Extremely Available Solutions#
Using RonDB in a single cluster solution it is possible to get 99.999% availability. There are some complex software upgrades and configuration changes and cluster crashes that could cause downtime.
Now using the failover mechanism from one cluster to another as presented in an earlier chapter here brings the availability up to 99.9999%. Thus only 30 seconds downtime per year.
One remaining reason for downtime is switching over from one cluster to another. This can happen in complex software and hardware upgrade situations. In this situation the application might be in read-only mode for a short time while switching over write activity from one cluster to another.
For most users this 99.9999% availability is sufficient. But for a few users even the downtime for a switchover from one cluster to another is desirable to remove. One such case could be a network operator that provides services that might have to restart ongoing connections if the database is not available for updates for a while.
Such an operator might operate one cluster on the west coast of the US, another cluster is operated on the east coast.
Now in normal operation the west coast cluster handle the customers that are currently in the west and the east coast cluster handles customers in the east.
Now assume that the west coast cluster has to be brought down for some kind of management activity such as hardware upgrade, software upgrade, complex configuration changes.
In the case of a normal setup with an operating cluster and a standby cluster ready to fail over to, there would be a short read-only mode affecting customers in the west in this case.
To handle this type of switchovers RonDB supports a conflict detection mechanism that enables this type of management operation to complete without any downtime at all.
The problem in this case is that it is hard to switch over all application nodes at the same time to start using the east coast cluster. The routing of application requests is a distributed decision made in many different nodes at the same time, it is hard to change these decisions all at exactly the same time.
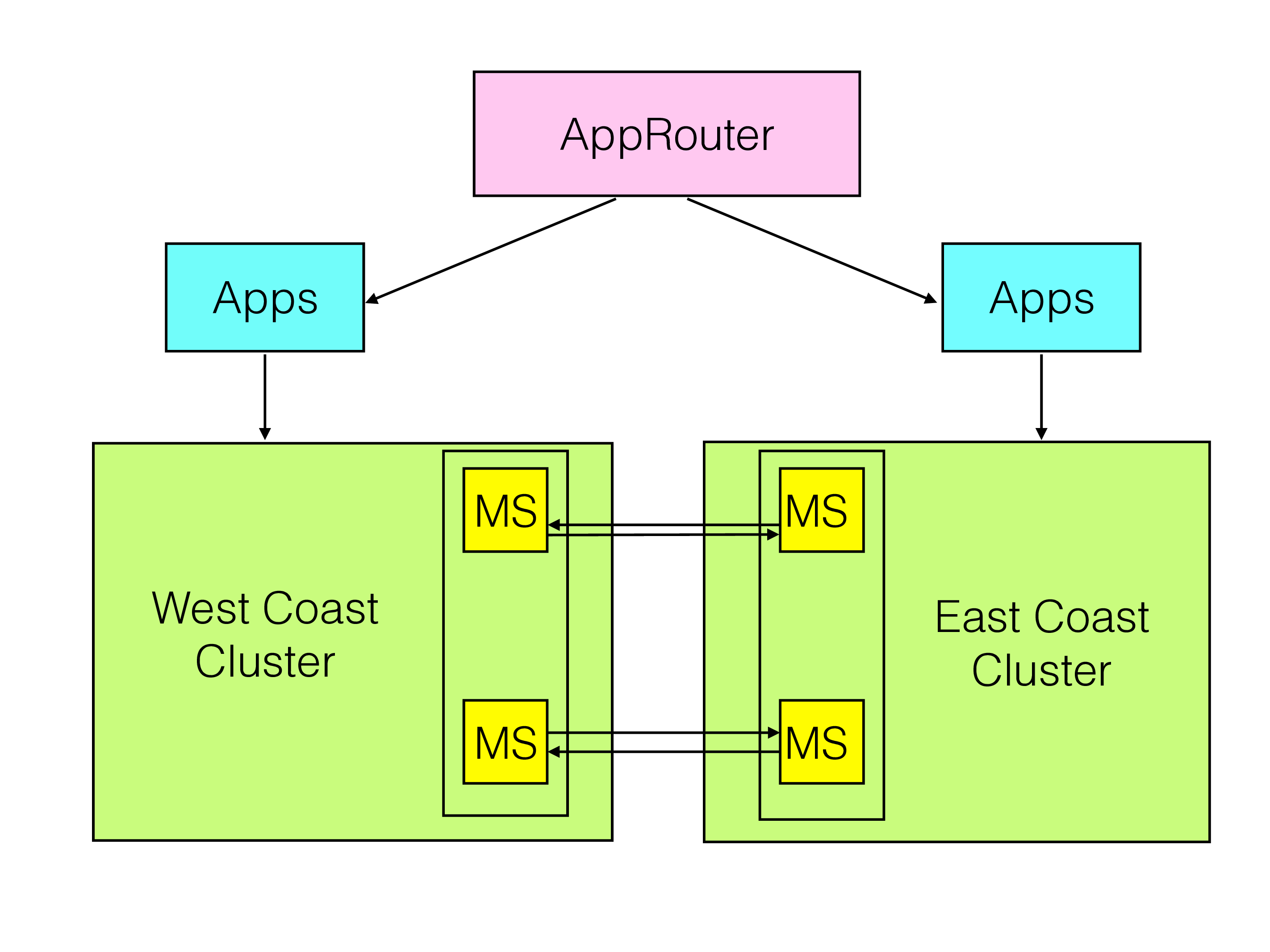
In order to solve this we must accomodate for updates to arrive from both the west coast cluster and from the east coast cluster at the same time, operating on the same data.
Thus conflicts can occur. In this case we want to have a much stricter consistency. We operate normally in strong consistency mode. We want to continue operating in this mode even when updates can go to any of the two US clusters.
This means that any conflicts must roll back entire transactions that are in conflict. We need to use reflecting replication events to implement the conflict resolution. In addition we want to also protect important reads by ensuring that we log in the binlog also events about reading a row with an exclusive lock. In effect this is implemented such that those reads perform an update of a hidden column.
Now the number of conflicts generated in a setup like this during switch over to a new cluster can be substantial. Thus we don’t expect this conflict detection mechanism to be used to support a generic update anywhere solution.
The idea is that the conflicts are generated in a short period where the switch over is executed. As soon as the switch over have completed, the resolution of the conflicts can quickly complete and the remaining east coast cluster is fully operational and accepting updates from all US users without any risk of conflicts.
Setting up transaction-based conflict detection#
It is set up exactly the same way as NDB$EPOCH2 except that this conflict detection function is called NDB$EPOCH2_TRANS. We need to set two more MySQL server options ndb-log-transaction-id and ndb-log-exclusive-reads. We need to define exception tables as explained in the previous chapter and insert rows in the ndb_replication table to define the replication setup.
It is also necessary to set the ndb_replica_conflict_role systems variable as shown below.
ndb-log-transaction-id#
In order to use the conflict detection function NDB$EPOCH2_TRANS it is necessary to set the option ndb-log-transaction-id in all MySQL replication servers used as binlog servers. With this option set the binlog server will insert a transaction id for each entry in the binlog. This enables tracking which updates that were updated in the same transaction.
ndb-log-exclusive-reads#
To ensure that we can also discover reads of conflicting data we have introduced the ability to log exclusive reads of records in the binlog. This is a useful feature for conflict detection that relies on transactions for conflict discovery.
To achieve a fully consistent handling of transactions it is required to cover not only write-write dependencies between transactions, it is also required to cover read-write dependencies. To ensure that a dependency is inserted into the binlog a read must be performed using an exclusive lock.
ndb-replica-conflict-role#
The role of a primary cluster is very important for both NDB$EPOCH2 and NDB$EPOCH2_TRANS. This role is under control of the user through the MySQL system variable ndb_replica_conflict_role. Setting this to PRIMARY in all MySQL replication servers in a cluster makes this the primary cluster. All other clusters should set this variable to SECONDARY instead in all MySQL replication servers.
Now an important scenario we can operate here is that before any switch over is required the setting of this variable is set to PASS. PASS means that we don’t look for conflicts, we apply the log records in the replica applier as they arrive.
Thus this setting is very similar to a normal fail over setting with two clusters that are operational.
Now if we want to shut down the west coast cluser, we start by stopping the replica appliers in both the west and the east coast cluster. Next we set the ndb-replica-conflict-role to NONE, immediately followed by setting it to SECONDARY. Next we do the same thing in east although here we set it to PRIMARY role instead.
Finally we startup the replicas again.
Example startup of MySQL replication server#
Here is an example of the startup of a MySQL Server that is both handling the binlog server part and the replica part for one of the cluster using the NDB$EPOCH2_TRANS function.
mysqld --log-bin=mysql-bin
--ndb-log-bin=1
--skip-replica-start
--server-id=1
--binlog-cache-size=1M
--ndb-log-update-as-write=OFF
--ndb-log-orig=ON
--log-replica-updates=ON
--ndb-log-apply-status=ON
--ndb-log-transaction-id=ON
--ndb-log-exclusive-reads=ON
--ndb-log-empty-update=ON
--ndb-log-update-as-minimal=ON
Characteristics of this solution#
The only supported configuration of this is when there are two clusters, one is PRIMARY and the other is the SECONDARY cluster. All updates in the PRIMARY cluster will succeed, all updates in the SECONDARY cluster will be checked by the replica applier in the PRIMARY cluster. If a conflict occurs it will be logged in the exceptions table.
In addition the conflict resolution is automatically started by ensuring that all rows involved in the transaction is restored to the value in the primary cluster. This is implemented by a special replication event performing a reflecting operation.
As long as write operations continue to come into both clusters we can still get new conflicts. We will start to heal the database immediately through reading the exceptions table and implementing the user decided conflict resolution.
Conflict handling#
Now we are prepared to handle conflicts. Now the application logic can ensure that the traffic is moved from the west coast cluster to the east coast cluster. For a period the updates can go to any cluster and conflict detection will discover any problems with consistency.
When the switch over have completed and no more traffic goes toward the west coast cluster we need to wait for all conflict resolution tasks to complete. Once they complete we are ready to bring down the west coast cluster.
Bringing back the west coast cluster again after completing the management changes is done in the same fashion as bringing online any cluster, see the chapter on Global Failover architecture for this.
This variant maintains transactional consistency of our data. Thus any conflicting updates that are not accepted are rolled back in its entirety, not just the row that had a conflict, but the transaction as well.
The rollback is implemented through a reflecting replication event.
Thus we need a mechanism here to rewrite transactions. Every conflicting transactions that is rejected have to be handled using special code reading the conflict detection tables and deciding on how to handle the conflicts.
Any kind of such logic is beyond this book, it requires a detailed understanding of your application requirements and what the actual meaning of those conflicts means.
The function NDB$EPOCH2_TRANS is the conflict detection method used in this case. There is an older variant called NDB$EPOCH_TRANS that have the same flaw as the NDB$EPOCH around delete operations, so it should be sufficient to focus on NDB$EPOCH2_TRANS.
The conflict detection is the same as for NDB$EPOCH2 using epochs as timestamp.
Conflict handling is a lot more complex compared to the other conflict detection function.
More comments#
It is possible to use this mechanism also for cases where we have very small conflicts between the clusters, potentially could be used to handle network partitioning cases with smaller timespans.