What is special with RonDB#
RonDB is a key-value store with SQL capabilities. It is based on NDB Cluster, also known as MySQL Cluster.
It is a DBMS (DataBase Management System) that is designed for the most demanding mission-critical applications in the telecom network, internet & storage infrastructure, finance, web/mobile apps, gaming, train & vehicle control and a lot more.
It is probably the DBMS and key value database with the highest availability statistics surpassing most competitors by more than a magnitude higher availability.
When a transaction in RonDB has completed, all replicas have been updated, ensuring read-after-write consistency. This is an important feature that makes application development a lot easier compared to when using eventual consistency. It is also a requirement to have constant uptime even in the presence of failures.
The requirement from the telecom network was that complex transactions have to be completed in ten milliseconds. RonDB supports this requirement and this makes RonDB useful also in financial applications and many other application categories that require bounded latency on the queries.
It is designed with the following features in mind:
-
Class 6 Availability (less than 30 seconds downtime per year)
-
Data consistency in large clusters
-
High Write Scalability and Read Scalability
-
Predictable response time
-
Available with MySQL interface, LDAP interface, file system interfaces
-
Available with APIs from most modern languages
To reach Class 6, RonDB supports online software changes, online schema changes, online add node, global solutions with highly available fail-over cases. It is designed with two levels of replication where the first level is local replication to protect against hardware and software failures. The second level is a global replication level that protects against outages due to conflicts, power issues, earthquakes and so forth. The global replication can also be used to perform more complex changes compared to the local replication level.
In both the local and global replication levels, RonDB is designed to support multi-primary solutions. In the local replication, this is completely transparent to the user.
RonDB is a fork of NDB. NDB was developed in response to the development of Network Databases in the telecom world in the 1980s and 1990s. It was originally developed at Ericsson where the founder spent 13 years learning telecom and databases and developing real-time systems for switches and databases. It has been a part of MySQL since 2003 (MySQL NDB Cluster) and it has been in production at many different mission-critical applications across the world since then.
At the moment there are at least several tens of thousands of clusters running in production and probably a lot more. NDB has proven itself in all the areas listed above and have added a few more unique selling points over time such as a parallel query feature and good read scalability as well as scalable writes that have been there from day one.
Experience has shown that NDB meets Class 6 availability (less than 30 seconds of downtime per year) and for extended periods even Class 8 availability (less than 0.3 seconds of downtime per year).
RonDB is based on NDB and moves the design focus for usage in cloud applications. RonDB is designed for automated management, the user only specifies the amount of replication and the size of the hardware they want to use. The managed RonDB version ensures that the user always has access to this through the MySQL APIs and the native RonDB APIs.
To get a quick idea if RonDB is something for your application we will list the unique selling points (USPs) of RonDB.
AlwaysOn for reads and writes#
The term AlwaysOn means that a DBMS is essentially never down. RonDB makes it possible to solve most online changes with its set of features.
Whilst writing, RonDB can:
-
Add columns
-
Add/drop indexes
-
Add/drop foreign keys
-
Add new shards
-
Reorganise data to use new shards
-
Survive multiple node failures per node group
-
Perform software upgrades
Furthermore, it:
-
Detects and handles node failure automatically
-
Recovers after node failure automatically
-
Supports transactional node failures
-
Supports transactional schema changes (atomic, consistent, isolated, durable)
-
Supports global online switch-over between clusters in different geographies
-
Supports global failover for the most demanding changes
One of the base requirements of RonDB is to always support both reads and writes. The only acceptable downtime is for a short time when a node fails. It can take up to a few seconds to discover that the node has failed (the time is dependent on the responsiveness of the operating system used). As soon as the failure has been discovered, data is immediately available for reads and writes, the reconfiguration time is measured in microseconds.
Many other solutions build on a federation of databases. This means standalone DBMSs that replicate to each other at commit time. Given that they are built as standalone DBMSs they are not designed to communicate with other systems until it is time to commit the transactions. Thus with large transactions, the whole transaction has to be applied on the backup replicas before commit if immediate failover has to happen. This technique would in turn stop all other commits since the current replication techniques use some form of token that is passed around and thus large transactions would block the entire system in that case.
Thus standalone DBMSs can never simultaneously provide synchronous replication, immediate failover and predictable response time independent of transaction sizes. RonDB can deliver this since it is designed as a distributed DBMS where all replicas are involved before committing the transaction. Thus large transactions will block every row they touch, but all other rows are available for other transactions to concurrently read and write.
RonDB is designed from the start to handle as many failures as possible. It is possible e.g. to start with 4 replicas and see one failure at a time and end up with only 1 replica alive. This will not hinder clients from reading or writing to the database.
Many management operations are possible to perform while the system continues to both read and write. This is a unique feature where RonDB is at the forefront.
Global solution for replication#
RonDB has the following replication characteristics:
-
Synchronous replication inside one cluster
-
Asynchronous replication between clusters
-
Conflict detection when using multiple primary clusters
-
Replication architecture designed for real-world physics
RonDB has a unique feature in that it supports multiple levels of replication. The base replication is the replication inside the cluster. This replication is synchronous and as soon as you have updated an object you will see the update in all other parts of the cluster.
The next level of replication is asynchronous replication between clusters. This replication takes the set of transactions from the last 10 millisecond period and replicates it to the other cluster. Thus the other cluster will see the updates from the updated cluster with a small delay.
These replication modes are independent of each other. It is possible to replicate to/from InnoDB using this approach as well.
The asynchronous replication supports multiple primary clusters. This requires conflict detection handling and NDB provides APIs to handle conflicts when conflicting updates occur. Several different conflict detection mechanisms are supported. It is also possible to create complex replication architectures, even circular.
The replication architecture is designed to handle real-world physics. The default synchronous replication is designed for communication inside a data center where latency is less than 100 microseconds to communicate between nodes and communication paths are wide (nowadays often 10G Ethernet and beyond).
With the development of public clouds, we have a new level which is availability zones. These normally communicate with each other in less than a millisecond and down to 400 microseconds. Local replication can be used between availability zones.
When communicating between data centers in different regions the latency is normally at least 10 milliseconds and can reach 100 milliseconds if they are very far apart. In this case, we provide the asynchronous replication option.
This means that wherever you place your data in the world, there is a replication solution for that inside RonDB.
The global replication solution enables continued operation in the presence of earthquakes and other major disturbances. It makes it possible to perform the most demanding changes with small disturbances. There are methods to ensure that switching over applications from one cluster to another can be performed in a completely online fashion using transactional update logic.
Thus if users want to follow the trends and move their data in RonDB from on-premise to the cloud, this can be made without any downtime at all.
Hardened High Availability#
NDB was originally designed for latency in the order of a few milliseconds. It was designed for Class 5 availability (less than 5 minutes of downtime per year). It turns out that we have achieved Class 6 availability in reality (less than 30 seconds of downtime per year).
NDB was first put into production in a high availability environment in 2004 using version 3.4 of the product. This user is still operating this cluster and now using a 7.x version. Thousands and thousands of clusters have since been put into production usage.
With modern hardware, we are now able to deliver response time on the order of 100 microseconds and even faster using specialized communication hardware. At the same time, the applications create larger transactions. Thus we still maintain latency of transactions on the order of a few milliseconds.
Consistency of data in large clusters#
This includes the following points:
-
Fully synchronous transactions with non-blocking two-phase commit protocol (2PC)
-
Data immediately seen after commit from any node in the cluster
-
Read-after-write consistency
-
Cross-shard transactions and queries
Both in the MySQL world and the NoSQL world, there is a great debate about how to replicate for the highest availability. Our design uses fully synchronous transactions.
Most designs have moved toward complex replication protocols since the simple two-phase commit protocol is a blocking protocol. Instead of moving to a complex replication protocol, we solved the blocking part. Our two-phase commit protocol is non-blocking since we can rebuild the transaction state after a crash in a new node. Thus independent of how many crashes we experience, we will always be able to find a new node to take over the transactions from the failed node (as long as the cluster is still operational, a failed cluster will always require a recovery action, independent of replication protocol).
During this node failure takeover, the rows that were involved in the transactions that lost their transaction coordinator remain locked. The remainder of the rows are unaffected and can immediately be used in new transactions from any alive transaction coordinator. The locked rows will remain locked until we have rebuilt the transaction states and decided the outcome of the transactions that lost their transaction coordinator.
When a transaction has completed, RonDB has replicated not only the logs of the changes. RonDB has also updated the data in each replica. Thus independent of which replica is read, it will always see the latest changes.
Thus we can handle cross-shard transactions and queries, meaning that we make the data available for reading immediately after committing the data.
The requirement to always be able to read your own updates we solve either by always sending reads to the primary replica or through a setting on the table to use the read backup feature in which case the commit acknowledged is delayed shortly to ensure that we can immediately read the backup replicas and see our own update.
Cluster within one data center#
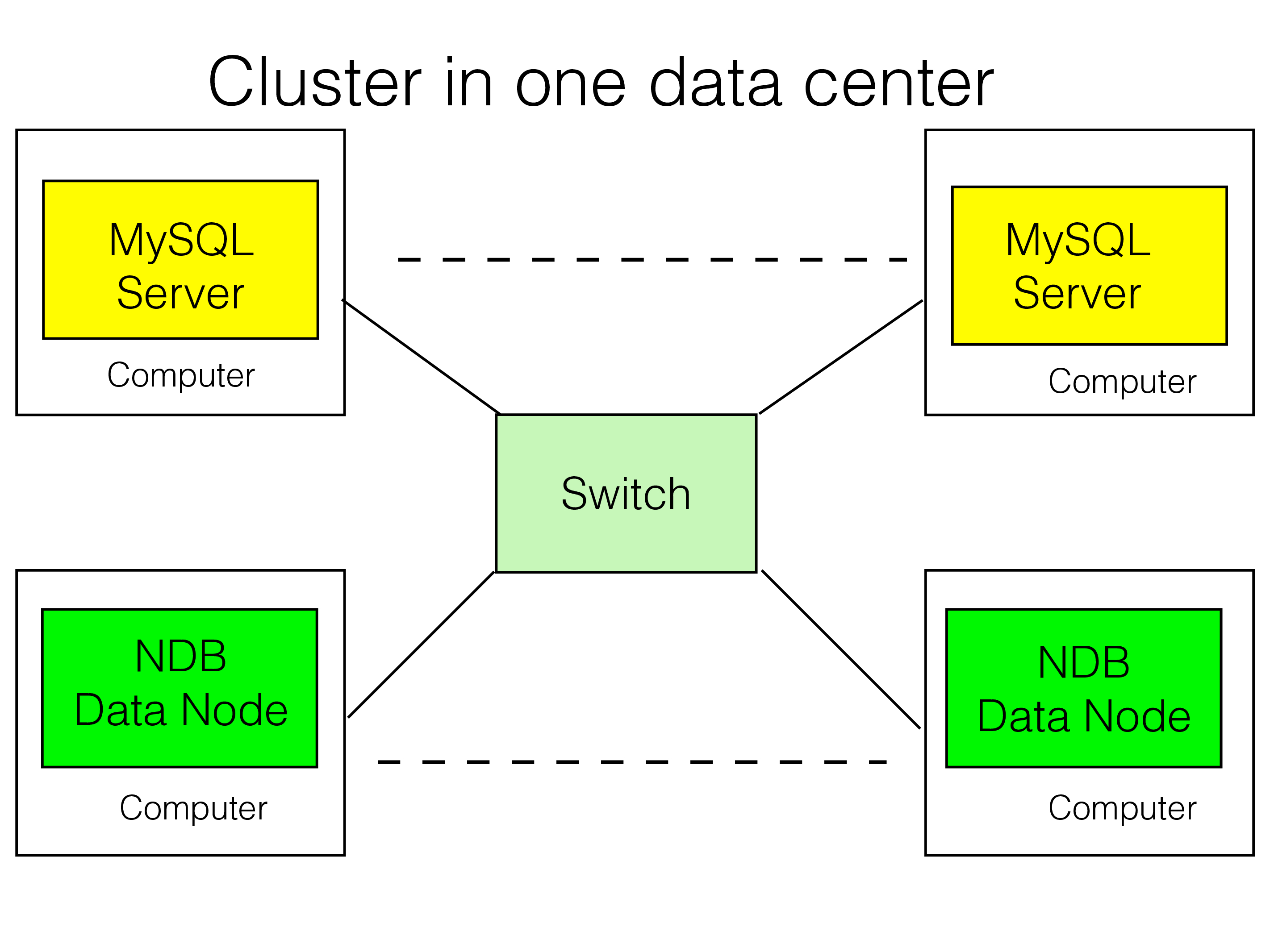
RonDB was originally designed for clusters that resided within one data center. The latency to send messages within one data center can be anywhere between a few microseconds to below one hundred microseconds for very large data centers. This means that we can complete a transaction within less than a millisecond and that complex transactions with tens of changes can be completed within ten milliseconds.
Using low latency hardware the latency in this case can be brought down even further. Dolphin ICS in Norway is a company that specializes in low-latency interconnect technology. Using their SuperSocket drivers it is possible to bring down latency in sending a message from one node to another to less than one microsecond. The first communication technology that worked with NDB existed in the 1990s and was based on Dolphin hardware.
Using SuperSocket hardware is equivalent in speed to using RDMA protocols. NDB has supported specialized hardware interconnects in the past from OSE Delta and from Dolphin and there has been experimental work on Infiniband transporters. But using SuperSocket driver technology removed the need for specialized transporter technology.
It is possible to use Infiniband technology with RonDB using IPoIB (IP over Infiniband). This has great bandwidth, but not any other significant advantages compared to using Ethernet technologies.
Cluster within one region#
In a cloud provider, it is customary to bring down entire data centers from time to time. To build a highly available solution in a cloud often requires the use of several data centers in the same region. Most cloud providers have three data centers per region. Most cloud providers promise latency of 1-2 milliseconds between data centers whereas the Oracle Cloud provides latency below half a millisecond. Inside a cloud data center (within an availability zone) the latency is below 100 microseconds for all cloud vendors.
This setup works fine with RonDB and will be covered in more detail in the chapter on RonDB in the cloud. The main difference is that the latency to communicate is a magnitude higher in this case. Thus not all applications will be a fit for this setup.
Several clusters in different regions#
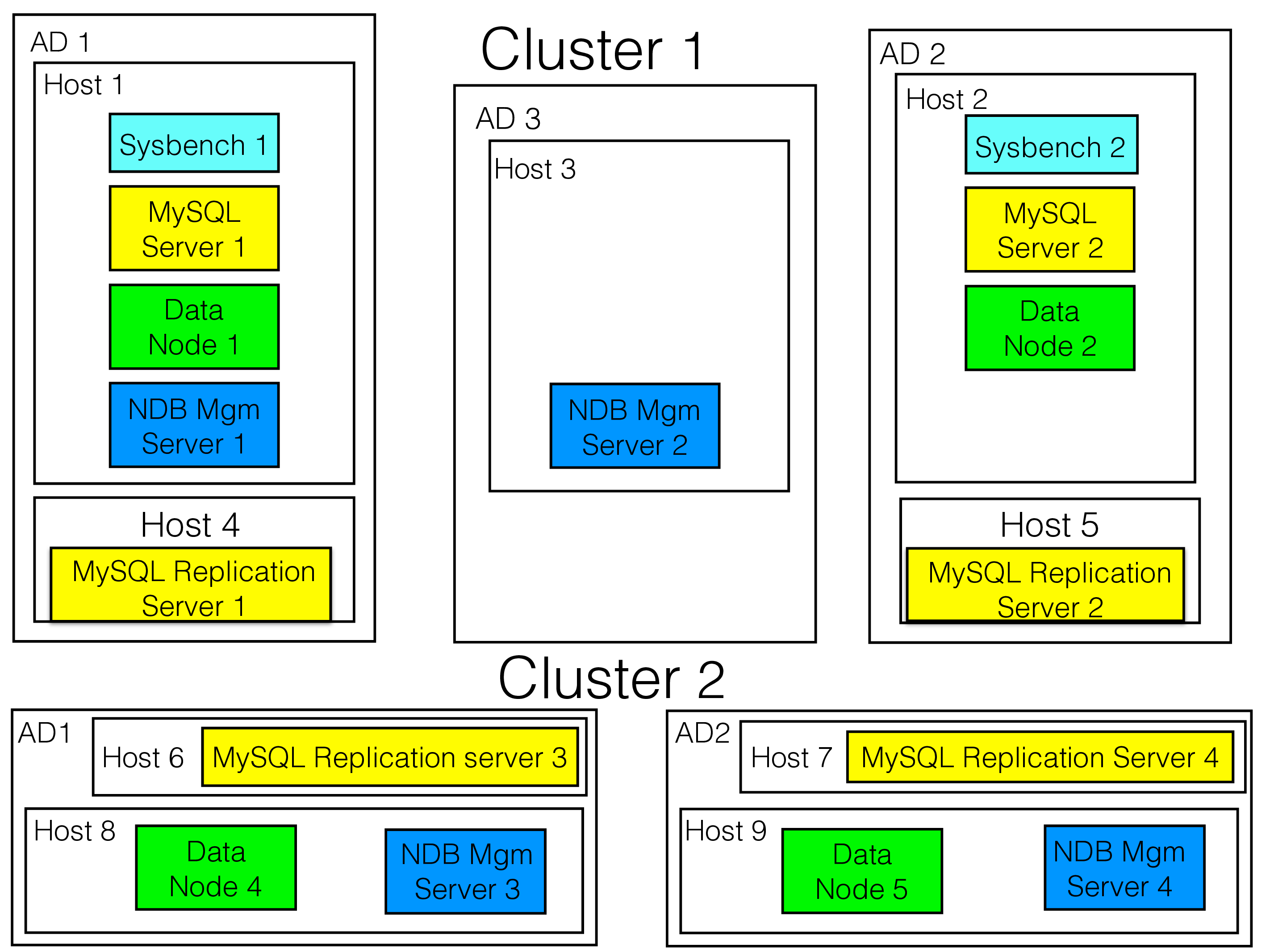
For global replication, we use an asynchronous replication protocol that can handle many clusters doing updates at the same time and providing conflict detection protocols (more on that below). Thus we use two levels of replication for the highest availability. RonDB is safe from earthquakes, data center failures and the most complex software and hardware upgrades.
RonDB is unique in bringing both the best possible behavior in a local cluster while at the same time providing support of global replication.
The figure below shows a complex setup that uses two clusters in different regions and each cluster resides in several availability domains (ADs) within one region. Global Replication is used to ensure that a RonDB setup with global replication will survive in the presence of an entire region being down.
We will cover this setup in greater detail in the part on Global Replication.
High read and write scalability#
RonDB 21.04 can scale to 64 data nodes and 24 MySQL Servers and 12 API nodes (each MySQL Server and API node can use 4 cluster connections).
NDB has shown in benchmarks that it can scale up to 20 million write transactions per second and more than 200 million reads per second already in 2015.
To achieve optimal scaling the following points are important:
-
Partition pruned index scans (optimized routing and pruning of queries)
-
Distribution-aware transaction routing (semi-automatic)
-
Partitioning schemes
RonDB is designed to scale both for reads and writes. RonDB implements sharding transparent to the user. It can include up to 32 node groups where data is stored. It is also possible to fully replicate tables within all node groups. The data nodes can be accessed from up to 24 MySQL Servers that all see the same view of the data.
This makes it possible to issue tens of millions of SQL queries per second against the same data set using local access thus providing perfect read scalability.
To provide optimal scaling in a distributed system it is still important to provide hints and write code taking account of the partitioning scheme used.
Costs of sending have been and continue to be one of the main costs in a distributed system. To optimize the sending it is a good idea to start the transaction at the node where the data resides. We call this Distribution-aware transaction routing.
When using the NDB API it is possible to explicitly state which node to start the transaction at. For the most part, it is easier for the application to state that the transaction should start at the node where the primary replica of a certain record resides.
When using SQL the default mechanism is to place the transaction at the node that the first query is using. If the first query is
then the transaction will be started at the node where the record with primary key column pk equal to 1 is stored. This can be found by using the hash on the primary key (or distribution key if only a part of the primary key is used to distribute the records).
The next problem in a shared-nothing database is that the number of partitions grows with the number of nodes and in RonDB also with the number of threads used. When scanning the table using some ordered index it is necessary to scan all partitions unless the partition key is fully provided.Thus the cost of scanning using ordered index grows with a growing cluster.
To counter this it is important to use partition pruned index scans as much as possible. A partition pruned index scan is an index scan where the full partition key is provided as part of the index scan. Since the partition key is provided we can limit the search to the partition where rows with this partition key are stored.
In TPC-C for example it is a good idea to use warehouse ID as the
distribution key for all tables. This means that any query that accesses
only one warehouse only needs to be routed to one partition. Thus there
is no negative scaling effect.
If it isn’t possible to use partition pruned index scans there is one more method to decrease cost of ordered index scans. By default, tables are distributed over all nodes and all ldm threads (ldm stands for Local Database Manager and contains the record storage, hash indexes and ordered indexes and the local recovery logic). It is possible to specify when creating the table to use fewer partitions in the table. The minimum is to have one partition per node group by using standard partitioning schemes. It is possible to specify the exact number of partitions, but when specifying an exact number of partitions the data will not be evenly spread over the nodes, this requires more understanding of the system and its behavior. Therefore we have designed options that use fewer partitions in a balanced manner.
In RonDB we have added a new thread type called query threads. This makes it possible to read a partition from multiple threads concurrently. This makes it possible to increase scalability without having to create more partitions. In RonDB a table gets 6 partitions per table per node group by default.
By efficiently using these schemes it is possible to develop scalable applications that can do many millions of complex transactions per second. A good example of an application that has been successful in this is HopsFS. They have developed the metadata layer of Hadoop HDFS using RonDB.
They use the ID of the parent directory as a distribution key which gives good use of partitioned pruned index scans for almost all file operations. They have shown that this scaled to at least 12 data nodes and 60 application nodes (they ran out of lab resources to show any bigger clusters).
A presentation of these results in a research paper at the 17th IEEE/ACM International Symposium on Cluster, Cloud and Grid Computing won the IEEE Scale Challenge Award in 2017.
Predictable response time#
This includes the following points:
-
Main memory storage for predictable response time
-
Durable by committing on multiple computers in memory (Network Durable)
-
CPU cache optimized distributed hash algorithm
-
CPU cache optimized T-tree index (ordered index)
-
Application-defined partitioning (primary key partitioning by default)
-
Batched key lookup access
-
Several levels of piggybacking in network protocols
-
Maintaining predictable response time while improving throughput
Piggybacking happens on several levels, one level is that we pack many
commit messages and some other messages together in special
PACKED_SIGNAL messages. The other is that we use one socket for
communication between nodes. Given that our internal architecture uses
an asynchronous programming model means that we automatically can batch
a lot of messages together in one TCP/IP message. We execute a set of
messages and collect the responses from these messages in internal
buffers until we’re done executing and only then do we send the
messages. Finally, we execute in many threads in parallel such that when
sending we can collect messages from many threads.
Telecom applications, financial applications and gaming applications have strict requirements on the time one is allowed to take before one responds to the set of queries in a transaction. We have demanding users that require complex transactions with tens of interactions with hundreds of rows to complete within a few milliseconds in a system that is loaded to 90% of its capacity.
This is an area where one would probably not expect to find an open source DBMS such as MySQL at the forefront. But in this application area RonDB comes out at the top. The vendors selecting NDB Cluster have often tough requirements, up to more than millions of transactions per second, Class 6 availability and at the same time providing 24x7 services and being available to work with users when they have issues.
The data structures used in NDB have been engineered with a lot of thought on how to make them use CPU caches in the best possible manner. As a testament to this, we have shown that the threads handling the indexes and the data have an IPC of 1.27 (IPC = Instruction Per Cycle). Normal DBMS usually report an IPC of around 0.25.
Base platform for data storage#
This includes the following points:
-
MySQL storage engine for SQL access
-
OpenLDAP backend for LDAP access
-
HopsFS metadata backend for Hadoop HDFS (100s of PByte data storage)
-
Prototypes of distributed disk block devices
-
Integrated into Oracle OpenStack
RonDB can be used as a base platform for many different types of data. A popular use is SQL access using MySQL. Another popular approach is to use NDB as the backend in an LDAP server. OpenLDAP has a backend storage engine that can use RonDB. Some users have developed their own proprietary LDAP servers based on top of NDB (e.g. Juniper).
SICS, a research lab connected to KTH in Stockholm, Sweden, has developed HopsFS. This is a metadata backend to Hadoop HDFS for storing many petabytes of data in HDFS and enabling HDFS to handle many millions of file operations per second. HopsFS uses disk data in NDB to store small files that are not efficient to store in HDFS itself.
Based on work from this research lab, a new startup, Hopsworks AB, was created that focuses on developing a Feature Store for Machine Learning applications. Here, RonDB is used for both the online Feature Store and the offline Feature Store. The latter is built on top of HopsFS. The development of RonDB is done by Hopsworks AB.
Prototypes have been built successfully where NDB was used to store disk blocks to implement a distributed block device.
The list of use cases where it is possible to build advanced data services on top of RonDB is long and will hopefully grow longer over the years in the future. One of the main reasons for this is that RonDB separates the data server functionality from the query server functionality.
Multi-dimensional scaling#
This includes the following points:
-
Scaling inside a thread
-
Scaling with many threads
-
Scaling with many nodes
-
Scaling with many MySQL Servers
-
Scaling with many clusters
-
Built-in Load balancing in NDB API (even in the presence of node failures)
RonDB has always been built for numerous levels of scaling. From the beginning, it scaled to several different nodes. The user can always scale by using many clusters (some of our users use this approach). Since MySQL Cluster 7.0 there has been a multithreaded data node, each successive new version after that has improved our support for multithreading in the data node and the API nodes. The MySQL Server scales to a significant number of threads. A data node together with a MySQL Server scales to use the largest dual socket x86 servers.
RonDB has designed a scalable architecture inside each thread that makes good use of the CPU resources inside a node. This architecture has the benefit that the more load the system gets, the more efficient it executes. Thus we get an automatic overload protection.
In the NDB API, we have an automatic load balancer built in. This load balancer will automatically pick the most suitable data node to perform the task specified by the application in the NDB API.
There is even load balancing performed inside a RonDB data node where the receive thread decides which LDM thread or query thread to send the request to.
Non-blocking 2PC transaction protocol#
RonDB uses a two-phase commit protocol. The research literature talks about this protocol as a blocking protocol because data nodes can be blocked waiting for a crashed transaction coordinator to decide on commit or abort.
RonDB’s variant of this protocol is non-blocking because it has a takeover protocol in the event of a crashed transaction coordinator/node. The state of the transaction coordinator is rebuilt in the new transaction coordinator by asking the transaction participants about the state of all ongoing transactions. We use this takeover protocol to decide on either abort or commit for each transaction that belonged to the crashed node. Thus there is no need to wait for the crashed node to come back.
The protocol is recursive such that the transaction coordinator role can handle multiple node failures until the entire cluster fails.
Thus there are no blocking states in our two-phase commit protocol. Normally a node failure is handled within less than 1-2 seconds unless large transactions were ongoing at crash time.
More on RonDB’s two-phase commit protocol can be found here.
Global checkpoints#
RonDB uses a method called Network Durable transactions. This means that when a transaction is acknowledged towards the API we know that the transaction is safe on several computers. It is however not yet safe on durable media (e.g. hard drive, SSD, NVMe or persistent memory). Avoiding persisting directly to durable media is a very important optimization to achieve very low latency and high throughput.
RonDB must however also be capable of recovering from a cluster crash. To ensure that we recover a transaction consistent point after a cluster crash, we write global checkpoints to disk every 1-2 seconds. They are created in a non-blocking manner so that we can continue to execute transactions while the global checkpoint is created. When we recover after a complete cluster crash we recover to one of these checkpoints.
The NDB API provides the global checkpoint identifier of the transaction committed, which makes it possible to wait for the corresponding checkpoint to be durable on disk if this is necessary. This identifier is heavily used in our recovery protocols and is therefore a very important building block of RonDB.
Note: Our global checkpoints also contain so-called micro global checkpoints. These are created every epoch (10 milliseconds) and are used for asynchronous replication between clusters. The micro global checkpoints are not durable on disk.
More on the Global Checkpoints Protocol can be found here.
Automatically parallelized and distributed queries#
Any range scan that is scanning more than one partition will be automatically parallelized. As an example, we have 4 range scans in the Sysbench OLTP benchmark. Using data nodes with 8 partitions per table will execute those scan queries twice as fast, compared to tables with only one partition. This is a case without any filtering in the data nodes. With filtering the improvement will be bigger.
In MySQL Cluster 7.2 a method to execute complex SQL queries was added. This method uses a framework where a multi-table join can be sent as one query to the data nodes. The manner it executes is that it reads one table at a time, each table reads a set of rows and sends the data of these rows back to the API node. At the same time, it sends key information onwards to the second table together with information sent in the original request. This query execution is automatically parallelized in the data nodes.
There is still a bottleneck in that only one thread in the MySQL Server will be used to process the query results. Queries where lots of filtering are pushed to the data nodes can be highly parallelized.
There are several limitations to this support, the EXPLAIN command in MySQL will give a good idea about what will be used and some reasons why the pushdown of the joins to the data nodes doesn’t work (pushing down joins to data nodes enables the query to be automatically parallelized).
Interestingly the MySQL Server can divide a large join into several parts where one part is pushed to the data node and another part is executed from the MySQL Server using normal single-table reads.