Global Replication in RonDB#

RonDB is designed for Local Area Network (LAN) environments. It is possible to have nodes a few kilometers away from each other and still get a good user experience as is the case within a cloud region.
There are several reasons to make use of multiple clusters that contain the same data. Each cluster uses synchronous replication between nodes in the cluster. Global Replication uses asynchronous replication between the clusters.
A few reasons to use Global Replication are:
-
Surviving natural disasters
The application must be able to survive earthquakes and other drastic problems that can impact a large area, including local conflicts and disruptions that affect larger areas than a LAN or cloud region covers.
For the highest availability, it is of utmost importance to have availability beyond what a single cluster can provide.
This is the reason many of the high-profile users of NDB use Global Replication. A telecom operator cannot accept that the phone service or mobile internet service is disrupted completely by one catastrophic event. The application has to be built to handle such catastrophic events.
-
Supporting advanced cluster changes
The application needs 100% uptime in all types of software upgrades. Many applications upgrade not only the DBMS when upgrading, they might decide to upgrade their application and they might even decide to move one data center from one place to another. A fail-over cluster can be very useful in all of those cases.
RonDB is designed to handle most software changes without downtime. But there are still some things we don’t support that might be needed such as an online drop column. In this case, another cluster can be used to perform an online upgrade. Next, the clusters are swapped and the first cluster is brought online. At last, the second cluster can be brought down to upgrade that as well.
-
Low latencies for global applications
Global Replication can be used to build a true globally distributed database where updates can be performed in any cluster anywhere in the world. Given the latency between systems on a global scale, it is not possible to wait for commits until all clusters have accepted the transaction. Instead, we use a conflict detection scheme. RonDB supports several different conflict detection schemes.
The globally distributed database setup can be used in companies that operate over multiple continents and need a cluster on each continent that can act as a primary cluster.
Even with a single primary cluster, one can use conflict detection to ensure that failover to a new primary cluster can be done without downtime. In this case, the conflicts only occur in the short time that two clusters are both primary clusters.
-
Replication to a different storage engine of MySQL
We will not cover this explicitly here. It should however be straightforward to do with the descriptions in this chapter.
Global Replication can be used for most applications using RonDB. The exception is applications requiring many hundreds of thousands of write operations per second. Those cases are still possible to handle but will require setting up parallel replication channels for each database as described in later chapters.
MySQL Replication#
The asynchronous replication between clusters is built on top of MySQL Replication. It reuses most of the basic things about MySQL Replication such as a binlog, a relay log, source MySQL Servers and replica MySQL Servers. There is a set of differences as well.
First of all, RonDB only supports row-based replication. The meta data changes are replicated using statements, but all data changes are replicated using row changes.
The row changes are not generated in the MySQL Server (remember that RonDB can be accessed also from NDB API applications), rather they are generated inside the data nodes. The data node generates events for row changes and transports them to a specific MySQL Server that handles replication between clusters.
RonDB uses a concept called epochs to transport changes over to the backup cluster. Epochs are a sort of group commit, they group all changes to the cluster committed in the last period (100 milliseconds by default) into one epoch. This epoch is transported to the backup cluster and applied there as one transaction.
MySQL using InnoDB relies on GTIDs to handle replication consistency. RonDB gets its replication consistency from its use of epochs.
In research papers about database replication, there are two main themes on how to replicate. One is the epoch style, which requires only sending over the epochs and applying them to the backup cluster. The actual replication is simpler in this case. The problem with this approach is that one needs to create epochs, this puts a burden on the primary cluster. In RonDB this isn’t a problem since we already have an architecture to generate epochs efficiently through our global checkpoint protocol. Thus using epochs is a natural choice for RonDB.
The other approach has a smaller impact on the source, it instead requires that one keep track of the read and write sets and ensures that the replica applier has access to this information. This is a natural architecture for a DBMS where it is harder to change the transaction architecture to create epochs.
Both architectures have merits and disadvantages. For RonDB, epochs was a very natural choice. For MySQL using InnoDB the approach using GTIDs to serially order transactions (still lacks the read sets) was the more natural approach.
Global Replication supports more features compared to MySQL Replication. The features we support in this area are very advanced. The lead developer in this area took his Ph.D in this area about 20 years ago and presented a distributed replication architecture at the VLDB conference in Rome more than 23 years ago.
This is an area that we have developed in close cooperation with our telecom users. These all require this feature and have built a lot of support functionality around it.
Architecture of Global Replication#
As a first step, we will describe the nodes required to set up replication between clusters. Given that almost all applications of RonDB are high-availability applications, we will only consider setups that have a primary and a backup replication channel. The replication channel will be set up between two RonDB Clusters.
A replication channel connects a source and a replica MySQL Server. Thus having a primary and backup replication channel means that we need at least two source and two replica MySQL Servers.
In active-active architectures, replication goes in both directions. This can be accomplished with the same set of MySQL Servers or it can be accomplished with additional MySQL Servers. There is no difference in this choice. Thus active-active replication can be achieved with four or eight MySQL Servers for two RonDB Clusters. Circular replication (more than two active clusters) however requires four MySQL Servers per RonDB Cluster.
In the optimal design, the MySQL Servers used for replication are only used for replication and schema changes.
Base architecture#
The base architecture is replicating from one RonDB cluster to another RonDB cluster. Here we have a set of data nodes, "normal" MySQL Servers and replication MySQL Servers in each cluster. The following diagram shows the setup.
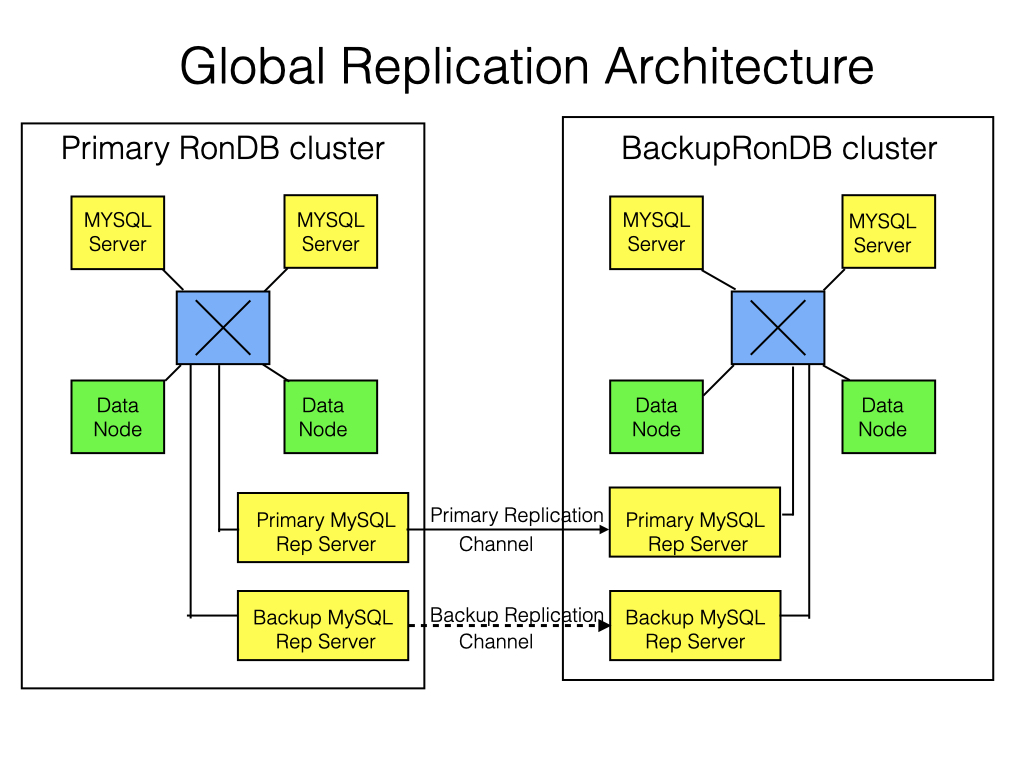
The two replication MySQL Servers in the backup cluster receive events from the primary cluster and store these in their binlog. However, only one of them applies the events to the cluster. The events are sent by one of the MySQL Replication Servers in the primary cluster.
Failover between the primary replication MySQL Server happens on epoch boundaries. Thus if one replication channel fails, the other can deduce which epoch has been applied and start from the next epoch after that.
If the primary cluster fails or if both replication channels fail, we will fail over to the backup cluster. Using epochs this is straightforward. We discover which is the last epoch we received in its entirety and continue from there. The application must also be redirected toward the new primary cluster before the failover is completed.
Active-Standby Clusters#
Active-standby clusters are the most basic configuration used primarily for high availability, complex software upgrades, hardware upgrades and so forth. No conflict detection is required since there is only one active cluster at a time.
Read-Replica Clusters#
In this case, there is no failover handling. The replication is done to increase read throughput. We could have more than one backup cluster.
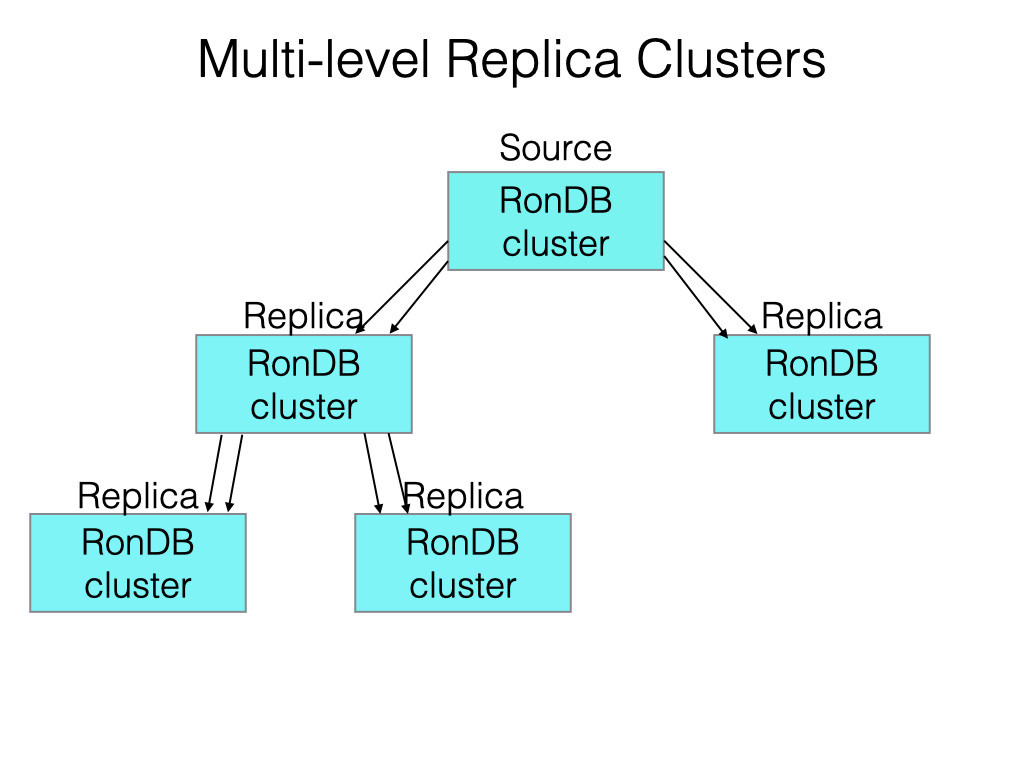
Multi-level Read-Replica Clusters#
With high throughput of writes it can be hard for one primary cluster to replicate to all other backup clusters. In this case, one might have multiple levels of replication.
Thus the primary cluster replicates to a set of clusters, each of those clusters in its turn can replicate onto another set of RonDB Clusters.
Active-Active Clusters#
Active-active clusters replicate in both directions. This means that we can get conflicts. Thus it is important to decide how to handle those conflicts, we will go through the options available in the chapter on globally distributed databases using RonDB and in the chapter on extremely available solutions with RonDB.
A special case of this architecture is when we normally run in Active-Standby mode, but during the failover we run in Active-Active mode. To support this is one of the reasons we support conflict detection in the Active-Active setup.
Circular Active-Active Clusters#
With more than two active clusters, the replication becomes circular. This still requires conflict detection handling. We will cover this in the chapter on globally distributed databases.
Point-in-Time backups#
Normally the second cluster is used for fail-over cases. However, one can also use it to have a continuous backup of the primary cluster. In this case, the second cluster does not need to be able to handle the same read load as the primary cluster. It only needs to be able to handle the update load.