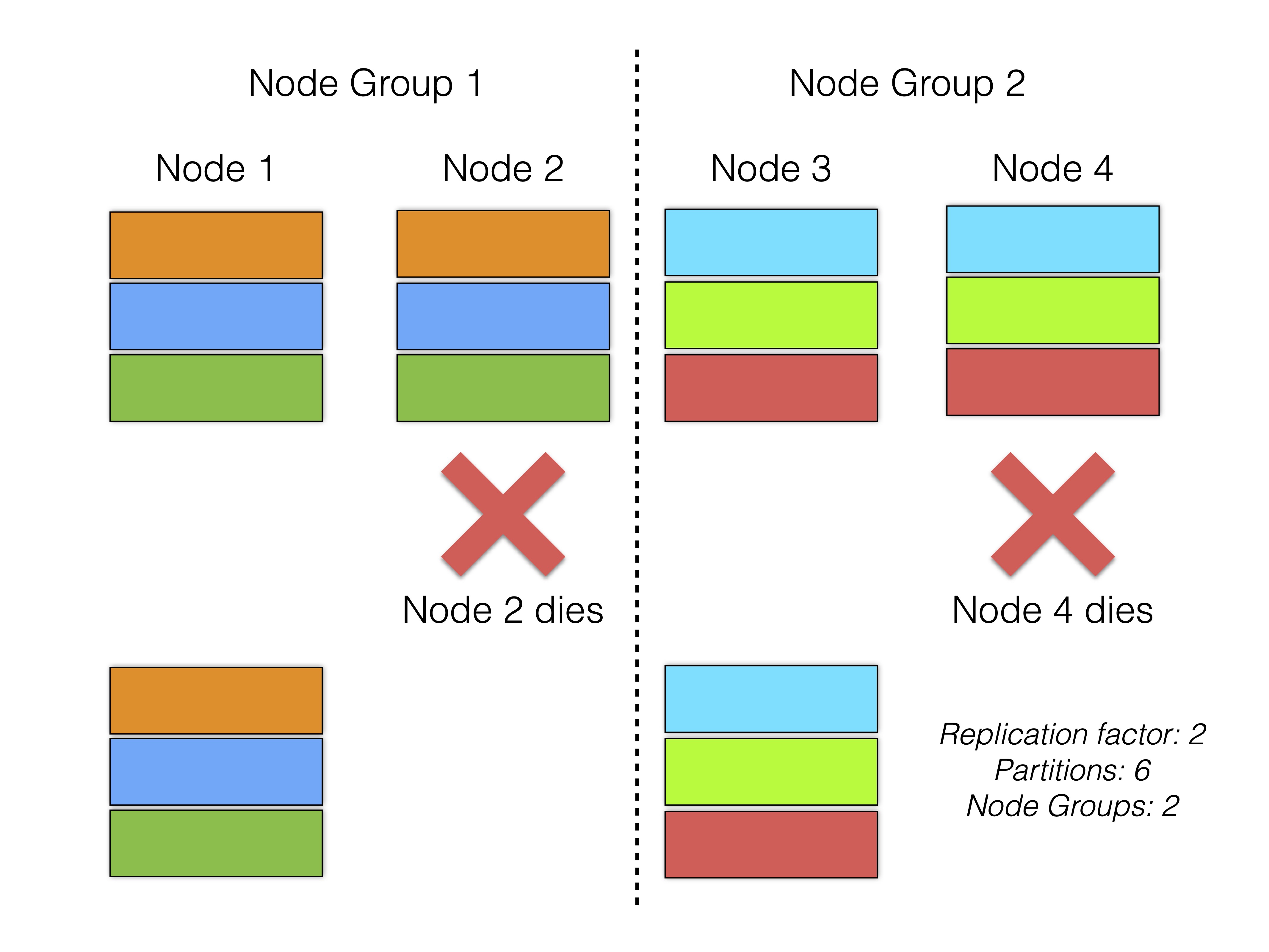
The advantage of this approach comes particularly into play when the cluster experiences a network partition. If each node group has placed a replica in a different availability zone, and there is a network partition between these, the cluster can easily survive. This is described in more detail below.
The disadvantage of this approach is that in the event of a single node failure, only the nodes in the same node group can help with the recovery. This means that the cluster will be slower to recover from minimal failures.
Since node groups do not share any data (except fully replicated tables), they are similar to the sharding concept used in Big Data applications. The main difference is that there, sharding is done from the application level and each shard is a standalone DBMS that has no synchronisation with other shards.
In RonDB, the shards (node groups) are all part of the same DBMS. Everything that we support across partitions is also supported across node groups. This includes:
-
cross-partition transactions
-
cross-partition foreign keys
-
cross-partition unique indexes
-
partition-pruned index scans
Node Groups can also be added to a running cluster whilst all kinds of updates are happening. Adding node groups is done in order to grow storage capacity, especially if data node machines cannot be scaled vertically anymore. When adding node groups, the data is reorganised in all tables, similarly to the first partition model. We call this online resharding.
Replication Models and CAP Theorem#
RonDB supports the following replication models:
| Active-Active | Active-Passive | |
|---|---|---|
| Synchronous (cross-AZ) | 1-3 replicas | - |
| Asynchronous (cross-region) | n clusters (conflict resolution) | n clusters |
The term Active means that a replica or cluster can be used for both reads and writes. The term Passive means that a replica or cluster can only be used for reads.
In RonDB, a passive cluster can become an active cluster in a fail-over process, if its active cluster fails. Furthermore, in RonDB all replicas within an active cluster are active replicas.
Within a cluster, RonDB runs with synchronous replication, whereby it prioritizes consistency over availability (CP in the CAP theorem). In the event of a network partition, RonDB will kill the data nodes in one of these partitions in order to ensure consistency.
Between clusters, RonDB runs with asynchronous replication, whereby it prioritizes availability over consistency (AP in the CAP theorem). This means that RonDB will allow two clusters to diverge in case of a network partition. Later when the network heals, RonDB will replicate changes in both directions and take care of handling conflicts.
Global asynchronous replication is explained in more detail in the Global Replication section.
Synchronous Replication inside a Cluster#
The most basic configuration variable in an RonDB installation is the
NoOfReplicas variable. This can be set to 1, 2, 3 or 4. We recommend
1-3, since 4 replicas is still in beta phase due to known bugs.
One replica naturally means no replication at all and is only interesting when used in a one-node-cluster, where a MySQL server is co-located with a single data node. This can be used for simple fast hash tables or for application development to minimize resources.
Two replicas is the standard use-case for RonDB. Due to the role of the (light-weight) arbitrator, we can already guarantee high availability with this setup. This is in contrast to quorum-based databases, that require at least 3 data replicas to guarantee high availability. These databases often use Raft as their consensus algorithm.
We have also spent a considerable effort to ensure that everything works with 3 replicas since this is often the requirement in financial applications. It turns out to also be very useful in applications such as an Online Feature Store where 3 replicas ensure that we lose very little throughput with the loss of one replica.
Generally, the NoOfReplicas parameter is set at cluster start and
requires a rolling restart to change, like with any other configuration
change. However, it is also possible to have inactive data nodes in
the configuration, which can be activated at a later time without the
need for a rolling restart.
Arbitrator#
The arbitrator is used in only one case. This is when a network partition occurs, two clusters are formed whereby both clusters contain at least one node per node group, and none of the clusters can form a majority of the nodes in the cluster. In this case, we need an arbitrator to decide which cluster will survive. For this to work, the arbitrator must however have already been agreed upon by all live nodes before the network partition happens.
When a data node discovers a need to ask the arbitrator for permission to continue, it asks the arbitrator for its vote. The arbitrator will say yes to the first node and the following nodes will receive a no. In this manner, only one cluster can survive.
Once the arbitrator has voted it cannot be used as an arbitrator anymore. Immediately after using the arbitrator the nodes surviving must select a new arbitrator (or the same one again).
The arbitrator is selected from the set of management servers, API
nodes and MySQL Servers in the cluster. The configuration variable
ArbitrationRank is set on those node slots to provide guidance on
which nodes will be selected as arbitrator. Setting it to 0 means the
node will never be selected as arbitrator and nodes with rank 2 will
always be selected before nodes with rank 1.
Technical: External Arbitrators#
It is also possible to write your own arbitrator and integrate it with RonDB. This can be useful if one wants to use custom logic for deciding which cluster should survive a network partition. This could be the case if one has additional knowledge about the hardware setup and prefers running the cluster on a specific set of machines.
Usually, the data node communicates with the arbitrator - and if it cannot reach it, it will crash. With an external arbitrator however, the data node will instead log a message to the cluster log, which the external arbitrator can then read and act upon. The cluster log is written by the management server, which means that the data node essentially communicates with a management server. One can have multiple management servers in a cluster.
The following would be a message written to the cluster log:
Continuing after wait for external arbitration, node: 1,2
The list 1,2 are the node Ids of data nodes to arbitrate between, i.e.
decide which to allow surviving. The external arbitrator will need to
read this and kill one of the data nodes.
Since this setup is not a direct communication protocol between data
node and arbitrator, the ArbitrationTimeout needs to be set to at
least twice the interval required by the external arbitrator to check
the cluster log. The configuration variable Arbitration is set to
WaitExternal for this to happen.
Cluster Setup Recommendations#
RonDB requires at least three machines to provide a highly available (HA) service. For HA, we only require two data nodes and one arbitrator - and this arbitrator cannot be placed on the same machine as one of the data nodes. If this is done, and the machine fails, the other data will not be able to continue, since it needs to be able to reach either the arbitrator or the other data node. With two machines, we would therefore only be able to survive 50% of the hardware failures. Since the arbitrator can be run via the light-weight management server, the third machine does however not need to be as resourceful as the machines for the data nodes.
Replicas of the same node group should be placed on different machines. In a cluster with a replication factor of 2 and multiple node groups, we can survive a crash of one node per node group, but not crashes of two nodes in the same node group. If two replicas of the same node group are placed on the same machine, we will not be able to survive a crash of that single machine.
If the cluster is executing on VMs, we still need to ensure that the data node & arbitrator VMs are located on different servers and preferably also do not share many hardware resources. In the cloud, this is best done by placing the VMs in different availability zones.
Conclusion#
Taking into account that RonDB experiences a cluster crash when all replicas of a node group fail, but that RonDB can also be set up with multiple asynchronously replicated clusters, RonDB supports the following resiliency model:
-
Min number of machines for HA = 3
-
Min number of failures for cluster crash = NoOfReplicas
-
Max possible failures before cluster failure = (NoOfReplicas - 1) * NoOfNodeGroups
-
Max possible cluster failures = Number of clusters - 1