Setting up Active-Active replication between RonDB Clusters#
In this chapter we will go through how to set up replication between two clusters that can both be actively handling writes to the cluster. To handle this properly we need to setup also conflict detection which is explained in later chapters.
However Active-Active replication setup is also required to be able to handle a graceful change of roles of the Active and the Passive clusters. This is something that most Active-Passive cluster setups will be using as well.
The ability to switch the roles of the clusters is very useful, it could be used to perform any type of major maintenance work on the Active cluster. It can also be used as a way to demonstrate that the failover procedures used at cluster failover is working. Major maintenance work could be to change the application software, changing the RonDB software version, to change the schema used by the application software.
Being able to handle those changes on a cluster that is not online makes it possible to handle very complex hardware and software changes without getting any downtime of the cluster.
Active-Passive setup changes#
The setup of Active-Active replication always starts with setting up the Active-Passive replication between two clusters as described in the previous chapter. Thus to get to Active-Active replication we always start with only one Active cluster and then we perform the actions to move the replication into an Active-Active replication.
There is one difference in the setup though, the MySQL replication servers should be configured with the log-replica-updates variable set to ON. This ensures that the writes of the replica cluster is written into the binlog of the replica cluster.
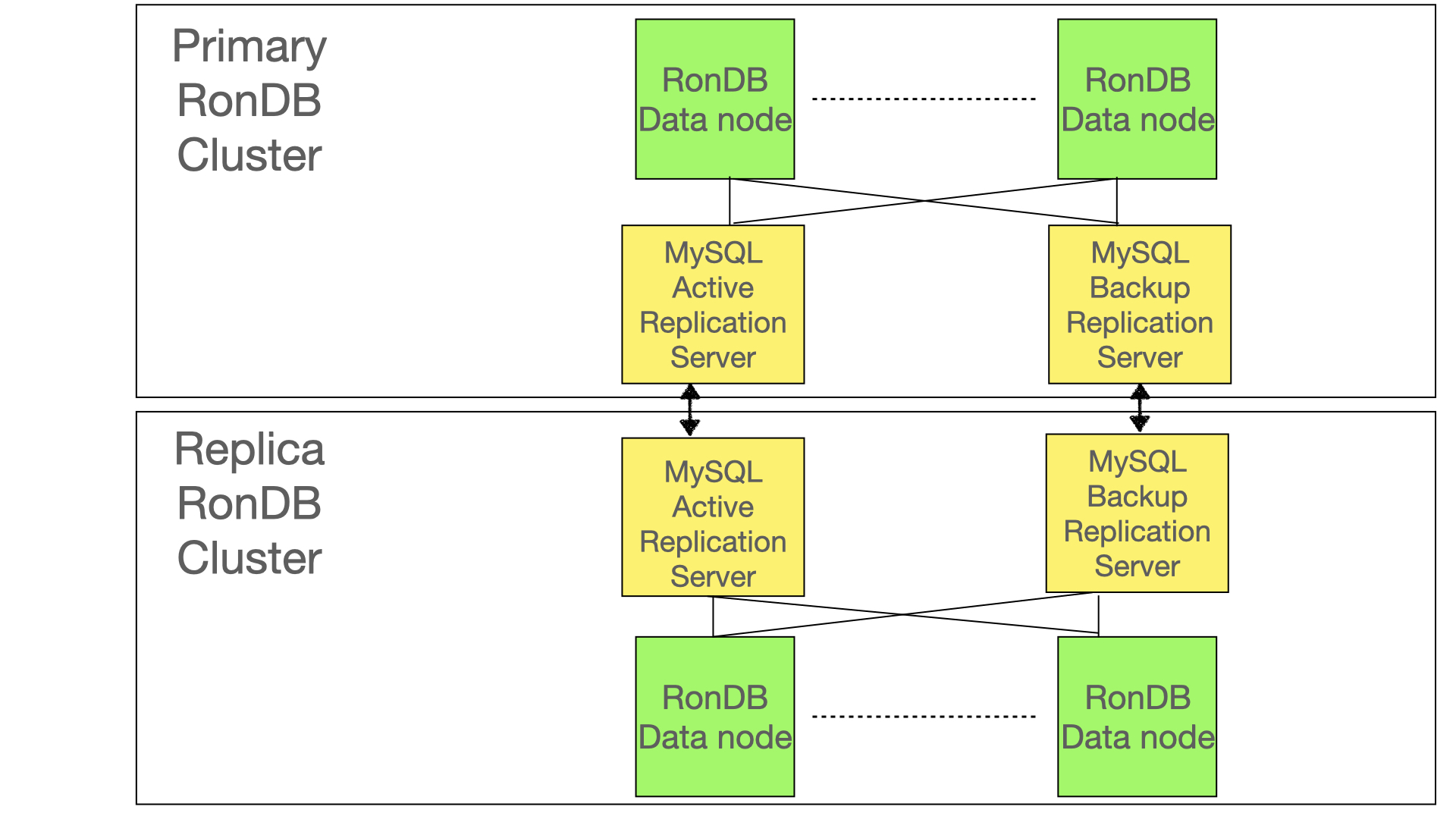
In the Active-Passive setup we started replicating from the primary cluster to the replica cluster. The next step to setup Active-Active replication is to also start replicating from replica cluster towards the primary cluster. This can only happen if we set the log-replica-updates configuration variable to ON in the replica cluster. It should also be set in the primary cluster to ensure that we can switch roles of the clusters later.
Now as usual to start replication it is the cluster receiving the replication records that need to setup the source of the replication. In this case it is the MySQL replication servers in the primary cluster that needs this setup.
To start replicating from the replica cluster to the primary cluster we need to get an epoch number to start from, this epoch number needs to be converted into a binlog position to ensure that we can start the replication from a proper position.
This is using the same procedure as in the Active-Passive setup. Thus the primary MySQL replication server in the primary cluster should issue the following the queries towards to the MySQL replication server in the replica cluster. As usual we always use replication channels. Thus it is the MySQL Active Replication server VM in the Primary RonDB cluster that sends these queries towards the MySQL Active Replication server in the Replica RonDB cluster. Using those queries it will discover the binlog position to setup the replication.
Thus the following queries should be executed.
This retrieves the current epoch in the replica cluster, assuming the server ids are 11 and 12 for the MySQL replication servers in the primary cluster.
The epoch number LAST_EPOCH is then fed into this query:
SELECT SUBSTRING_INDEX(next_file, '/', -1) AS file,
next_position AS position
FROM mysql.ndb_binlog_index
WHERE epoch <= LAST_EPOCH
ORDER BY DESC LIMIT 1;
This query is executed in the replica cluster and provides the starting binlog position. Now the FILE and POSITION from this query is used in the query to setup the replication source in the MySQL replication server in the primary cluster.
FILE=$(cat TMP_FILE | awk '(NR>1)' | awk -F "\t" 'print $1)')
POSITION=$(cat TMP_FILE | awk '(NR>1)' | awk -F "\t" 'print $2)')
CHANGE REPLICATION SOURCE TO
SOURCE_LOG_FILE='$FILE',
SOURCE_LOG_POS=$POSITION,
IGNORE_SERVER_IDS=(11,12);
Now we are ready to start replicating from the replica cluster to the primary cluster.
Now that the replication is set up between replica cluster and the primary cluster all the changes to the cluster in the primary cluster will be replicated to the replica cluster. These changes will generate binlog records that are used to replicate back to the primary cluster. Here we will discover that the originating server id is our own server id. Thus we will ignore these binlog records and this breaks the circular replication loop.
However to ensure that a channel failover doesn’t cause the replication records to continue we can set another variable in the command to setup replication source. So we will actually set IGNORE_SERVER_IDS to 11 and 12 to ensure that we ignore replication records from both MySQL replication servers in the primary cluster.
Result of setting up Active-Active replication#
At this point we have setup the replication channel from the replica cluster towards the primary cluster. Exactly the same principle is used for replication channel failover as described in the Active-Passive chapter.
Graceful switch of Active role#
At this point the primary cluster is the only Active cluster, but we are now in a position to easily switch roles between the clusters. This requires no conflict detection handling.
At first the application must be stopped from writing to the Active cluster. The application must be temporarily stopped. Now we need to wait for all replication records from the primary cluster to reach the replica cluster.
When the replication records are in the replica cluster and all writes have been applied in the replica cluster then we simply steer the application towards the replica cluster and updates can start again. Thus this procedure requires a small downtime, but it should be possible to get it down to less than a minute and possibly down to a few seconds.
After this change the roles of the cluster are swapped and things continue as normal.
If the aim was to perform major maintenance work in the primary cluster, then this cluster should be stopped after replicating all updates to the replica cluster. Before starting up the updates towards the replica cluster (now primary cluster) one should ensure that the replication to the old primary cluster have been stopped.
Starting up the old primary cluster again follows the same procedure using backup and restore as described in the previous chapter on Active-Passive replication.
More advanced replication configurations#
The descriptions works also with more advanced configurations. One such example is a circular replication between clusters in Europe, America and one in Asia. These clusters would be Active-Passive-Passive and after following the above procedures can be brought to a state of Active-Active-Active. As usual to actually use real Active-Active-Active one has to also handle conflict detection.