Stream with high availability#
In this tutorial, we will be handling the case where the replication channel fails. We will be using two replication channels: a primary channel and a standby channel. In contrast to binlog servers, one can only have one active replica applier running at a time. This means that one can also only have one active replication channel.
Our standby channel will be ready to take over replication if the primary channel fails. This means that we need two MySQL Servers in the primary cluster and two MySQL Servers in the replica cluster:
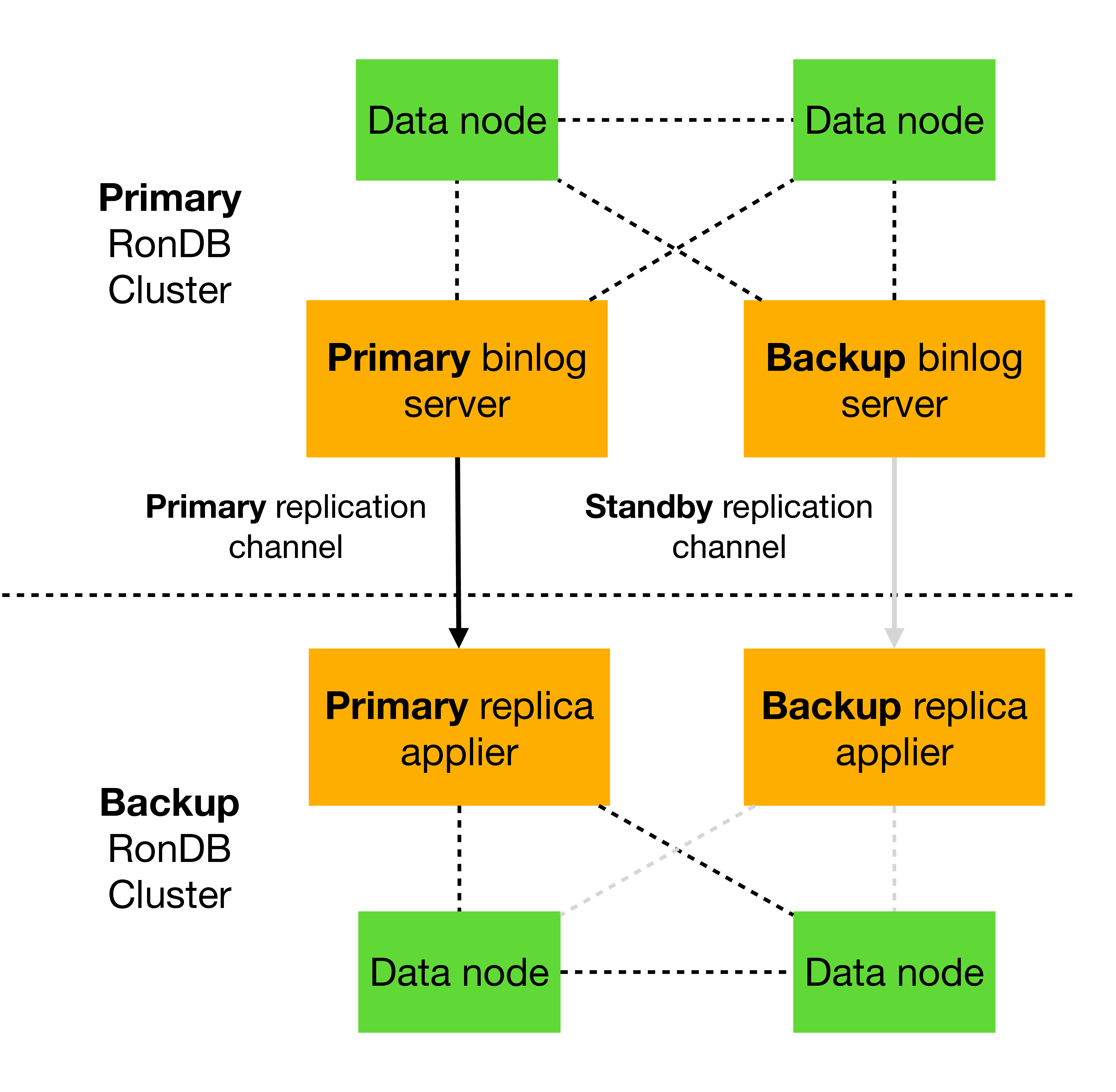
The image above shows how the setup of the MySQL Servers is done. There are two sets of MySQL servers. Each set implements one replication channel. If any of the MySQL Servers in the channel fails, we will cutover to the other replication channel.
When switching between replication channels, we will refer to it as a cutover. This stands in contrast to a failover, which is the process of switching between active clusters.
Scoping the problem#
Previously, we discussed how Global Replication can be reasoned about in terms of responsibility and failure zones. Once again, this can be visualized as follows:
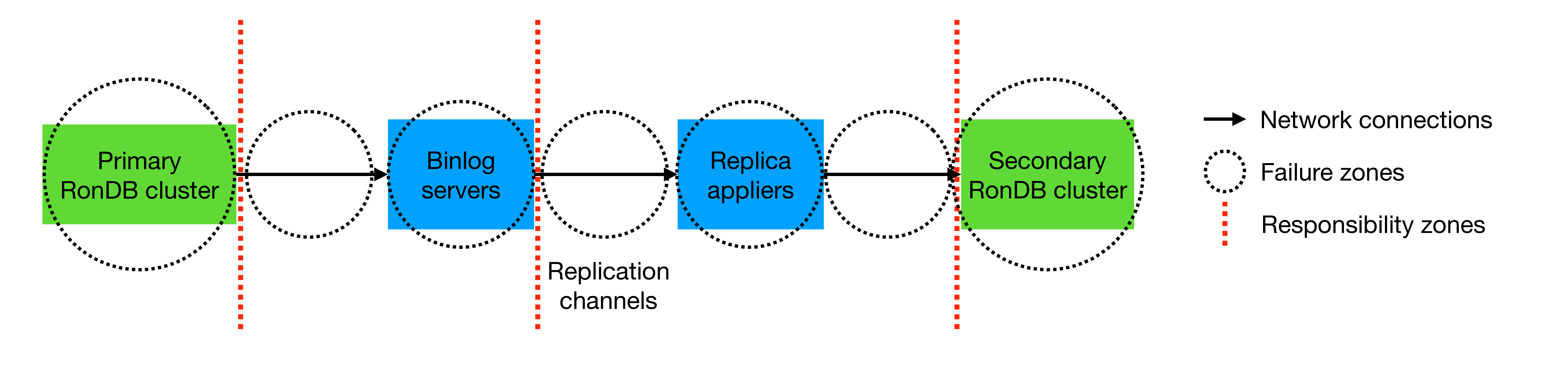
Since global replication is a pipeline from primary to secondary cluster, any element in this pipeline can cause the replication channel to fail:
-
the primary cluster
-
the network between the primary cluster and binlog server
-
the binlog server
-
the network between the binlog server and the replica applier
-
the replica applier
-
the network between the replica applier and the secondary cluster
-
the secondary cluster
Here, however, we will only be taking the perspective of the responsibility zone of the replica appliers. This means that we will monitor the replication channel and trigger cutovers, but assume any failure in the primary cluster, the binlog server, or the secondary cluster will be handled by other entities.
Preparing for monitoring#
Whether the replication channel is working can be seen in the ndb_apply_status table. This table is updated each time an epoch is applied in the replica cluster. There is one entry in this table for each MySQL replication server in the replica cluster. By default, however, epochs are only applied if a transaction has occurred in the primary cluster.
Using the MySQL configuration parameter ndb-log-empty-epochs=ON, one
can also replicate empty epochs, but this is not recommended. Epochs
happen at intervals of around 100 milliseconds and can be even smaller
than this. Therefore, this can lead to unnecessary replication traffic.
For this purpose, we use the table heartbeat_table in the database heartbeat_db as discussed in a previous tutorial. We will assume the binlog servers of the primary cluster will update this table at regular intervals. By doing so, we can regularly expect changes in the ndb_apply_status table. This gives us another method to monitor the replication channel.
Preparing standby channel#
As shown previously, when starting a replica applier, we use the flag
--skip-replica-start. This means that the MySQL Server will not start
replicating until the START REPLICA command is issued. This is useful
because it means that we can have an idle standby replica applier, ready
to take over immediately if the primary replica applier fails. When
doing so, one can already have the base configurations set up:
CHANGE REPLICATION SOURCE TO
SOURCE_HOST='source_host',
SOURCE_PORT=3306,
SOURCE_USER='repl_user',
SOURCE_PASSWORD='repl_password',
IGNORE_SERVER_IDS=(202,203);
Note that this will still be missing SOURCE_LOG_FILE and
SOURCE_LOG_POS.
Monitoring the replication channel#
The following are methods to monitor the replication channel. One can initiate a cutover process between replication channels if any of the following conditions are met:
-
The primary MySQL Server process has stopped or is not responding
-
Applied epochs have stopped increasing
One can regularly run this on the primary replica applier:
If the value of this has changed in the replica cluster since the last call we know that we are making progress. If the value is the same we have made no progress. The time interval of running this command should be related to the time interval we update the heartbeat_table. However, another factor that may lead to stalling epochs is large transactions. This should also be taken into account before reporting a failure.
-
MySQL
REPLICA STATUSis stoppedIf we discover that no epochs are applied in the backup cluster we can check the status of the replica applier by issuing the command
SHOW REPLICA STATUSin the replica MySQL Server. This can provide extensive status details on the replication channel, including on whether the replica applier has stopped.
Cutover process#
The first step is to ensure that the primary replica applier is stopped.
Normally one can simply use the STOP REPLICA command. If the replica
MySQL Server doesn’t respond, we can kill the replica MySQL Server
process. It can be detrimental to have multiple active replica
appliers running at the same time.
After ensuring that the primary replica applier has stopped, we can perform the same steps as in the previous tutorial to restart the replica applier. Note that the binlog positions between binlog servers are not synchronized. Thus the binlog position of the primary replication channel is unrelated to the binlog position of the backup replication channel. Once these steps have been performed, the backup replication channel has been promoted to the primary replication channel.
A cutover process can be performed multiple times. This is visualized in the following figure:
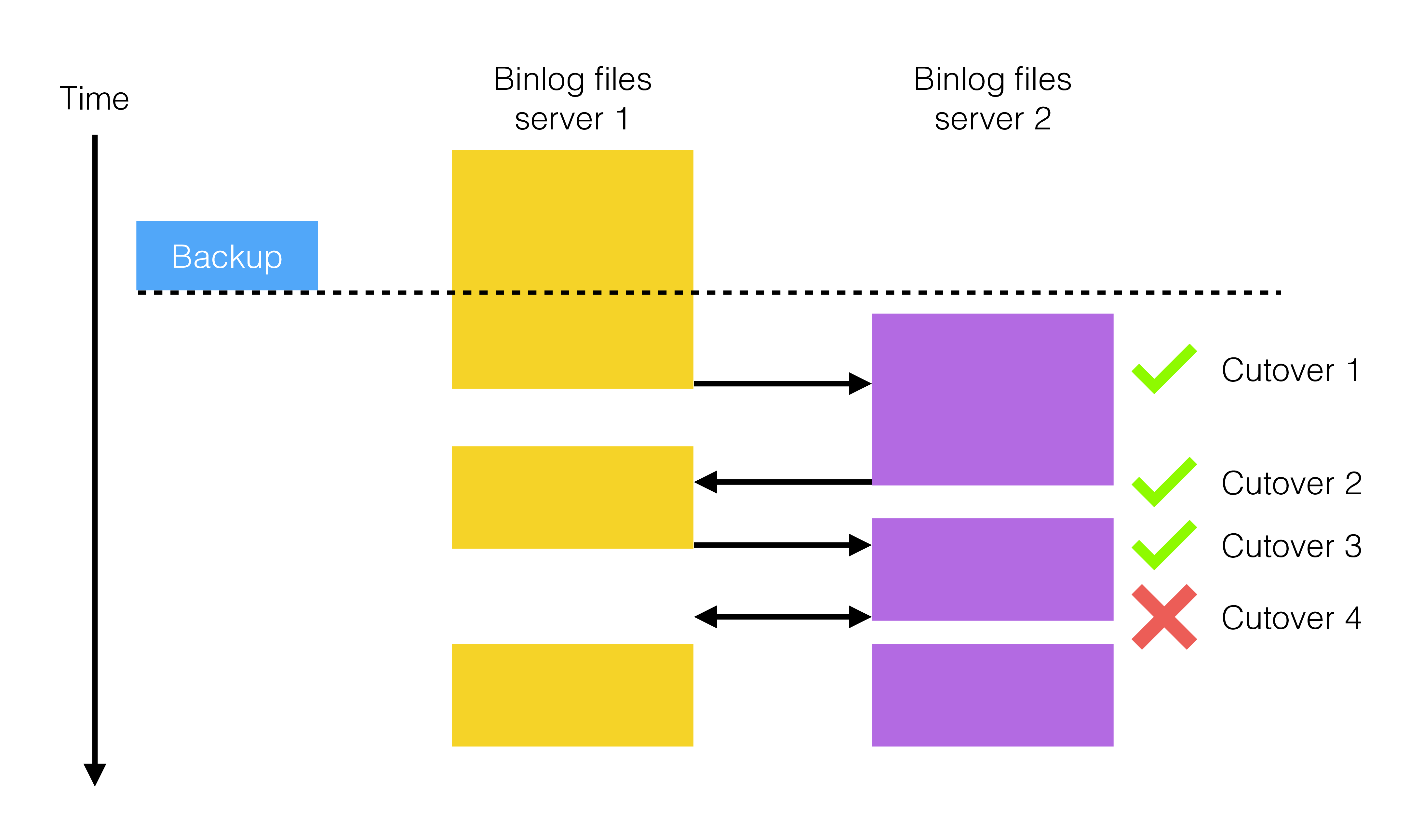
As described in the section GAP
events, the active replication
channel will stop if a GAP event is encountered in the binlog.
Therefore, the cutover process can be initiated until a GAP event is
encountered in all binlog servers.
Note that in the described case of failure, querying
mysql.ndb_binlog_index on both binlog servers will most
likely return an empty result.
If a cutover process has failed (after some retries), it will be necessary to perform actions on a "global" scale, i.e. in all responsibility zones. If the root failure lies in the responsibility zone of the binlog servers, it is highly likely that the following actions will be required:
-
(optional) restart the binlog servers from scratch
-
take a backup in the primary cluster
-
restart the secondary cluster from the backup
-
recalibrate the replica appliers to check the backup’s epoch