Prepare primary cluster#
In this tutorial, we will discuss how to prepare a primary cluster to replicate its changes to a secondary cluster. We will not spin up the secondary cluster yet.
We will discuss how both starting and operating a cluster will need to be altered. The regular startup and operation of a cluster are described in the chapters Local quickstart and Operating a cluster.
Starting a cluster#
The main difference to starting a standard cluster, is that we now also start MySQL replication servers. In the case of the primary cluster, these will be the binlog servers.
When replicating from a primary cluster, all data in the primary cluster must be available either as:
-
a backup of the primary cluster
-
binlog files in the MySQL replication servers of the primary cluster
-
a mixture of both; in this case, the backup is a condensed version of data to which the binlog is appended
Therefore, the primary binlog server must be started either:
-
before data is written to the cluster (restoring a backup does not count)
-
before a backup is taken
A backup binlog server on the other hand can also be started at a later point in time, assuming that the primary has not lost any binlog data. As mentioned in the section GAP events, any missing data in the binlog files of the primary binlog server will cause the replication channel to stop.
When setting up multiple binlog servers, each will attempt to persist
all binlog files since its startup. This makes it acceptable for a
given GAP event to occur in one binlog server, as long as it is not
present in all binlog servers. Therefore, we will be setting up two
MySQL replication servers in the primary cluster. In this example, we
will be using server_id=100 for the primary binlog server and
server_id=101 for the backup binlog server:
| Primary binlog server | Backup binlog server |
|---|---|
|
|
If one is interested in applying active-active replication with only
two clusters in total in the upcoming tutorials, one can also apply
the parameter log-replica-updates=OFF. In active-active, the primary
cluster will also contain replica appliers. Using this parameter, the
binlog servers will not write the replica applier’s changes into the
binlog. This will save disk space and I/O resources on the binlog
servers.
These and further configuration parameters are also listed here.
Confirm binlog is active#
To check if the binlog is active, one can use the following command in the MySQL Server:
This will return either ON or OFF.
If the binlog was not active, one can still add a MySQL replication
server using the --log-bin option. However, since one is missing the
previous binlog files, one must then run a backup of the cluster.
Heartbeat table (optional)#
The replication is only active when something is written to the database. To ensure that there is always activity, we create a custom heartbeat_table that we define in the primary cluster. All writes to the table will be replicated to replica clusters. This can be a simple table that looks as follows:
CREATE DATABASE heartbeat_db;
CREATE TABLE heartbeat_db.heartbeat_table (
server_id INT NOT NULL PRIMARY KEY,
counter BIGINT NOT NULL
) engine NDB;
Here, every entity hosting a MySQL replication server can run a
user-defined script to continuously insert and update a row
corresponding to the MySQL server’s server_id. We then use a counter
increment on each write to ensure that the row changes and thus is
replicated on the other side:
| Primary binlog server | Backup binlog server |
|---|---|
|
|
This will also require a corresponding MySQL user with the necessary privileges to be created on the primary cluster.
Purging MySQL binlog files#
MySQL Replication binlog files have a user-defined size. After completing the write of one binlog file, the file is closed and a new one is written. Restarting the MySQL Server will also cause a new binlog file to be created.
Binlog files will either be purged by the DBA using the command:
or using the MySQL configuration parameter binlog_expire_logs_seconds.
Since the size of total written binlog files over a given time period is
indeterministic, it is however important to implement a strategy for
purging binlog files. As long as one is not replicating to a secondary
cluster, this strategy can be as simple as regularly running:
-
create backup
-
purge all binlog files that are contained in the backup
We will show how to implement this strategy, but beware of changing it when setting up a replication channel. This is because replication will fail if binlog files are purged before they are replicated.
Identify purgeable binlog files#
When creating a backup, one wants to know which epochs were contained in it and therefore which binlog files can be purged. Here, there are two solutions:
-
(Simple but inaccurate) Check the current binlog file before triggering a backup
For this solution, one runs this command on the binlog server before triggering a backup:
> SHOW MASTER STATUS; +---------------+----------+--------------+------------------+-------------------+ | File | Position | Binlog_Do_DB | Binlog_Ignore_DB | Executed_Gtid_Set | +---------------+----------+--------------+------------------+-------------------+ | binlog.000001 | 5847 | | | | +---------------+----------+--------------+------------------+-------------------+ 1 row in set (0.00 sec)Depending on how much time passes between this command and the start of the backup, the binlog may have moved beyond
binlog.000001. Hence, this solution can be inaccurate. -
(Complex but accurate) Extract epoch number from backup
When running the backup command via the
ndb_mgmclient, the command output will contain theStopGCPnumber. This can be used to calculate the epoch number of the backup.In the example below the
StopGCPis 3845:ndb_mgm> START BACKUP Waiting for completed, this may take several minutes Node 2: Backup 1 started from node 1 Node 2: Backup 1 started from node 1 completed StartGCP: 3839 StopGCP: 3845 #Records: 193234 #LogRecords: 12349 Data: 20519789 bytes Log: 1334560 bytesA 64-bit epoch number can then be formed as follows:
This epoch number is the last epoch number that was backed up. Using this, one can now identify which binlog files can be purged. This can be done by querying the ndb_binlog_index table in the primary cluster:
-
(Next tutorial) Extract epoch number from secondary cluster after restoring backup
-
(Next tutorial) Extract replicated epoch number from secondary cluster without restoring backup
In all cases, we store the result in the shell variable BINLOG_FILE.
Now, all binlog files before this one can be deleted. We run:
Handling data gaps#
Whenever a data gap occurs in the binlog, one should trigger a backup. The following scenarios can cause a data gap in the primary cluster:
-
All binlog servers contain a given
GAPeventThis can best be mitigated by placing the binlog servers into different data centers or availability zones.
-
All binlog servers run out of disk space
This can be mitigated by adding a new binlog server before the other binlog servers run out of disk space. One could set a maximum threshold for the total binlog size to grow before triggering a backup and scaling down again. However, if we are not replicating to a secondary cluster, we will regularly hit this limit.
-
All binlog servers die
Generally, it is safer to place the binlogs on block storage and persist them across binlog server restarts. However, if all binlog servers die, this would not help.
Let’s assume we have detected a data gap and triggered a backup. The backup has now finished. Even if we have a secondary cluster running that is dependent on our binlogs, we can now safely purge the binlog files without checking how far the secondary cluster has replicated. This is because the secondary cluster will have to be restarted using the backup in any case. The next section will explain which binlog files can be purged.
Persisting binlog files#
In a primary cluster with a single binlog server, a binlog server that has failed will highly likely have data gaps from the time it was down. Since a replication channel that hits a gap will automatically stop, the binlog server will soon become useless. This outcome would be unaffected by whether the binlog files had been persisted across the binlog server restart. Thereby, persisting the binlog files would not be very effective.
The situation changes however if one has multiple binlog servers in the primary cluster. This is shown in the figure below:
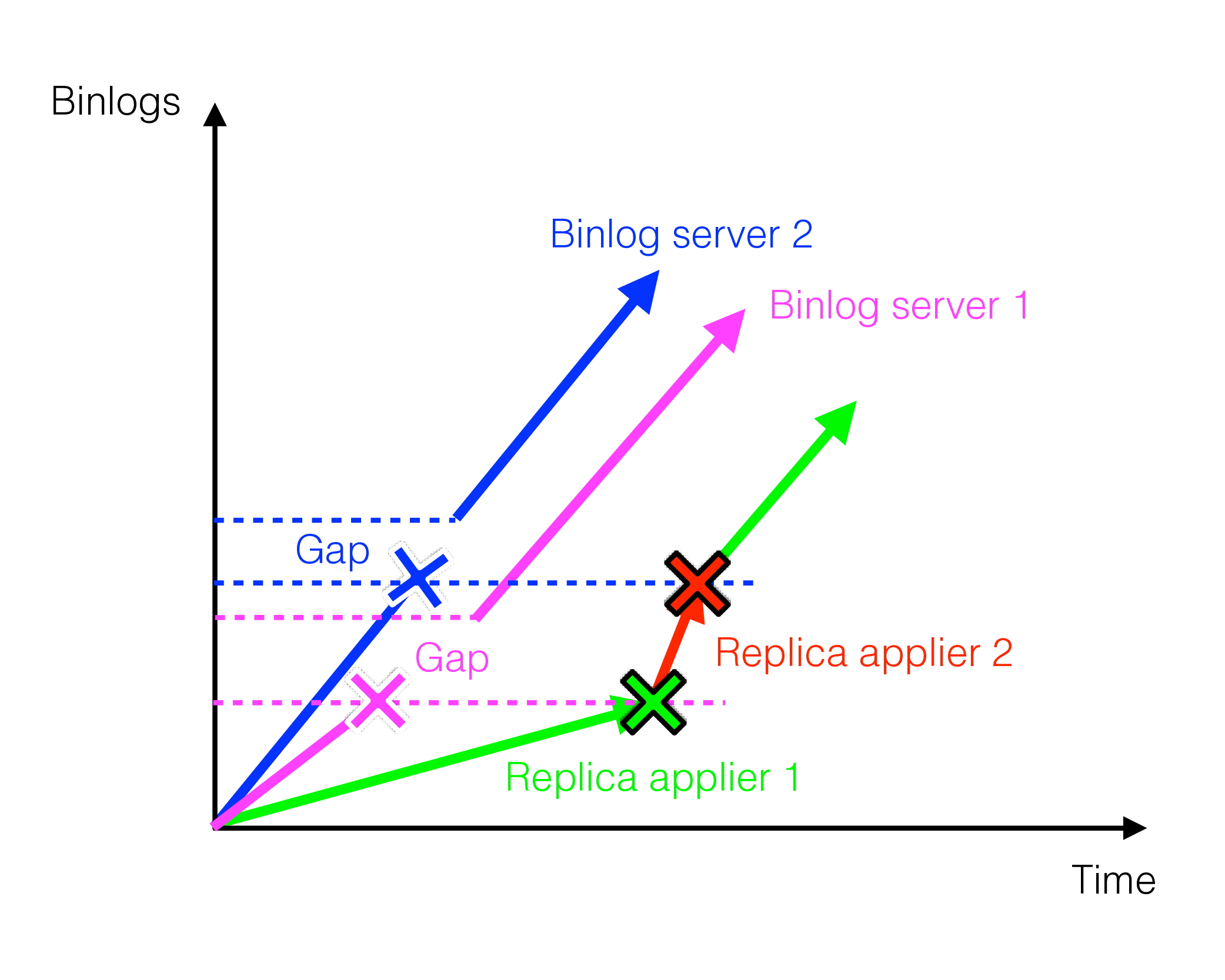
Here, we first have an active replication channel between binlog server 1 and replica applier 1. Then, binlog server 1 fails, so the replication channel switches and starts running between binlog server 2 and replica applier 2.
Importantly, binlog server 2 had failed earlier to this switch but had persisted its binlog files across its restart. This was vital because these persisted files contained the data gap produced by binlog server 1’s failure. This gap had still not replicated to the replica cluster. By keeping the previous binlog files, binlog server 2 enabled the global replication setup to survive.
Note that when persisting binlog files, one should also persist the
ndb_binlog_index table. This table is local to every MySQL
server. By default, it will be stored in the MySQL datadir.
If the binlog directory is persisted, but the datadir is not, the binlog
files will not be useable.