RonDB Row Data structure#
A database is about storing data for easy accessibility. Most DBMS have some special tricks to store data and indexes in a format suitable for the application categories that the DBMS focus on. RonDB is no different, we have heavily optimised index data structures for primary key access. We have also added a standard index for ordered access to data.
Much of the source code in RonDB is focused on the distribution aspect and reliability aspect, so we probably focus less on data structures than many other DBMSs do. In this chapter we will go through the data structures we use for rows, hash indexes and ordered indexes.
Row format#
RonDB stores rows in two different formats. FIXED format and DYNAMIC format. The term FIXED format is somewhat a misnomer. It means that fixed size columns is stored in the fixed size part of the row and variable sized columns are stored in the variable sized part of the row.
To understand the concepts here we will introduce the data structure of the rows in RonDB. Every row in RonDB has a fixed size part. Most tables also have a variable sized part. All tables with disk columns in addition have a fixed size disk data part up until RonDB 22.01. Tables created in RonDB 22.05 and later versions will use a variable sized data structure also for disk rows. The variable sized data structure for in-memory columns and disk columns are the same.
The fixed size part of the row contains a row header and all the fixed size columns that are using the FIXED format.
The variable sized part contains all columns that have a variable size. The variable sized part have two parts. It has one part for columns that always have at least a length. It has a second part where all columns using the DYNAMIC format are stored.
Columns stored in the dynamic format will not be stored at all if they are NULL or have the default value. This means that new columns with dynamic format can be added to a table without any need to change the row storage at all. This is why we can support add column as an online operation. Columns using the dynamic format will have a bit more overhead when they are stored and the execution overhead will be a bit higher as well for them (around 40% more CPU used in retrieving data from row storage, this is only a small part of the execution time for a row operation except when performing scans that touch very many rows).
There is one more reason to use the dynamic format, the row storage for those columns can be compacted using OPTIMIZE TABLE. Columns that are stored in the fixed row part is not possible to move around and thus cannot be compacted.
The disk columns are always stored in a fixed format, this row part is always of the same size for all rows of a table. Disk columns can thus not be added and dropped as online operations.
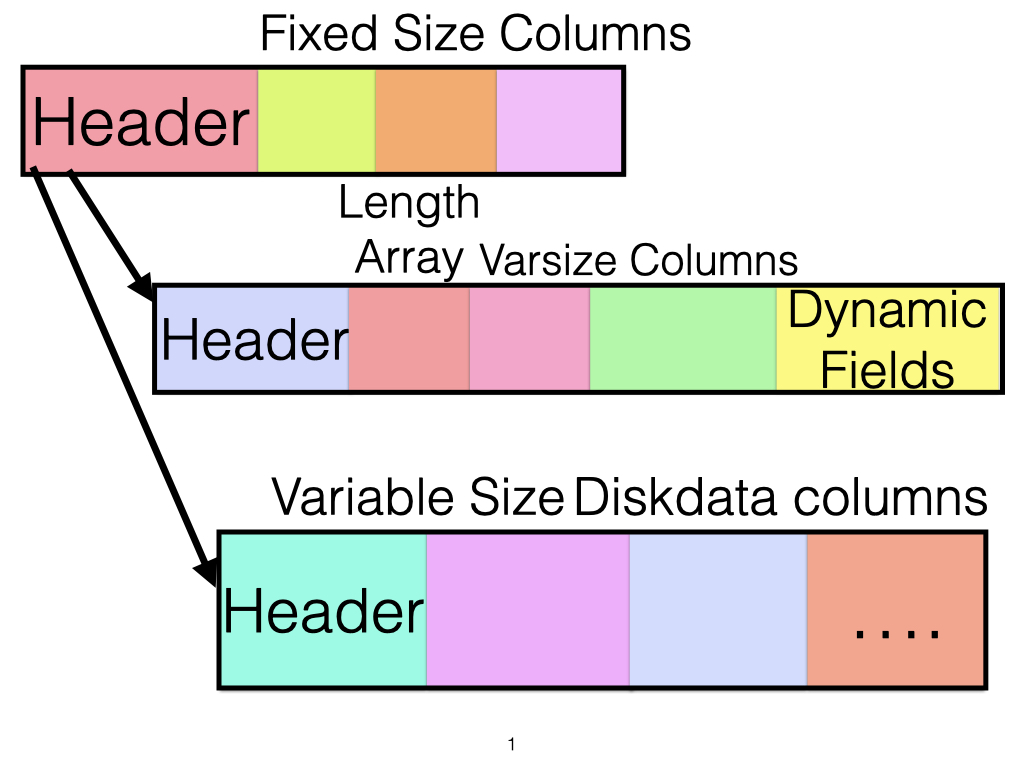
The row header contains the following information:
The first word is used to refer to the operation currently owning the record. This operation might be part of a linked list of operations that have operated on the row in the same transaction. If the row isn’t currently involved in a transaction the first word contains the special value RNIL which is a variant of NULL that is equal to 0xFFFFFF00. Internally in RonDB we use relative pointers, thus 0 is a valid pointer. Thus we had to use a special NULL value and this value is RNIL. It is heavily used in the RonDB code.
The second word contains the tuple header bits. 16 bits are used as a version number which is used by the ordered index to keep track of which row version it is. The other 16 bits are various indicators for the row such as if it has a variable sized part, if it has a disk part, if it has grown in the transaction, some bits referring to local checkpoints and so forth.
The third word contains a checksum of the fixed size part of the row.
The fourth word contains the global checkpoint identifier of the last update of the row. This is an important part used in node recovery to know which rows that need to be synchronised in the starting node.
The fifth word contains NULL bits. If no NULLable columns exists in the table this word doesn’t exist. Each column that is NULLable have one bit in the NULL bits, if more than 32 NULLable columns exist in the table there will be more than one NULL bit word.
Finally we have the reference to the variable sized part of the row and the disk part of the row. Each of those are 8 bytes in size to accomodate large main memory sizes and large disk data sizes.
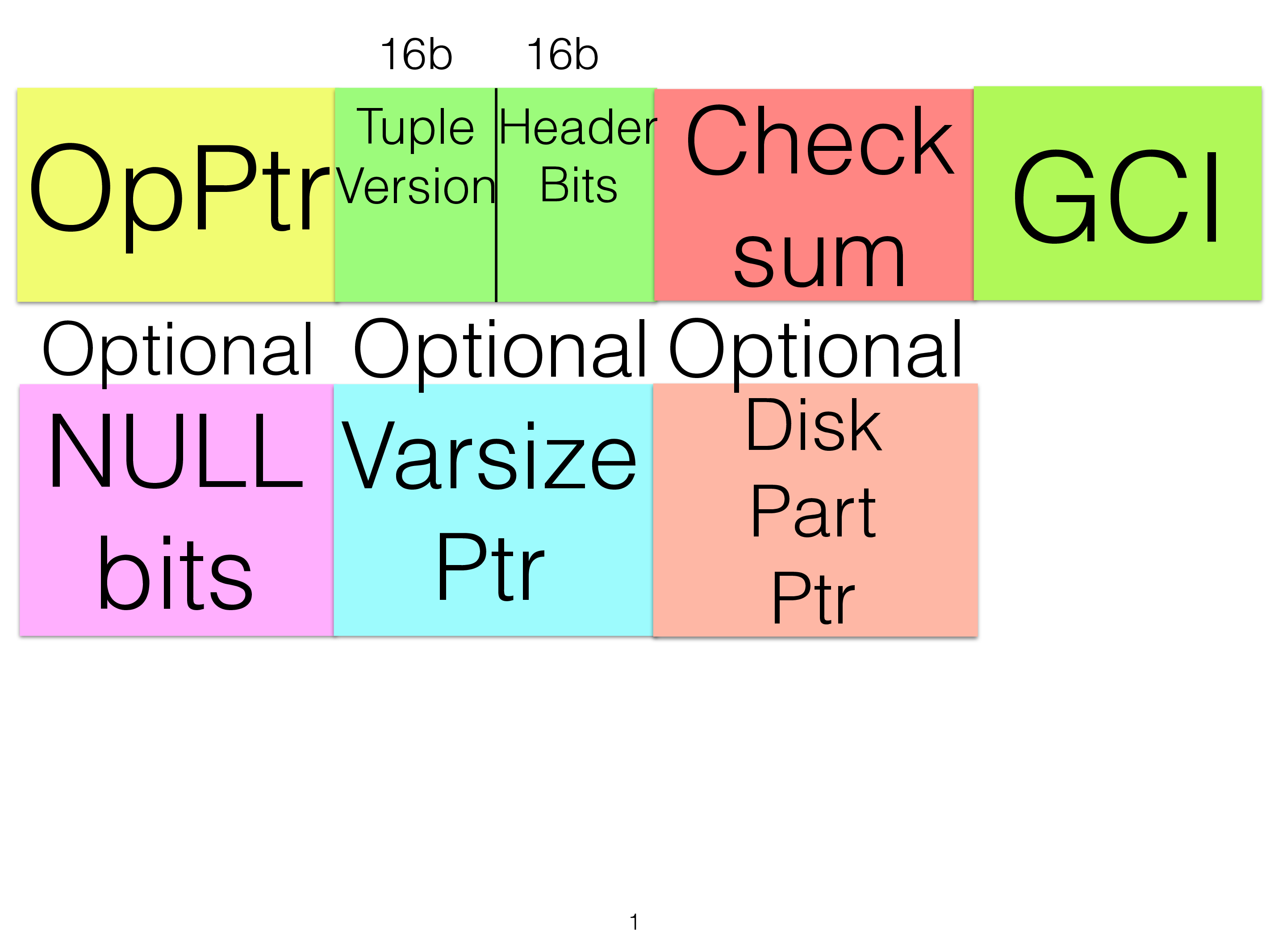
The base header that will be there for all tables is 16 bytes in size. With NULLable rows in the table there will be at least one NULL bit word extending the size to 20 bytes. Most every table uses a variable sized part extending the header size to 28 bytes. If the table uses a disk part the row header extends to 36 bytes.
The most common tables will have a 28 byte row header size (NULL columns exist, have VARCHAR fields and have no disk columns).
The fixed size part of the row is fixed in size at table creation. It doesn’t need to contain any columns at all, but it will always contain the row header. A table always has a fixed size part since this is the entry point to the row. The fixed size part is addressable using a row id. This row id stays constant, a tuple is not allowed to move, the row id of all replicas of the row must use the same row id. At insert the primary replica will assign the row id and this will be sent to the backup replica to ensure that it uses the same row id. This is an important requirement for the synchronisation phase of a node restart.
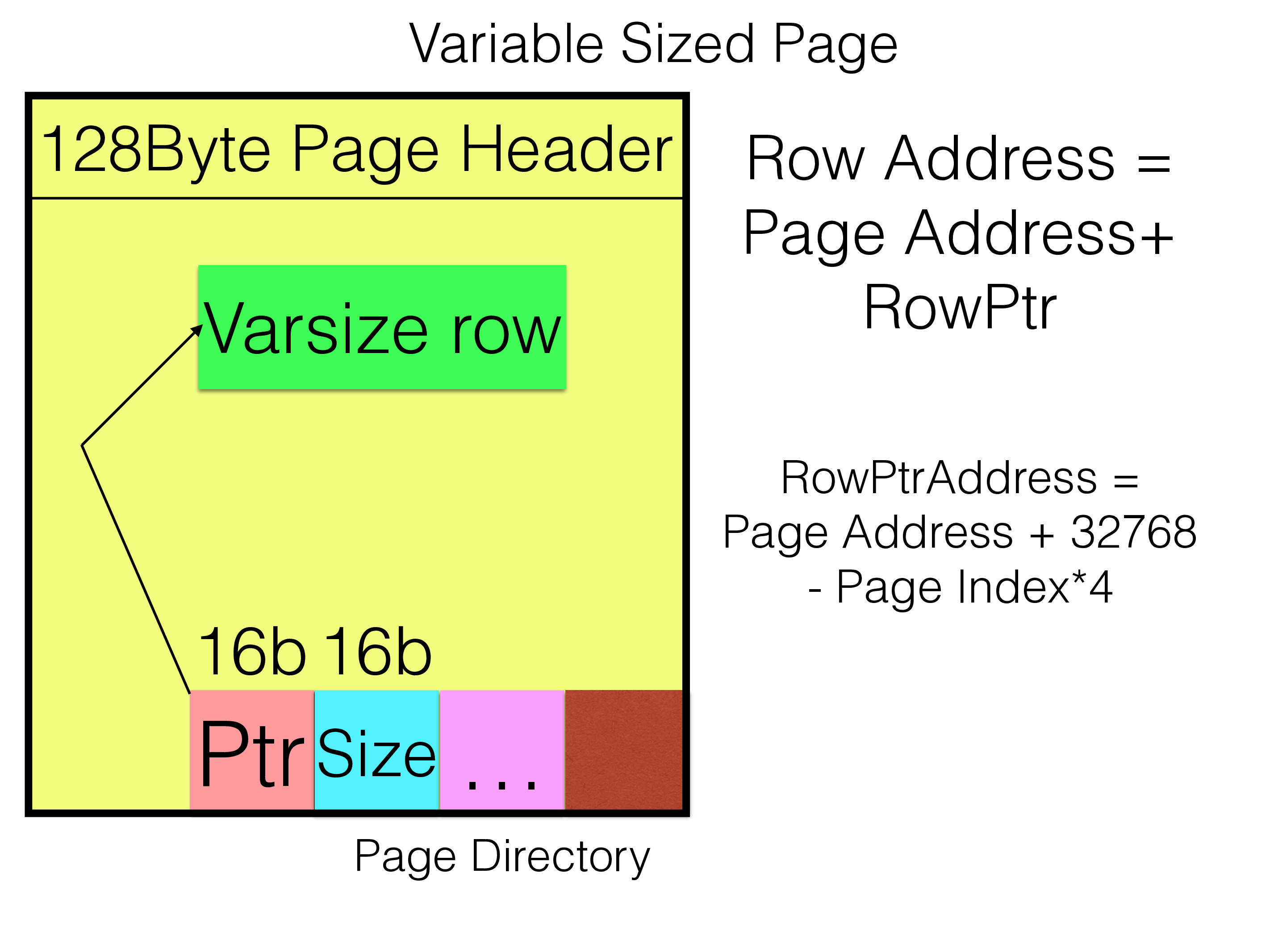
The fixed size part is stored in fixed size pages.

The variable sized part of the row is stored in a variable sized page. Given that it is variable in size we address it through a page directory starting at the end of the page. This page directory contains one word per row, 2 bytes is the index where the row starts in the page, the second 2 bytes is the length of the variable sized part of the row.
Now the variable sized part contains two parts. The first is the variable sized columns. Each such column have 2 bytes that contains the index of the column inside the variable size. The length of the item can be calculated using the next 2 bytes. The start of the column can be quickly found.
This means that all variable sized columns will use at least 2 bytes all the time, but no more than this is needed. NULL bits for variable sized columns is stored in the fixed size part of the row.
We also have a dynamic part, in this part of the row the absence of a column means that its value is NULL. Thus NULL columns consume no space. It means that it is very easy to add a new column in the dynamic part of the row. It needs to be added with NULL or a default value as its starting value. The dynamic part is stored at the end of the variable sized part of the row.
The variable sized part also contains a reference back to the fixed part to ensure that anyone can move the variable sized part when necessary.
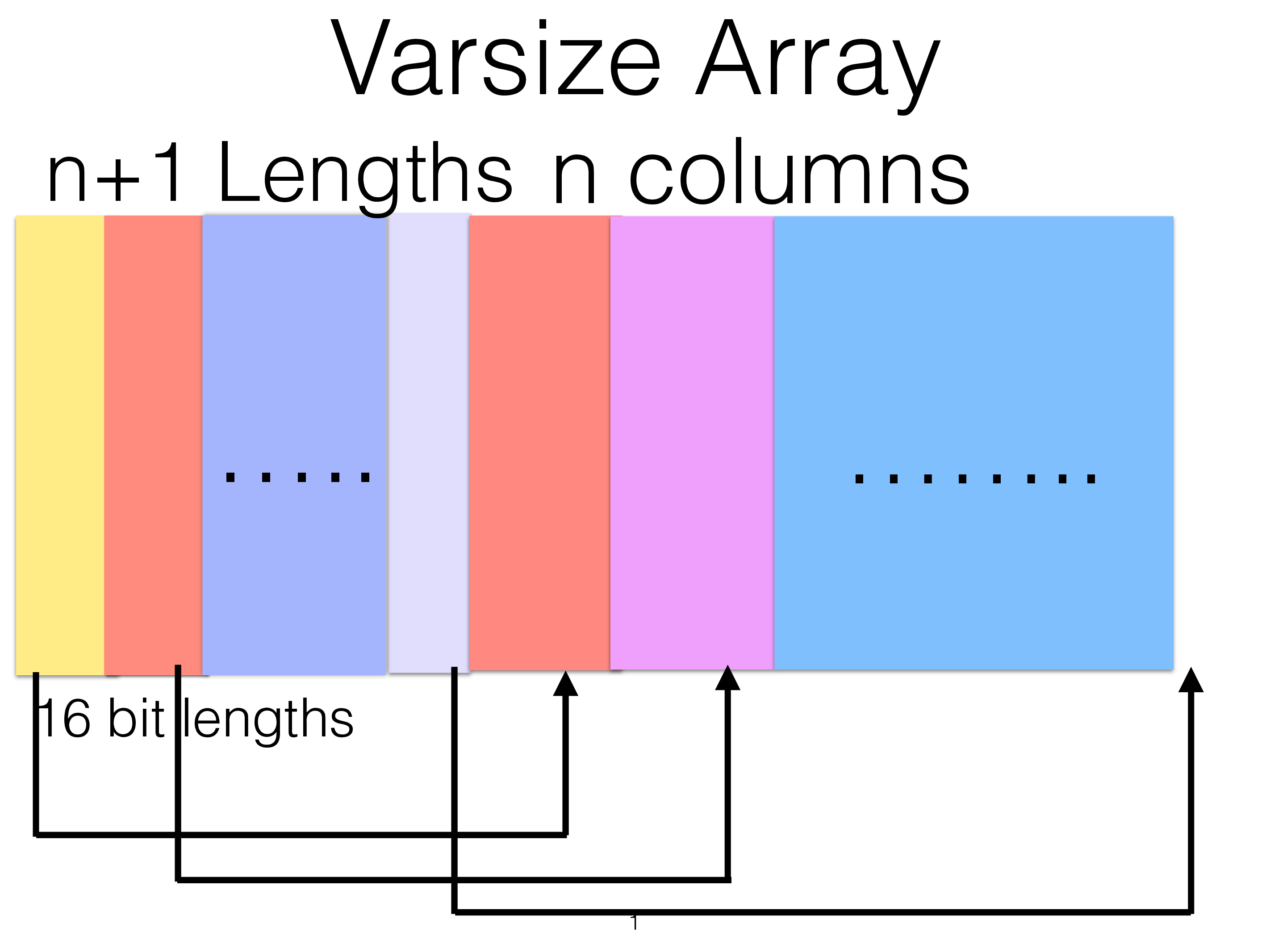
The variable sized part is stored in variable sized pages. These pages are addressed using an index to the page. This index resides at the end of the page. Each index entry is 32 bits in size, 16 bits is the size of the entry and 16 bits is a pointer inside the page to the row part. As mentioned the first 8 bytes in the variable sized part is an 8 byte reference to the fixed row part. The overhead of using a variable sized part is 12 bytes in the variable sized row part in addition to the 8 bytes in the fixed size part, thus in total 20 bytes of overhead per row.
As described above there is also a 2 byte overhead for each variable sized column to store the length of the column.
The disk format is fixed in size until RonDB 22.01. All columns are stored using their maximum size in those versions. In RonDB 22.05 they are stored in variable sized pages in the same fashion as in-memory columns. The variable sized disk row also contains the the fixed size memory disk columns. Thus the disk part will always be stored in variable sized pages.
Fixed row format#
Using the fixed row format means that the column (or all columns if it is applied on the table) is stored in either the fixed size part of the row or in the variable sized part of the row.
Thus the storage for the column is always present, even if set to NULL.
There are many ways to achieve that a column is stored in FIXED format. First there is a configuration variable that sets the default of the column format. This is the MySQL Server configuration option ndb-default-column-format. It can be set to FIXED or DYNAMIC.
By default it will be set to FIXED, normal tables will use the fixed size row format. One can also set the property column_format on the column when creating the table or when altering the table. Here is an example of this.
Dynamic row format#
The Dynamic row format means that the column is stored in the dynamic part of the row. This means that it is easy to add new columns in this part. The column format have a much higher overhead in both storage and in computing necessary to read and write it. The actual read and write of it increases by 40% for the actual read/write part of the transaction. However for a primary key lookup this part is such a small part of the cost that the overhead decrease to much less than 5% whereas for a full table scan that more or is entirely about reading rows will see this 40% drop in performance. An example of this is provided below.