REDO Log & Global Checkpoint Protocol#

RonDB optimizes for low-latency applications where hard drive writes during the commit process are infeasible. It achieves the D (Durability) in ACID (Atomicity, Consistency, Isolation, Durability) through Network Durability. During a transaction commit, the data is committed in memory across multiple machines, so that all reads after this commit will see the new data. This ensures resilience against multiple node failures, but not against a complete cluster failure.
To ensure transaction durability on persistent storage mediums, RonDB writes REDO logs to disk within the Global Checkpoint Protocol in an asynchronous fashion. The protocol is a means of making the REDO log transaction consistent.
Protocol#
RonDB flushes its transaction records to disk every 1-2 seconds using the REDO log. However, in the event of a cluster failure, we need a transaction consistent point to recover from. This is achieved by the Global Checkpoint Protocol (GCP). This protocol is a way of labeling the transaction records in the REDO log with a global checkpoint identifier (GCI) and making sure that we have always flushed all transactions up to a certain GCI to disk. Each GCP is therefore a consistent recoverable point at a cluster crash.
In the following, we will describe in detail how the GCP protocol works, whereby the below figure shows its general architecture. The protocol runs between the data nodes’ DBDIH blocks (every data node runs a single DBDIH block). The master data node / DBDIH block is the oldest data node living and it is this node that initiates the protocol.
The DBDIH is also the block that contains the GCI. Whenever a transaction coordinator (TC) decides to commit a transaction, it will ask its local DBDIH for the GCI and pass it to the participants via the commit message. Read more about the role of the TC in RonDB’s two-phase commit protocol here.
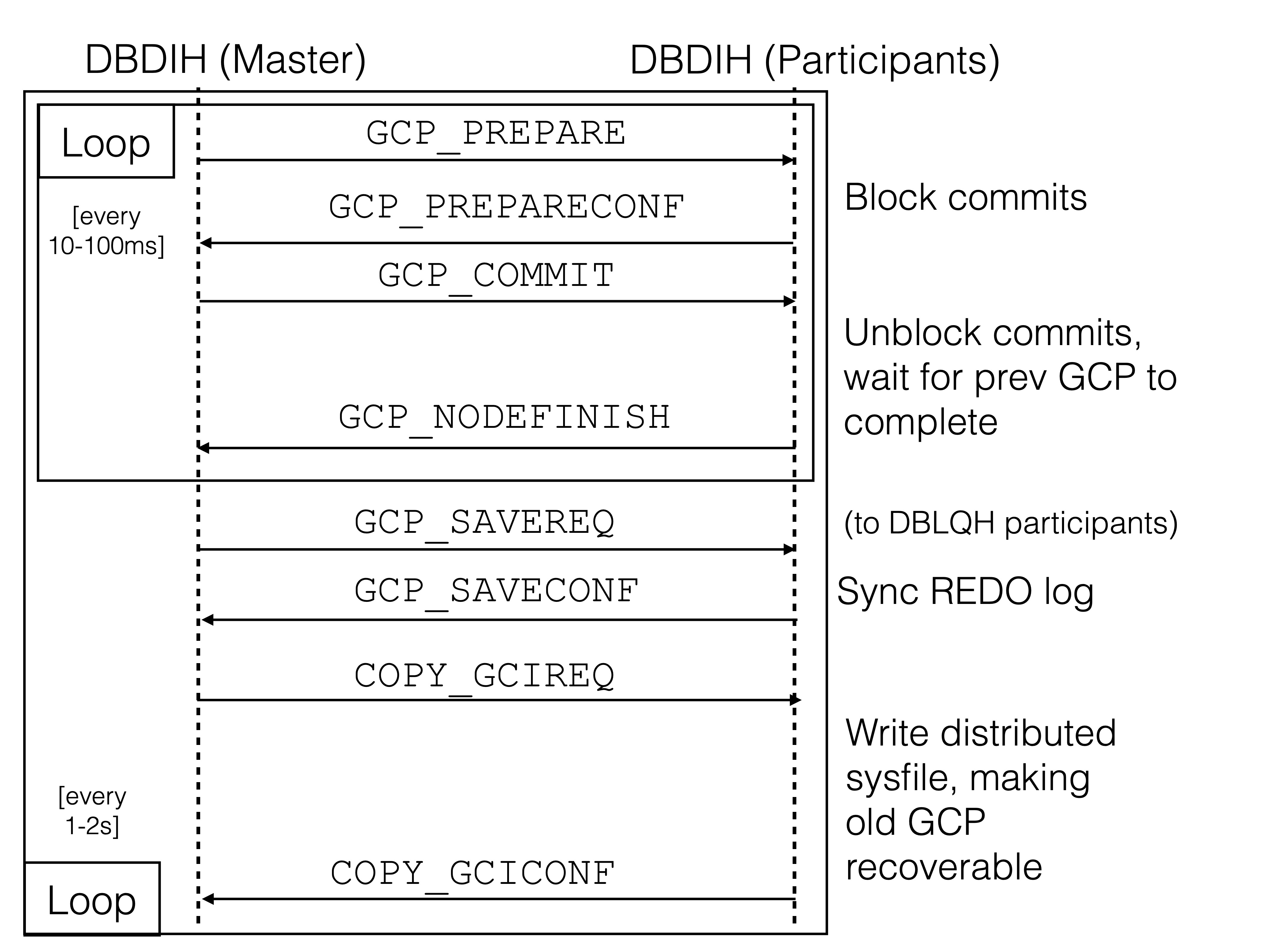
First Phase of Global Checkpoint Protocol#
The first part of the protocol is run every 10-100ms, a so-called epoch.
First, the master data node decides to create a new global checkpoint.
It sends a message called GCP_PREPARE to all data nodes in the cluster
(including itself). At reception of the GCP_PREPARE message, the
DBDIHs will queue TCs from receiving their GCIs. This means that new
commit messages can briefly not be sent out. The nodes then respond to
the master DBDIH with GCP_PREPARECONF.
Generally, this blocking of commits will only affect performance minimally, since it gives prepare messages a larger proportion of the CPU resources. Furthermore, the resulting queue of commits allow a sort of batch commit that improves throughput after the commit-block is released.
Next, the master data node sends GCP_COMMIT to all nodes. At reception
of GCP_COMMIT the DBDIHs will bump the GCI, and release the queue of
TCs waiting for the GCI. New commits can now be sent out again. The
DBDIHs then respond to the master DBDIH with GCP_NODEFINISH.
The reason why this part of the protocol is run so frequently is because we distinguish between micro GCPs and persistent GCPs. A GCI consists of a low and a high number. Only when the master data node decides to bump the high number, will we move into the second part of the protocol into order to create a persistent GCP.
The micro GCPs are used for Global Replication, so that a backup cluster can receive a consistent set of transactions more frequently.
Due to this two-phased approach where we briefly block our TCs from committing, we are certain that we get a proper serialisation point between the global checkpoints. This is a requirement in order to recover a consistent database state from a GCP. After 15 years of operation of the cluster we still have had no issues with this phase of the Global Checkpoint Protocol.
Second phase of Global Checkpoint Protocol#
The second phase makes the completed GCP durable on disk. It is usually run every 1-2 seconds, but can be further reduced or increased. The trade-off lies between the frequency of disk flushes and the volume of data potentially lost during a crash.
The first step is that each node needs to wait until the transaction coordinators have completed the processing of all transactions belonging to the completed GCI. Normally this is fast, but large transactions can slow it down. Especially transactions changing many rows with disk columns can represent a challenge here.
When all transactions in the GCP in the node are completed we will
send the message GCP_NODEFINISH back to the master data node.
When all nodes have finished the commit phase of the Global Checkpoint
Protocol the next phase is to flush the REDO logs in all nodes. The
message GCP_SAVEREQ is sent to all nodes to ask them to flush the REDO
log up to the GCI. The REDO log implementation will then flush all
transactions until the last one containing this GCI.
It is perfectly possible that some log records belonging to the next GCI are flushed to disk as part of this. There is no serial order of GCIs in one specific REDO log. This is not a problem, since we know at recovery which GCI we are recovering from and will skip any log records with a higher GCI.
When the flush of the REDO logs is complete the nodes respond with
GCP_SAVECONF.
At this point there is enough information to recover this GCI. To
simplify the recovery we use one more phase where we write a small
system file that contains the recoverable GCI. This is accomplished by
sending COPY_GCIREQ to all nodes. These will then write a special file
called P0.sysfile containing the GCI. It is written in a safe manner
in two places to ensure that it is always available at recovery. Writing
this file allows us to start up without needing to scan all REDO logs
for the GCI to recover.
When the file is written the nodes will respond with COPY_GCICONF. The
GCP is now completed and recoverable.